[按键精灵][协议抓包]抓取某人微博的内容
优采云 发布时间: 2022-04-22 07:53大家好,今天讲一下爬取网页数据的教程,具体例子是爬取微博内容,我们先随便打开一个微博页面,如:
通常我会直接用url.get命令获取网页源码,然后从源码中提取我们需要的内容,但是我们这次的案例确实不能提取。
TracePrint url.get("https://weibo.com/u/6074356560")
运行此行代码提取的网页源码并不是网页上显示的内容,而是包含了部分javascript代码的,也就是页面内容还需js加载出来,这种情况我们就需要通过抓包来找到网页的内容。
我们来说一下具体的操作步骤:
①准备抓包工具,我选择使用浏览器自带的调试工具,打开浏览器按F12键就可以开启调试工具。
每个浏览器都有自己的调试工具,基本上功能和样式都差不多,大家有什么浏览器就用什么浏览器。
②设置好调试工具初始状态。
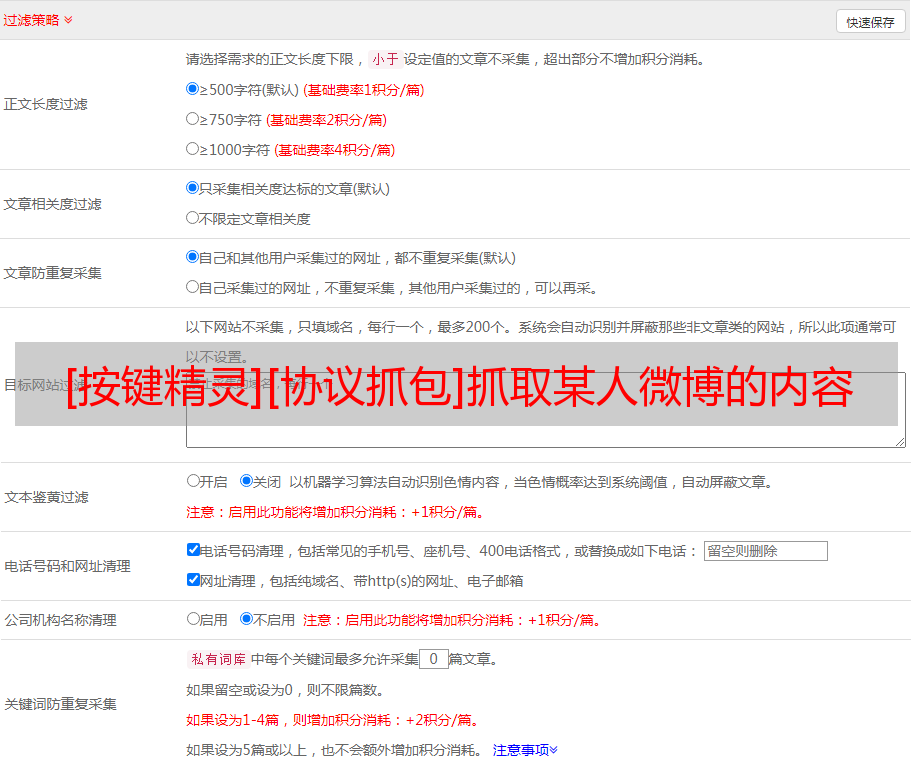
打开网络抓包(network),清空抓包列表的内容,具体操作看下图。
③开始抓包
在调试工具准备好后,刷新一下网页,让网页重新加载,会看到有数据包被抓取出来了。
④找到我们想要的数据包
抓取的数据很多,一条条找比较费劲,在左侧有一个搜索框,我们利用搜索功能,找到我们想要的内容,那么到底搜索什么内容呢?
每一个页面要搜索的内容都不一样,以我们今天这个获取微博内容为例,想要抓取的是微博内容,那么就选取页面微博内容中的一些关键词。
可以看到有一条搜索结果,这个就是我们想要抓取的部分,有的时候可能会有多条搜索结果。
⑤数据初步分析:
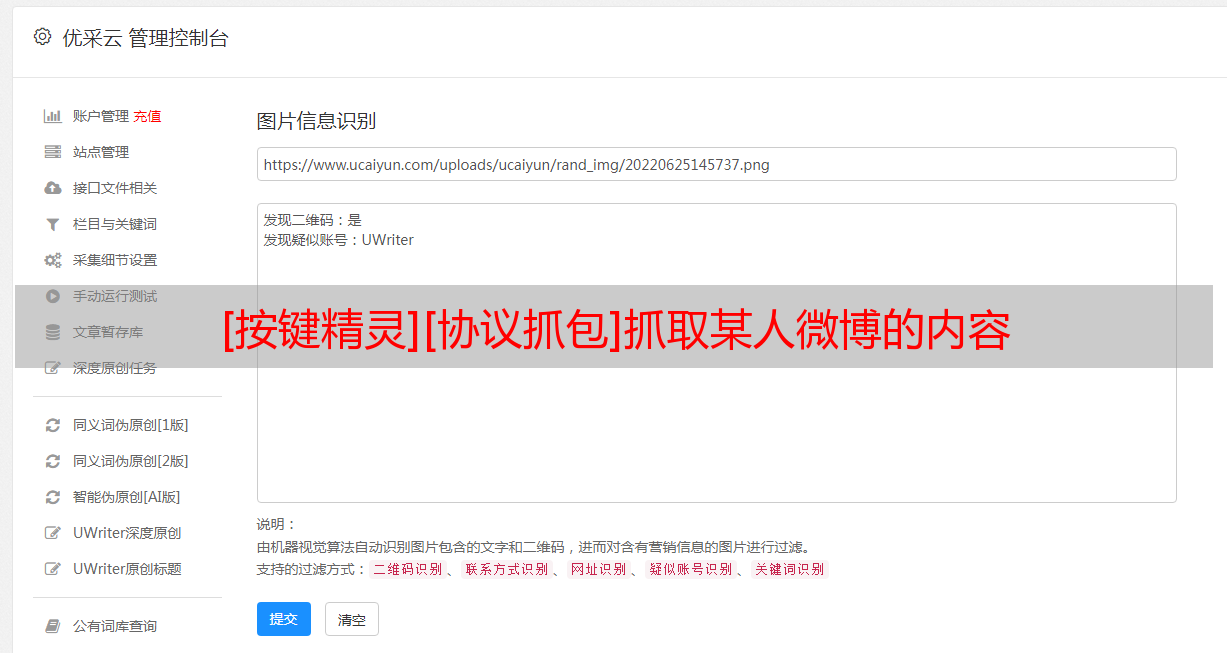
点开上一步的搜索结果,右侧出现这条协议的数据,我们这个例子是返回一个json数据。
一般我会把这个json数据复制出来,看看是不是包含全部想要的内容,这个我已经看过了,是我想要的。
⑥协议分析和提取。
点一下协议头,看看协议部分:
协议部分内容很长,只截取部分展示:
对于协议头这里,我会关注这么几个:
a. 请求url
b. 请求方式c. cookied. user-agente. 请求的参数
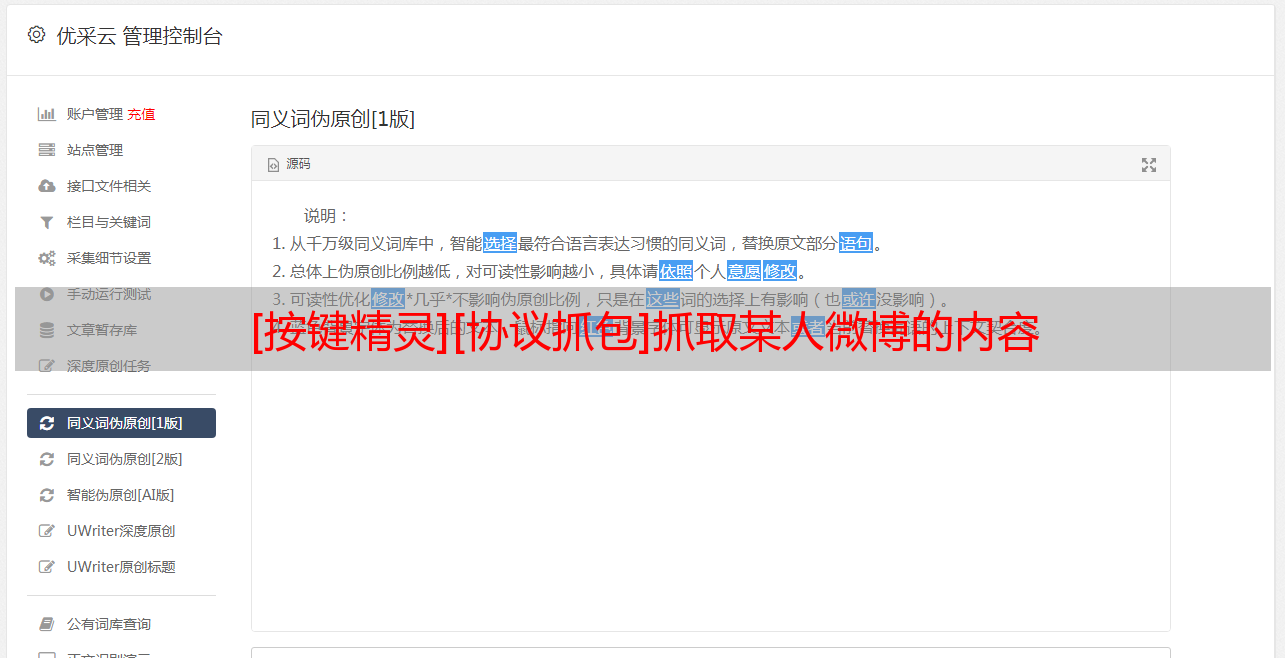
⑦把协议部分得到的内容,写到post或者get命令里面
Import "cjson.lua"Dim url1 = "https://weibo.com/ajax/statuses/mymblog?uid=6074356560&page=1&feature=0" Dim hader = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36" //协议头UADim cookie="SINAGLOBAL=9136586994469.588.1644929595244; SUB=_2AkMVfL5qf8NxqwFRmP0cxWvmbotzyQzEieKjIE-xJRMxHRl-yT_nqkEktRB6PvyQhZiuc5bq2rXhJxpLi8XsJokdU_pg; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WWgS4MF5LO004-Z0gge_VnZ; UOR=bbs.anjian.com,widget.weibo.com,bbs.anjian.com; XSRF-TOKEN=56GL5F3PPUReGiB1GUXowHgk; WBPSESS=lGn6cRy34B6AsqM-wzgd2KNi64TT4SnOOf25OUUOC6Y2tgCD1eBH7am3nSNjI_XiXHjlvpFQ0A6XVONSR-M5M9PehTm9-8ao2AL6ZCZIcHpHu3kokZgURr-p4WdGoAyu4ZrMspBEvySuZV2OmiptOWGd5QgGxhHCL09ovFrSBsY=; _s_tentry=weibo.com; Apache=3154924384350.295.1650201395939; ULV=1650201395947:7:2:1:3154924384350.295.1650201395939:1649471644818"Dim date1 = {"url":url1,"code":"utf-8", "cookie":cookie, "header":{"User-Agent":hader,"content-type":"application/json"}}Dim ret = Url.Httpget(date1)TracePrint retDim table=cjson.Decode(ret)TracePrint len(table["data"]["list"])For i = 1 To Len(table["data"]["list"]) TracePrint table["data"]["list"]["text"]Next
对于单独一个页面的抓取,以及脚本提取代码就这些,但是如果想要有一些通用性,就需要一些分析能力了。
比如:案例中的请求url
uid=6074356560&page=1&feature=0
在网址中有两个很重要的参数:
uid:微博个人id号参数
page:页码,显示第1页内容填1,显示第2页内容填2
在知道这两个参数以后,就可以做一些延展:
比如更换uid,获取不同人的微博内容。
递增page页码,可以遍历一个人的所有微博内容。
这一步就需要大家有分析能力,根据不同网址想到不同的功能。
本期就是一个最简单的网页抓包案例,想要系统学习去搜索一下tcp/ip协议,工具方面网页抓包还可以用fiddler,app抓包可以用小黄鸟(httpcanary)

