如何批量采集高质量好文章(2022年1月更新,最新版微信不能教你打造文章爬虫)
优采云 发布时间: 2022-04-17 08:01如何批量采集高质量好文章(2022年1月更新,最新版微信不能教你打造文章爬虫)
2022年1月更新,一定要注意最新版微信不能使用这个方法,可以安装微信低版本(3.4.0.54及更早版本可以) ,如果网上找不到安装包,可以私信给你。
本文是该主题的第三篇文章。如果你的基础不错,只要阅读本文的解释和源码,应该可以轻松批量下载所有文章。基础不好的可以先看前两篇。只要你有一些基础和一点耐心,至少80%的朋友可以按照葫芦画图实现批量下载文章的功能。
本系列总目录
开心:一步步教你搭建文章爬虫(1)-review
快乐:一步步教你创建微信公众号文章爬虫(2)-下载页面
开心:一步步教你搭建文章爬虫(3)-批量下载
快乐:一步步教你搭建文章爬虫(4)-FAQs
有朋友反映,前两篇有点啰嗦,所以这次换个风格,只讲重点。不懂就跟*敏*感*词*流。
在前面的文章中,我们得到了一个下载文章,接下来我们研究批量下载。
有的朋友可能会说:这不简单,一个for循环就可以搞定。但是批量下载是之前研究过这个项目的朋友最卡的地方。因为 for 并不难,难的是你正在循环的内容:所有 文章 列表在哪里?
打开电脑版微信,找到一个公众号的历史文章列表页面。
在 文章 列表中滑动鼠标,您将看到 文章 列表一直在加载。我们必须想办法提取这些列表。
看看下面的图片。正常情况下,电脑版微信向微信服务器发送请求,微信服务器将数据返回给电脑,然后显示。
我们可以在两者前面插入一个代理,也就是图中的Fiddler软件,这样就可以抓取微信服务器返回的信息。
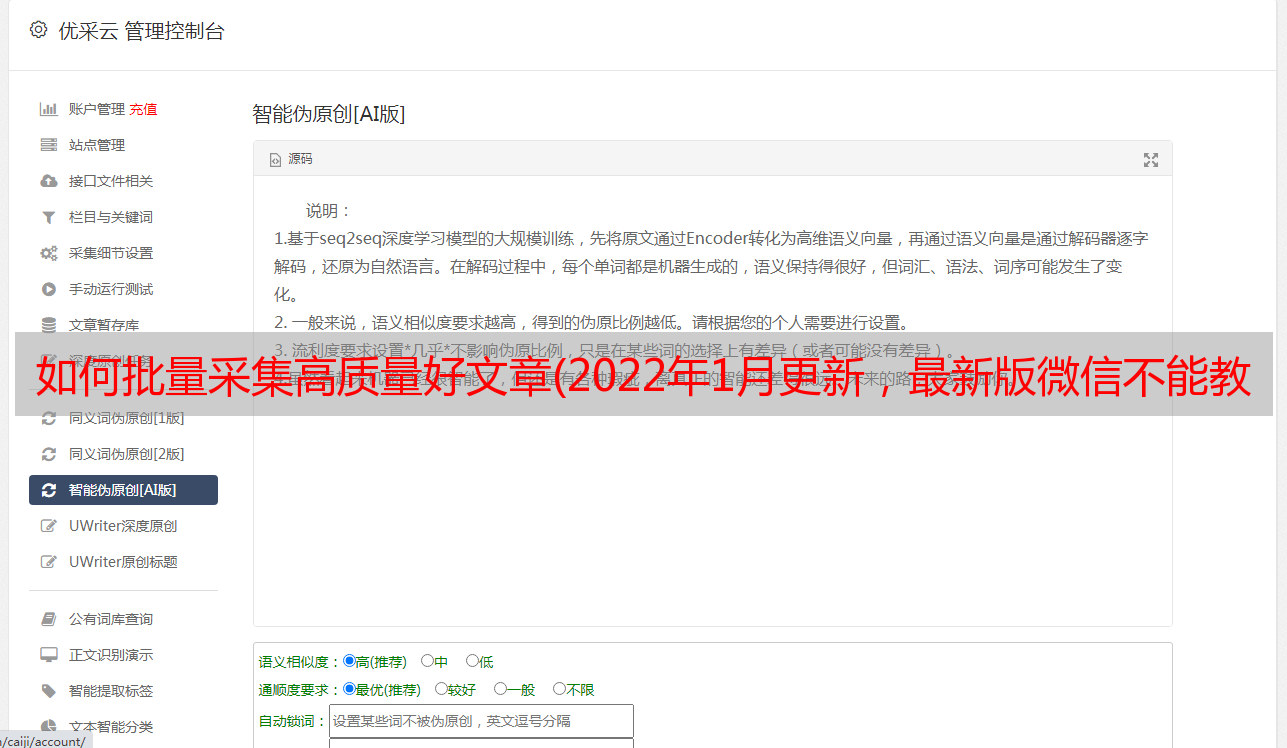
需要的工具叫做Fiddler,它的官网有时候打不开。可以搜索Fiddler4(或者到文末QQ群的分享),下载安装。然后,要让 Fiddler 正常工作,还需要做一些配置,可以按照我先说的做。建议在实际操作之前完整阅读本文。
提醒一下,Fiddler其实是一个系统代理软件,所以如果您在电脑上使用其他类型的代理软件,请先将其关闭,否则可能无法正常工作。
打开 Fiddler 并按照以下步骤操作。
会弹出几个窗口,点击是
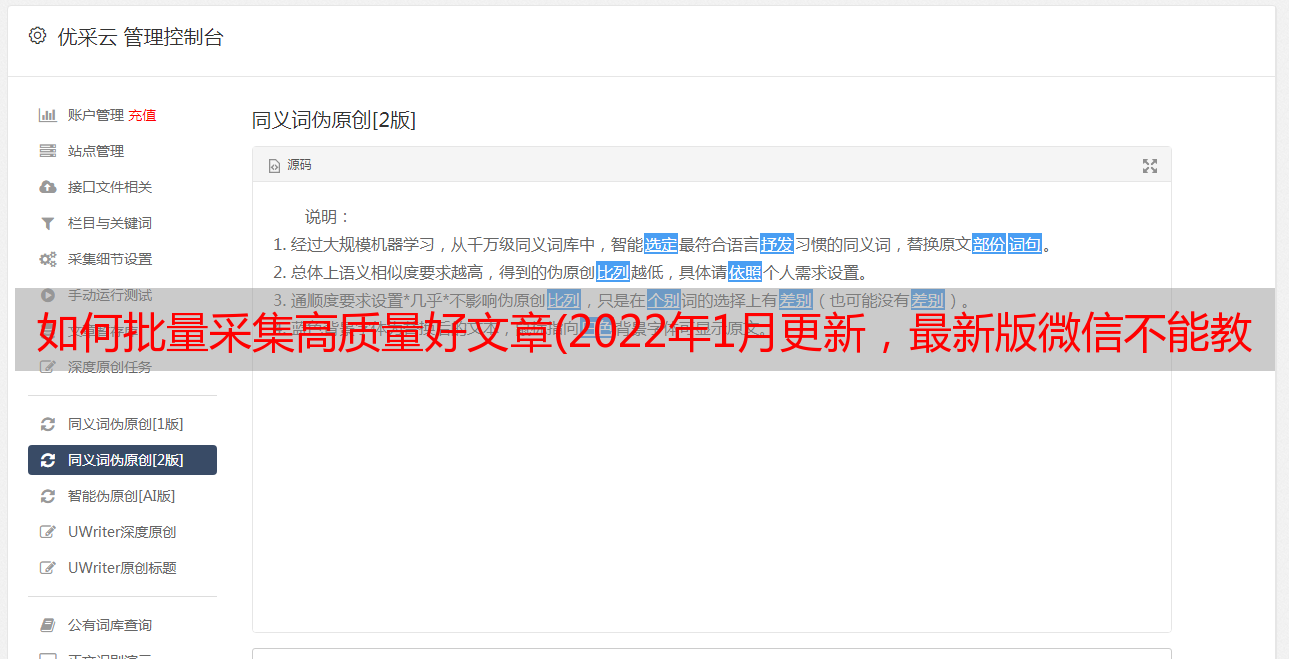
最后就是这个样子,有3个钩子。单击确定保存。
配置完成后,点击软件左下角的方框,会显示Capturing,表示此时处于可以抓取数据的状态。再次点击恢复空白,表示暂停捕获。
然后,在微信公众号的历史文章列表页面向下滑动,你会看到Fiddler的左侧窗口中滚动着一堆数据,和第一节提到的chrome开发者工具非常相似. 这两种功能基本相同,只是开发者工具只能检测chrome打开的网页,而Fiddler可以检测全电脑所有的Http和Https请求(这两种方式主要是抓取网页类型数据,其实电脑里还有其他类型的网络请求方式,比如微信聊天数据这种方式是无法获取的担心。)
单击一行,右侧会显示此请求的详细信息。它与 chrome 开发者工具的风格非常相似。Fiddler 的功能越来越强大。
再往下拉几次,加载更多文章,你会发现模式:
每出现一个新的文章,就会出现一个对下图红框所示的url的请求。
选择这个,右边选择JSON,你会看到一个格式化的JSON数据,仔细看general_msg_list,好像是返回的文章列表,为了确定,可以点击上面的Raw标签JSON的左边,见最后一行,是一个很长的json字符串,就是这样。
如果您采集每个请求的所有返回字符串,您将获得所有 文章 的列表。Fiddler 的强大之处在于它可以帮助我们以文本的形式保存捕获的消息。
那么,如果一个公众号有1000篇文章文章,需要多少次发送请求,多少次下拉才能列出所有的文章?只要你不是太笨,至少应该能想到一个笨办法:一直向下滚动 文章 列表,Fiddler 会抓取所有返回的数据。本着先求善后求善的原则,从简单到抽象,我们先做这个。其实在我开始批处理的第一段时间里,采集采集文章 当然,列表除了好用之外,还有其他的考虑。
在开始爬取之前,我们需要先做一些准备工作:Fiddler默认会抓取所有经过这台电脑的请求,不需要全部保存,最好过滤掉。那么我们需要的数据有哪些特点呢?仔细观察,我们感兴趣的数据的 URL 的前半部分是
一开始,我们让 Fiddler 只保留这样的 URL。
说到这里,很多有经验的朋友可能会觉得是时候介绍我用Fiddler写代码了,其实我们不需要!不懂python的朋友学习JScript语言有点压力。我们可以巧妙地利用 Fiddler 自身强大的过滤功能来做到这一点:
看下图,在Fiddler右侧,开启过滤功能,只显示url中指定关键字的请求,注意不要把https放在前面,填好后会自动保存。
向下滚动微信文章列表,Fiddler中只会显示我们想要的URL。
接下来,看看如何将上面列出的所有内容保存到您的计算机上。
首先在本地新建一个 C:\vWeChatFiles\rawlist 文件夹。
依次点击Fiddler左上角的File - Export Sessions - All Sessions,弹出一个对话框,选择Raw Files,点击Next,又是一个对话框,保存目录设置为我们刚刚创建的文件夹。
最后点击导出,软件会自动帮我们新建一个类似C:\vWeChatFiles\rawlist\Dump-0805-15-00-45的文件夹,里面收录几个json文件,如果你用记事本或者记事本++(强后者推荐)打开这些文件,你会看到这是标准的json格式,还有Python中解析json的现成库。

在写代码之前,先看看这些json格式的内容。限于篇幅,我只提醒大家用好fiddler的json查看工具+这个网站,或者直接参考下面2张图。
解析出文章的列表后,结合第二篇提到的下载单个文章的源码,稍加修改即可。整个项目的源码160行,难度不大。
最后,你可能还在想,微信文章列表是怎么得到的呢?如何自动下滑?你可能需要一个按钮向导,或者自己用python写一段小代码,但这两种方案似乎上手有点困难,不妨把这个当做一个小作业来测试大家的智慧。因为,至少,您只需单击几下即可手动完成,而且这只是一种过渡方式。
以上就完成了整个批量下载文章的主要流程。但这样做至少有 3 个明显的缺点:
文章列表页需要手动翻页,不能翻页太快,否则很容易被微信限制。最近的 文章 不收录在列表中,因为最近的 文章 不是上述 URL 的形式。每次下载新账号,都必须手动修改py文件中的save目录。
当然,这些缺点是有解决办法的。将html转换成pdf和word并不难。至于是否写在下面的文章,就看大家对这篇文章的鼓励了。
但至少,看到你在这里,你可以自己保存你想要的东西,让我们行动吧!
当然,我想再次提醒大家,这只是一个学习项目。有太多细节无法解释清楚。想批量快速完成大量文章保存任务的可以请专业人士解决。你会发现它困扰了你很久。在专业人士看来,这个问题可能只需要 5 分钟。

