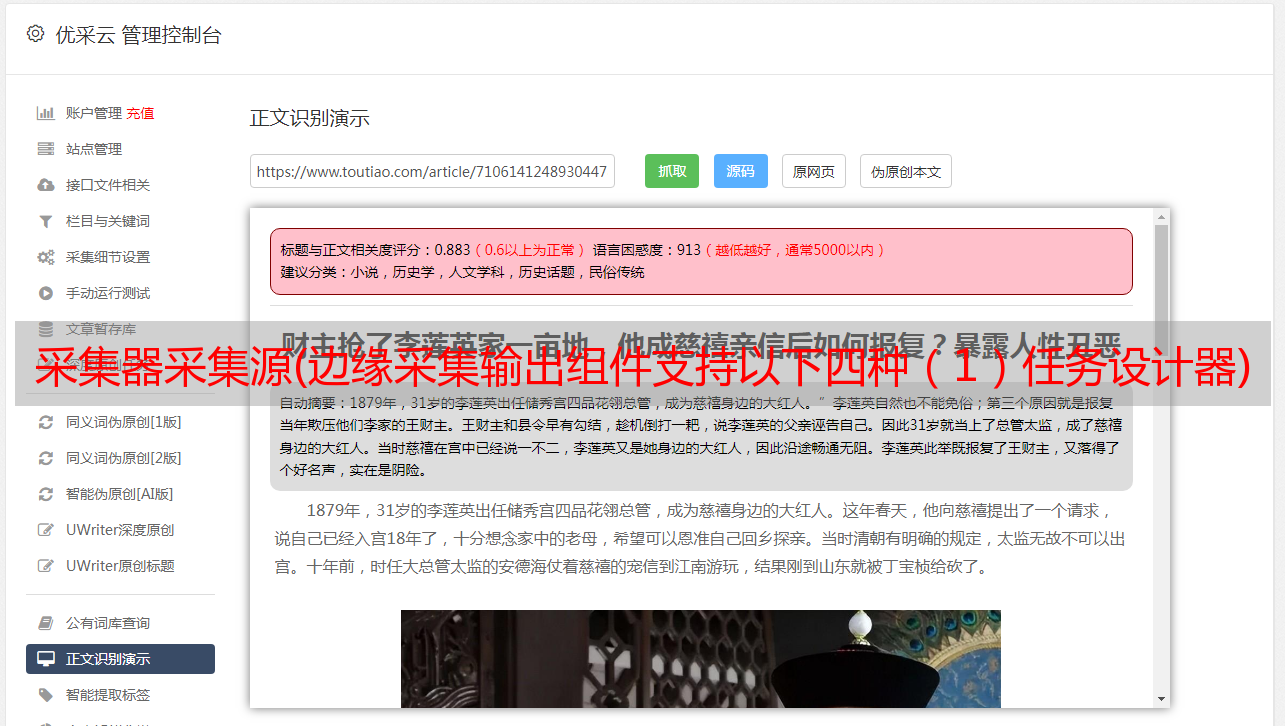
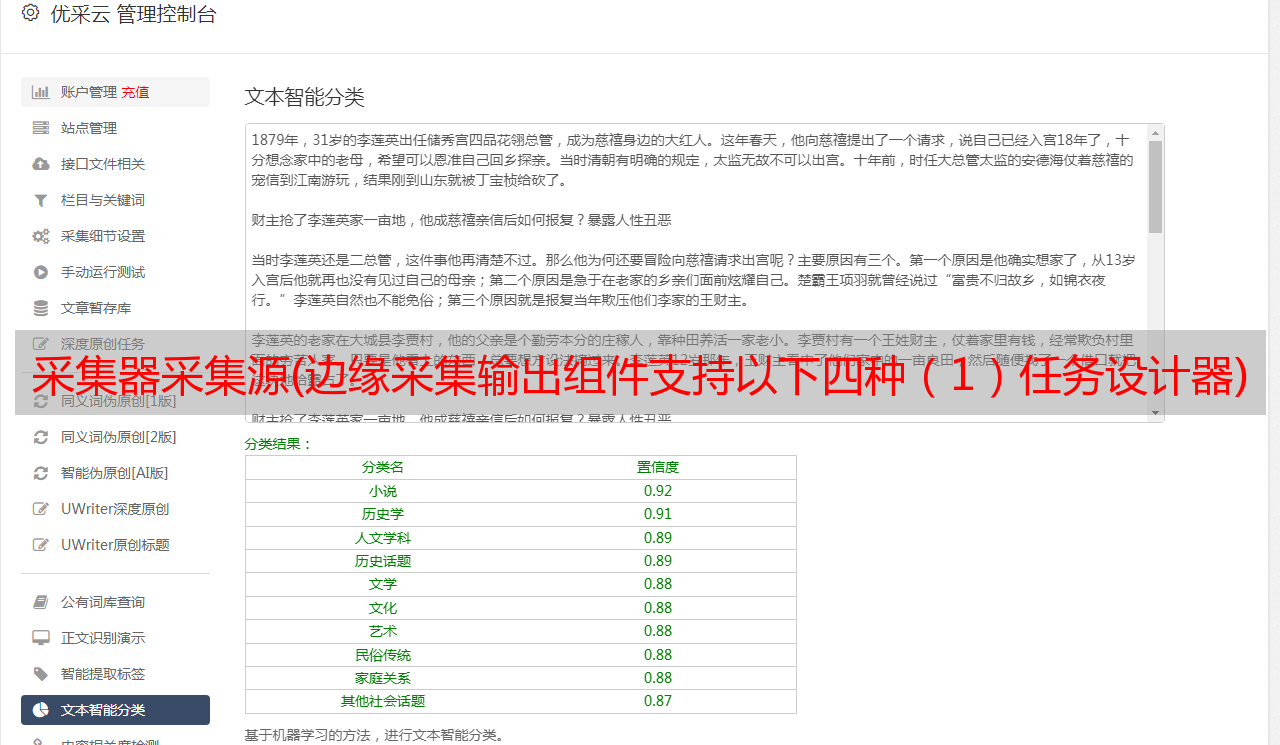
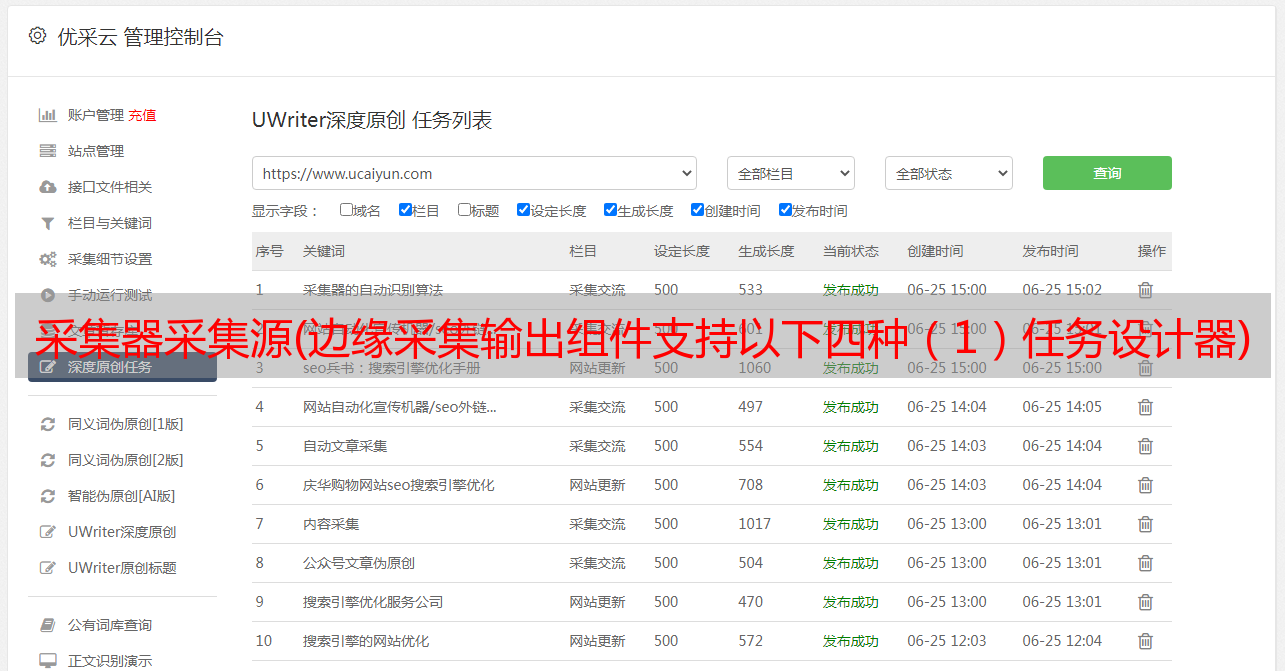
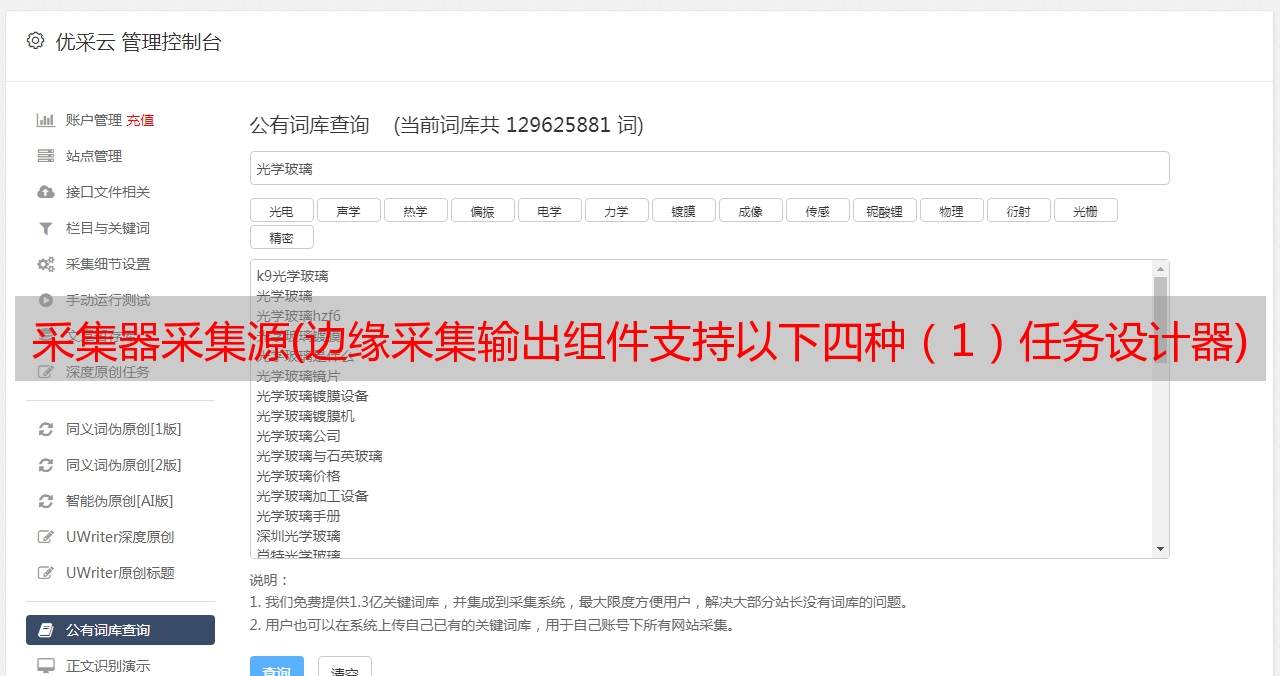
采集器采集源(边缘采集输出组件支持以下四种(1)任务设计器)
优采云 发布时间: 2022-04-16 18:34采集器采集源(边缘采集输出组件支持以下四种(1)任务设计器)
edge采集 输出组件支持以下四种
(1)Edge采集HDFS输出组件:可以从内存中接收FLUME编译器输入组件的数据,通过RPC实现端到端的批量压缩数据传输。
(2)Edge采集Avro输出组件:可以从内存中接收FLUME编译器输入组件的数据,并将数据写入HDFS文件系统。
(3)Edge采集HBase输出组件:它可以从内存中接收FLUME编译器输入组件的数据,并将数据写入HBase时序数据库。
(4)Edge采集Kafka输出组件:它可以从内存中接收FLUME编译器输入组件的数据,并将数据写入Kafka的指定topic。
①在ETL任务设计器组“Edge采集Input Components”下拖出“Edge采集Avro Input Components”。双击组件配置采集的边缘节点和输入源的具体信息。
一种。边缘节点(默认使用内存缓存数据):选择边缘节点,系统根据配置的边缘节点程序在采集服务器上实时生成日志数据。
湾。主机名:*敏*感*词*主机名/IP
C。端口:绑定*敏*感*词*端口,该端口需要未被占用
d:高级属性:扩展属性用于配置其他不需要的属性。格式为:键=值。
②在ETL任务设计器组“Edge采集Output Components”下拖出“Edge采集Avro Output Components”。,将之前配置的“Edge采集Avro Input Component”连接到该组件,然后双击“Edge采集Avro Output Component”配置数据的输出目的地信息。
一种。主机名:绑定的主机名/IP
湾。端口:*敏*感*词*端口
c:高级属性:扩展属性用于配置其他不需要的属性。格式为:键=值。
③点击【运行】,系统可以根据配置的边缘节点程序实现在实时采集服务器上生成的日志数据。
笔记:
1、实时任务点击【运行】后,默认在后台运行,直到用户点击【取消】才会终止。
2、采集组件和推送组件支持多对多连接。
2.脚本组件 - Live2.1 Live Groovy 脚本组件
本章主要介绍如何使用用户在Java脚本中调用数据挖掘环境中的算法包进行数据挖掘,得到结果数据。
前提条件
用户是非常擅长Java编程的技术人员,可以通过脚本组件直接支持编写Java代码进行数据处理。
应用场景
目前在大数据处理领域,开源Hadoop的很多组件都提供了多种语言用于数据处理程序的开发。SparkSQL等一些大数据组件也提供了基于SQL的数据查询处理方式。不同的技术人员会使用不同的方法。做大数据处理。
脚步
操作入口:【任务管理>任务定义>新建-实时任务>脚本组件-实时Groovy脚本】
1)新的实时 Groovy 脚本组件
打开任务编辑器,在左侧组件面板中找到转换组栏,选择实时Groovy脚本组件,拖到右侧编辑区。
双击 Groovy 脚本组件,打开设置界面,编写实时 Groovy 脚本。
注:提供脚本模式直接支持编写Java;此版本仅支持 Java。
2.2 实时 Python 脚本组件
本章主要介绍如何使用用户在Python脚本中调用数据挖掘环境中的算法包进行数据挖掘,得到结果数据。
前提条件
用户是非常擅长Python编程的技术人员。脚本组件可以直接支持编写Python代码进行数据处理。
应用场景
目前在大数据处理领域,开源Hadoop的很多组件都提供了多种语言用于数据处理程序的开发。SparkSQL等一些大数据组件也提供了基于SQL的数据查询处理方式。不同的技术人员会使用不同的方法。做大数据处理。
脚步
操作入口:【任务管理>任务定义>新建-实时任务>脚本组件-实时Python脚本】
1)新的实时 Python 脚本组件
打开任务编辑器,在左侧的组件面板中找到转换组栏,选中实时Python脚本组件,拖拽到右侧的编辑区。
2)界面设置
双击Python脚本组件,打开设置界面,设置运行模式和输出类型。
注意:当输出类型为文件时,脚本执行的结果可以写入指定文件。
注意:当输出类型为参数时,脚本执行的结果可以作为参数值赋给定义的全局参数。当输出类型为 None 时,没有返回值。
切换到脚本界面,编写实时 Python 脚本。
3.接口组件-实时3.1 实时Json解析组件
本章主要介绍如何使用 JSON 实时解析组件将 JSON 解析为数据库表。
前提条件
用户已经部署了相应的服务器。
应用场景
实时json解析组件可以从前端实时组件中读取json格式的数据,解析成结构化数据,输出到后端组件。
客户接口返回的用户信息,姓名、性别、*敏*感*词*、家庭住址等。这些信息以JSON的形式返回,通过JSON解析组件可以将用户信息放入数据库表中。
脚步
操作入口:【任务管理>任务定义>新建-实时任务>接口组件-实时JSON解析】
1)新增实时JSON解析组件
打开任务编辑器,在左侧的组件面板中找到转换分组栏,选择实时JSON解析组件,拖到右侧的编辑区。
双击JSON解析组件,打开JSON设置界面,选择字段、父属性名、解析节点类型。
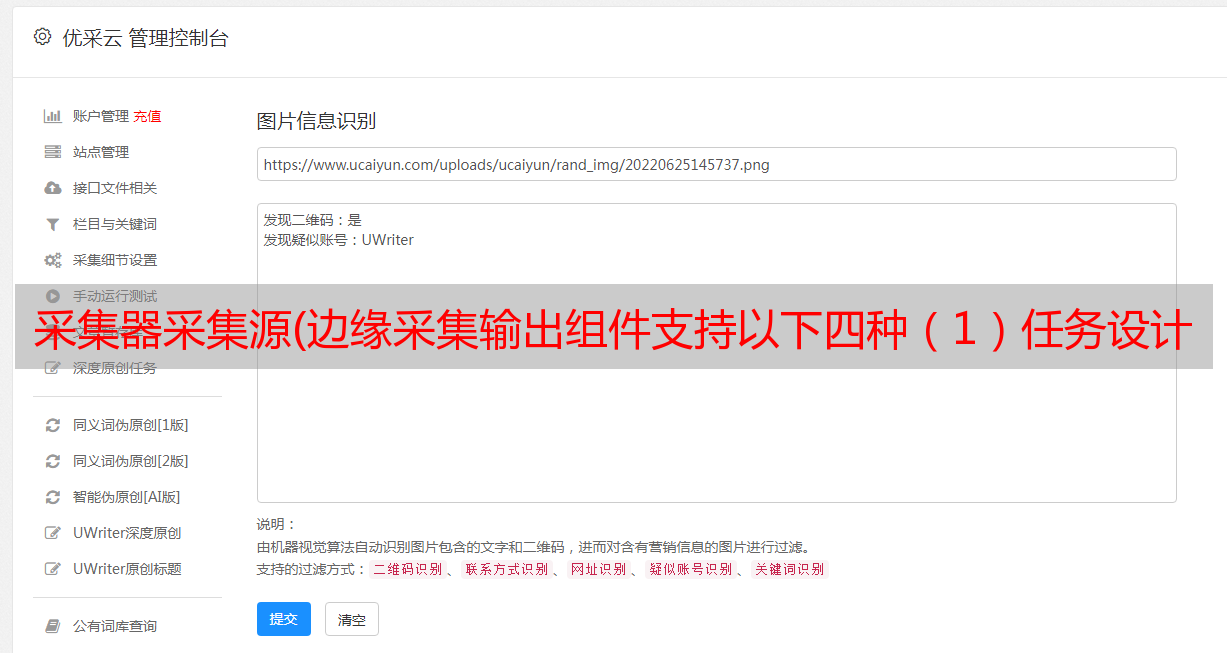
切换到字段列表界面,选择、添加、删除、上移、下移字段,点击确定。
4.输出组件4.1Kafka生产组件
本章主要介绍如何使用Kafka组件将消息写入Kafka集群。
前提条件
用户已部署 Kafka 服务器。
应用场景
Kafka 是一个高吞吐量的分布式发布订阅消息系统。Kafka 发布消息 采集 并由生产者发布。
在数据源中配置Kafka服务器,然后通过Producer组件将消息写入Kafka集群,实现消息的生产。
脚步
操作入口:【任务管理>任务定义>新建-实时任务>输出-Kafka生产组件】
1)新建Kafka生产组件
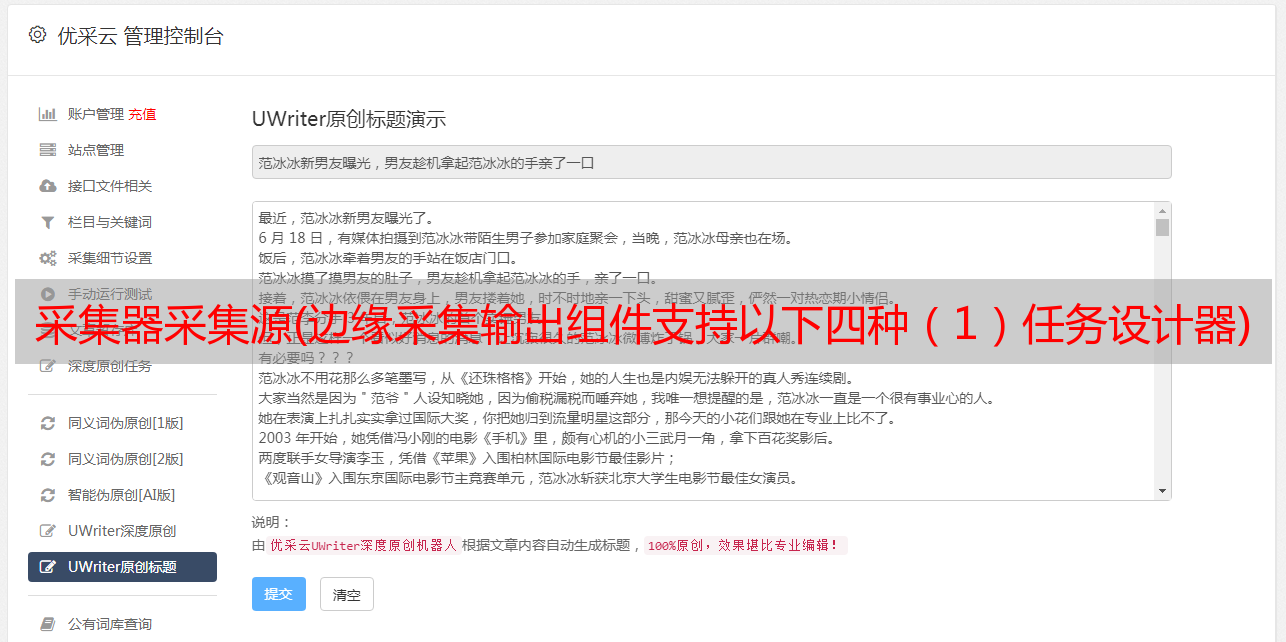
打开任务编辑器,在左侧的组件面板中找到转换组栏,选中Kafka生产组件,拖拽到右侧的编辑区。
2)界面设置
双击Kafka生产组件,打开设置界面,选择Kafka数据源、主题名字段、值字段等。
Kafka 设置包括 Kafka 服务器(从数据源中选择 Kafka 服务器)、主题分区、键类型、值类型、偏移量。设置项中的“主题”可由系统获取,用户可以直接选择主题。
注意:Kafka生产者组件可以连接前端组件,包括表输入、文件输入等可以提供数据输入源的组件。
4.2表流输出组件
本章主要介绍如何使用表流输出组件作为输出源实现数据输出。
前提条件
用户新建了一个数据库连接池,并连接了实时任务组件。
应用场景
在实时任务中,数据库表既可以用作输入源,也可以用作输出源。
用户设计一个实时任务,拖入输入组件、处理组件和表格输出组件,然后配置输入组件信息、处理组件处理逻辑、表格输出组件连接池、目标表和加载方式,启动保存后绘制数字的任务。
脚步
操作入口:【任务管理>任务定义>新建-实时任务>输出-表流输出组件】
1)新建表流输出组件
打开任务编辑器,在左侧的组件面板中找到转换组列,选中表格流输出组件,拖拽到右侧的编辑区。
2)界面设置
双击表流输出组件,打开目标设置界面,设置连接池、库表等,映射、选取、删除字段。
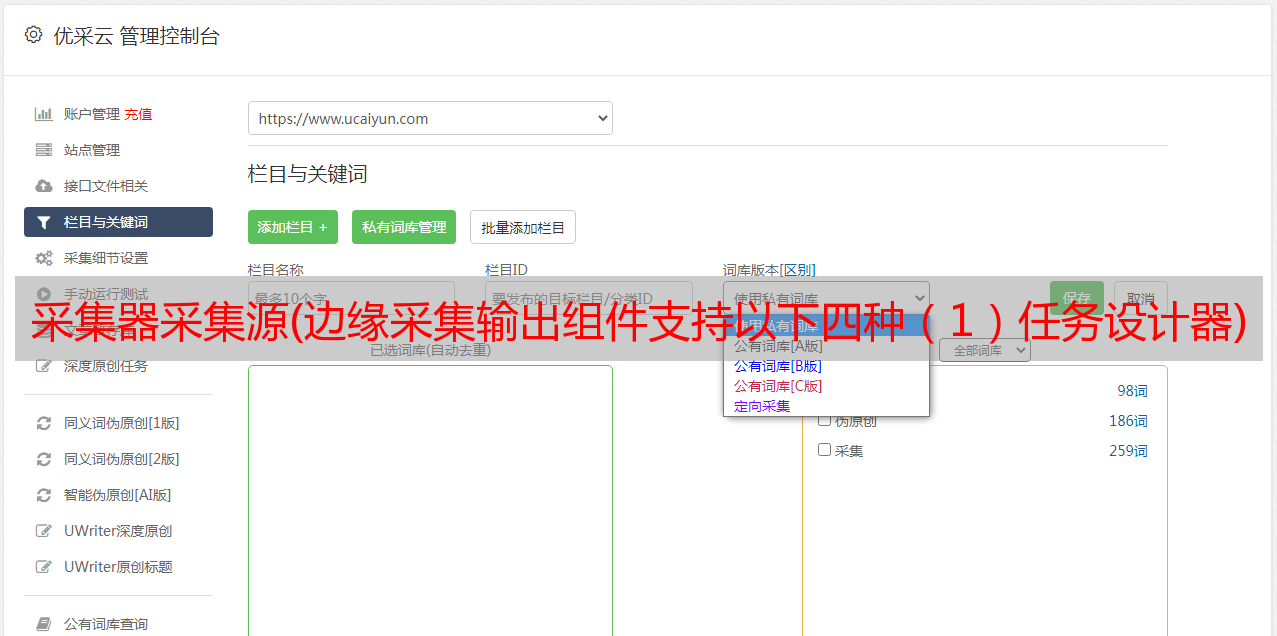
切换到附加设置界面,选择是否忽略异常,参考示例填写扩展属性,点击确定。
注:表流输出组件支持关系型数据库、Hive等,可以选择对应的连接池和表,选择表后自动显示表字段,支持不存在的表创建,支持表更新方法和批量大小设置,支持扩展属性。
表流输出组件与现有的表输出组件要求相同,但底层引擎不同。参考“3.6.4.2表输出”
4.3 实时文件输出组件
本章主要介绍如何使用实时文件输出组件将处理后的数据存储到文件中。
前提条件
用户已经部署了适当的服务器,并且前面是实时任务组件。
应用场景
在实时任务中,通常存储处理后的结果数据,部分数据存储在文件中。
用户设计实时任务,拖放输入组件、处理组件、实时文件输出组件,然后配置输入组件信息、处理组件处理逻辑、服务器文件路径和字符集、列分隔符、行实时文件输出组件中的分隔符。,保存后开始抽号任务。
脚步
操作入口:【任务管理>任务定义>新建-实时任务>输出-实时文件输出】
1)新增实时文件输出组件
打开任务编辑器,在左侧的组件面板中找到转换组栏,选择实时文件输出组件,拖拽到右侧的编辑区。
2)界面设置
双击实时文件输出组件,打开文件设置界面,设置HDFS服务器,指定文件路径、文件格式、列分隔符、行分隔符等信息。
切换到字段列表界面,选择字段,点击确定。
注:实时文件输出组件可以将实时任务处理后的数据存储到服务器文件或HDFS服务器文件中,可以设置服务器文件路径和文件名,支持宏表达式,可以设置输出文件字符set, 列分隔符, 行分隔符, 文本限定符, 第一行是否为字段名。
实时文件输出组件与现有平面实时文件输出组件的要求和功能相同,但底层引擎不同。参考“平面实时文件输出组件”
5.输入组件5.1Kafka消费者组件
本章主要介绍如何使用Kafka消费者组件实现实时数据消费。
前提条件
用户已部署 Kafka 服务器。
应用场景
Kafka作为一个高吞吐量的分布式消息系统,以生产-消费的方式生产和消费数据。Kafka 本身提供了消费者脚本来消费数据。
用户通过接口填写必要的配置信息,从Kafka消费者组件获取数据,进行下一步。
脚步
操作入口:【任务管理>任务定义>新建-实时任务>输入-Kafka消费者组件】
1)新建一个Kafka消费者组件
打开任务编辑器,在左侧的组件面板中找到输入组栏,选中Kafka消费者组件,拖到右侧的编辑区。
2)界面设置
双击Kafka消费者组件,打开消息设置界面,选择Kafka数据源、主题等。
Kafka 设置包括 Kafka 服务器(从数据源中选择 Kafka 服务器)、主题分区、键类型、值类型、偏移量。设置项中的“主题”可由系统获取,用户可以直接选择主题。
注意:接收消息设置:值类型、行分隔符、列分隔符,当每列数据为字段名-字段值格式时,可以设置字段名-字段值分隔符。
1.行分隔符、列分隔符、字段名-字段值分隔符只有在值类型为字符串时才可以选择。
2.当值类型为JSON格式时,接收消息无需设置。
切换到字段列表界面,删除、上移、下移字段,点击确定。
当采用 JSON 格式时,仅保留一个默认字段 (COL) 用于存储 JSON 消息。当是分隔字符串时,根据分隔符存储在不同的字段中。
注意:请参阅平面文件中的格式设置。
5.2Mysql日志增量
本章主要介绍如何使用Mysql日志增量组件将配置好的表从源业务系统实时提取到数据仓库并增量加载。
前提条件
1、需要提前在采集服务器上安装边缘节点程序,并在边缘节点程序中启动canal
2、在使用Mysql增量组件之前,需要配置边缘节点的IP地址和端口号。
应用场景
Mysql日志增量组件使用阿里巴巴开源的Canal工具,对Mysql数据库的binlog日志进行实时采集分析,并将变更同步到其他数据库。
用户通过配置日志增量抽取方式配置抽取表,将配置好的表从源业务系统实时抽取到数据仓库ODS层。
用户需要从源业务系统表中增量提取数据,但业务系统表没有时间戳,用户通过日志型增量获取方式进行增量加载。
脚步
由于Mysql日志增量组件使用canal实现MySQL日志增量的数据采集和存储,在新建Mysql日志增量组件之前,需要在系统设置-参数配置-实时处理参数配置-配置边缘节点边缘节点管理 根据配置信息,系统自动确定使用哪个边缘节点来监控 MySQL 日志信息。
操作入口:【任务管理>任务定义>新建-实时任务>输入-Mysql日志增量】
1)新建Mysql日志增量
打开任务编辑器,在左侧的组件面板中找到输入组栏,选中Mysql日志增量组件,拖拽到右侧的编辑区。
2)界面设置
双击Mysql日志增量组件,切换到目标设置界面,选择源数据库表和目标表,设置主键,映射匹配后点击确定。
目标设置项包括源连接池、目标连接池、源表和目标表及其映射关系、源表和目标表字段映射关系、主键字段。支持手动选择源表和目标表映射,以及根据表名自动映射。
注意:在实时任务设计中,可以使用 MySQL 增量组件作为输入源,可以连接后续处理组件或输出组件。MySQL 增量组件可以自动从 MySQL 日志中获取变化的数据。例如,如果源 MySQL 数据库更新了一条数据,则可以在此处获取更新的数据,从而为实时任务提供增量数据源。
5.3 表流式输入组件
本章主要介绍如何对需要处理的数据进行实时表输入操作。
前提条件
用户创建了一个新的数据库连接池,然后是一个实时任务组件。
应用场景
实时任务也需要数据源作为数据输入终端。数据源多种多样,数据库表也是输入源。
用户设计一个实时任务,拖拽到表流输入组件中,然后填写数据库连接池、表名等信息,再连接过滤组件等大数据处理组件进行过滤数据,然后将数据输出到表或 Kafka。
脚步
操作入口:【任务管理>任务定义>新建-实时任务>输入-表流输入组件】
1)新建表流输入组件
打开任务编辑器,在左侧的组件面板中找到输入组栏,选中表格输入组件,拖拽到右侧的编辑区。
2)界面设置
双击表流输入组件,打开数据源设置界面,设置源库表等。
切换到字段列表界面,删除、上移、下移字段,点击确定。
注:表流输入组件支持关系型数据库、Hive等作为数据源。可以选择对应的连接池和表。选择表格后,自动显示表格字段,可以获取表格的完整数据。
表格流输入组件与现有表格输入组件的需求相同,但底层引擎不同。参考“3.6.4.1表输入”
5.4 实时Sql输入组件
本章主要介绍如何使用实时Sql输入组件通过Sql设置查询数据。
前提条件
用户已经部署了相应的服务器。
应用场景
目前在大数据处理领域,开源Hadoop的很多组件都提供了多种语言用于数据处理程序的开发。SparkSQL等一些大数据组件也提供了基于SQL的数据查询处理方式。不同的技术人员会使用不同的方法。做大数据处理。
脚步
操作入口:【任务管理>任务定义>新建-实时任务>输入-实时Sql输入组件】
1)新增文件输入组件
打开任务编辑器,在左侧的组件面板中找到输入组栏,选中实时Sql输入组件,拖拽到右侧的编辑区。
2)界面设置
双击实时Sql输入组件,打开实时Sql设置界面,编写实时Sql脚本。
切换到字段列表界面,删除、上移、下移字段,点击确定。
5.5 实时文件输入组件
本章主要介绍如何使用实时文件输入组件实现文件信息向数据库表的实时传输。
前提条件
用户已经部署了相应的服务器。
应用场景
一般而言,业务系统或上游系统通过定期提供批量数据文件的方式向下游系统提供数据。大多数实时处理场景包括文件处理。
用户设计一个实时任务,拖入实时文件输入组件,然后填写数据源文件信息或日志文件路径,然后连接到实时处理组件处理日志数据并将其输出到Oracle数据库表中。
脚步
操作入口:【任务管理>任务定义>新建-实时任务>输入-实时文件输入组件】
1)新增实时文件输入组件
打开任务编辑器,在左侧的组件面板中找到输入组栏,选择实时文件输入组件,拖拽到右侧的编辑区。
900
2)界面设置
双击实时文件输入组件,打开文件设置界面,选择HDFS数据源等。
切换到格式设置界面,选择文件输出格式、列分隔符、行分隔符。
切换到字段列表界面,删除、上移、下移字段,点击确定。
注意:1.实时文件输入组件可以读取本地日志文件或读取配置的数据源文件(HDFS文件),设置数据输出格式,读取文件内容供后续组件处理。这个组件后面只能跟一个实时任务组件。
2.文件支持读取单个文件,也支持读取目录下的一批文件。批量读取文件时,支持按照文件名格式依次读取(产品内置时间函数和正则表达式匹配方式)。.
3.实时文件输入组件与现有平面文件输入组件基本相同,只是底层引擎不同。参考《3.6.4.6平面文件输入》
6.变换组件 - 实时6.1 实时表达式组件
本章主要介绍如何使用实时表达式组件对实时数据中的数据项进行一定的处理。
前提条件
用户已经部署了相应的服务器。
应用场景
当需要对实时流数据进行一些简单的处理时,往往会在下游使用编程语言编写代码进行处理。如果其他实时流数据有类似的要求,就必须重新编程,这样会造成大量的重复编码。工作量。
用户对实时流中的一些数据项进行变换,如截取部分值、变换值等,然后将处理后的结果分发给下游消费系统。
脚步
操作入口:【任务管理>任务定义>新建-实时任务>转换-实时表达式组件】
1)新增实时表情组件
打开任务编辑器,在左侧的组件面板中找到转换组栏,选中实时表情组件,拖拽到右侧的编辑区。
2)界面设置
双击实时表达式组件,打开字段列表界面,进行字段的创建、选取、文本编辑、删除、上移、下移等操作,单击“确定”。
支持的函数可以在表达式编辑器中查看函数列表。
当需要替换的字段过多时,可以使用搜索替换来替换某个字段
可以手动选择字段
注意:实时任务中添加了一个新的表达式组件。该组件可以对实时数据中的数据项进行一定的处理,可以支持产品内置功能的使用,也可以支持大数据平台本身的功能,比如CDH支持的一些功能. 使用这些函数来处理数据,例如可以使用函数去除数据项两端的空格,将不同的日期格式转换为统一的字符串格式等等。
产品的内置函数可以先支持常用的函数(唯一值生成函数、窗口函数)。
产品支持大数据平台本身的功能,如Hive、CDH的内置功能。
6.2 实时过滤组件
本章主要介绍如何使用实时过滤组件对数据进行过滤,保留有效数据并传输到下游系统,保证数据传输的质量和效率。
前提条件
用户已经部署了相应的服务器。
应用场景
当一些实时流数据质量较差或者不符合采集的要求需要过滤掉时,往往会使用编程语言在下游编写代码进行处理,而其他实时流如果他们有类似的要求,数据将需要稍后重写。对于编程实现,这会造成大量重复的编码工作量。
用户通过过滤器组件在实时流中过滤掉一些不合格的数据,只保留有效的数据,传输给下游的消费者系统。
脚步
操作入口:【任务管理>任务定义>新建-实时任务>转换-实时过滤组件】
1)新增实时滤镜组件
打开任务编辑器,在左侧的组件面板中找到转换组栏,选中实时过滤组件,拖拽到右侧的编辑区。
2)界面设置
双击实时过滤器组件,打开字段列表界面,进行字段拾取、上移、下移等操作。
单击简单过滤器,选择需要过滤的字段进行过滤设置。
点击自定义过滤器,可以编写过滤条件对字段进行过滤。
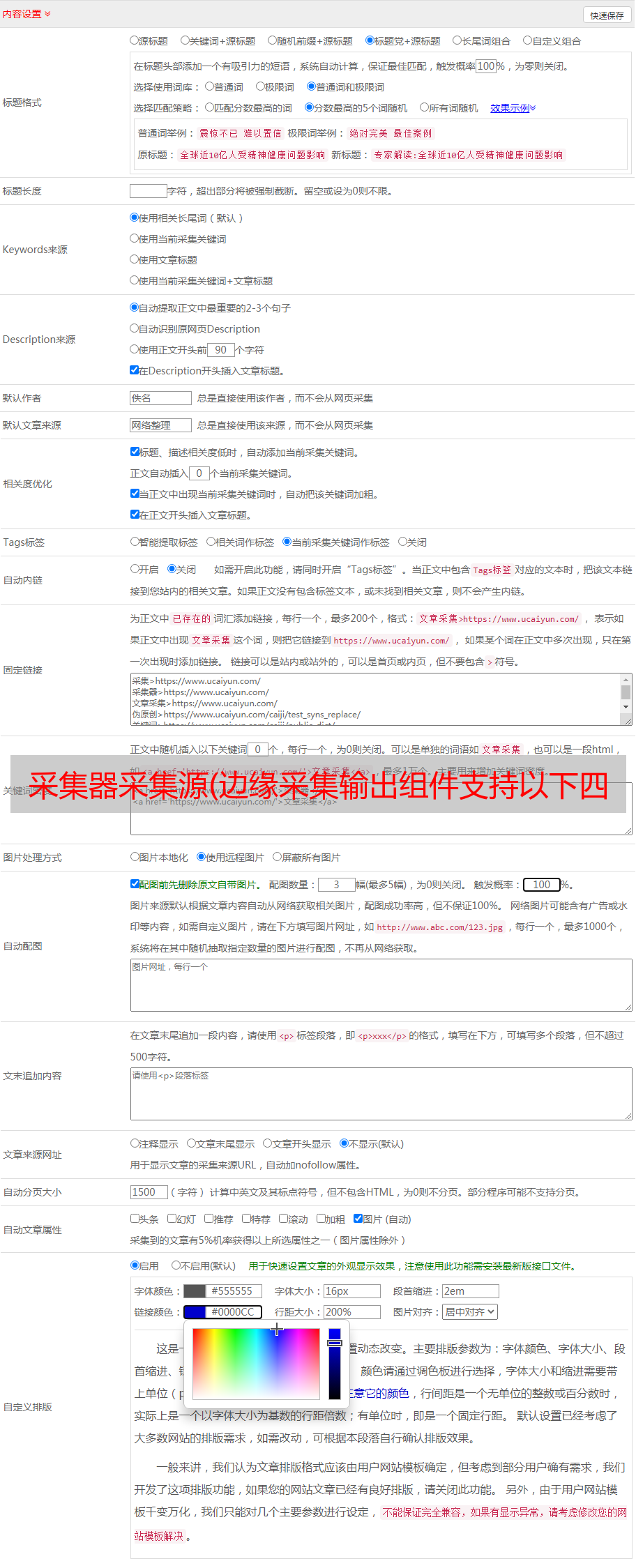
注:实时过滤组件可以对是否为空、大于等于小于等于、基于时间的过滤等进行简单的过滤。
6.3 实时聚合组件
本章主要介绍如何使用实时聚合组件对数据进行实时聚合处理。
前提条件
用户已经部署了相应的服务器。
应用场景
当需要对实时流数据进行聚合计算时,往往会在下游使用编程语言编写代码进行处理。实现一个简单的聚合功能可能需要大量的人力。如果以后对其他实时流数据有类似的要求要重新编程实现,会造成很多重复的工作量。
用户统计实时流中的网站访问者数量,使用聚合组件统计访问者数量,并将结果分发给下游消费者系统。
脚步
操作入口:【任务管理>任务定义>新建-实时任务>转换-实时聚合组件】
1)新增实时聚合组件
打开任务编辑器,在左侧的组件面板中找到转换组栏,选中实时聚合组件,拖拽到右侧的编辑区。
2)界面设置
双击实时聚合组件,打开字段列表界面,进行字段的创建、选取、文本编辑、删除、上移、下移等操作。
切换到窗口设置界面,可以选择是否设置窗口,填写相关信息项,点击确定。
事件字段:下拉框显示前面列表中的时间戳字段,需要null检测
延迟阈值:超过窗口结束时间,阈值范围内的数据需要计算入窗口。
窗口长度:窗口开始时间和结束时间的时间差,只能是数值,需要清空检测
滑动周期:相邻两个窗口开始时间的时间差,只能是数值,需要通过空检测来检测
6.4实时清洗组件
本章主要介绍如何在登陆前使用实时清理组件对数据采集进行实时快速的清理。
前提条件
用户已经部署了相应的服务器。
应用场景
一些业务系统的数据质量不高。对于海量数据,如果采用传统方式存储质检前的数据,质检时间过长,质检后数据量较大,质检性能会出现问题。
通常实时数据的数据量较小,清洗方便快捷。基于此,可以在采集落地前根据需要对实时数据进行清洗,然后将清洗后的数据存储在地面上。
脚步
操作入口:【任务管理>任务定义>新建-实时任务>转换-实时清理】
1)新增实时清洗组件
打开任务编辑器,在左侧的组件面板中找到转换组栏,选择实时清理组件,拖拽到右侧的编辑区。
2)界面设置
双击实时清理组件,打开规则列表界面,点击新建添加规则。
具体的可清理规则包括以下,列为优先级较高的规则:
1)现场操作。包括多字段合并、按分隔符拆分列等。
2)字段内容清理。包括字符串填充、替换字符串、删除字符串前后空格、删除字符串、在指定位置添加字符(字符串)等。
3)空值替换。将字符串的指定值替换为空值,将空值替换为指定值。
4)日期类型转换。日期格式转字符格式,字符格式转日期格式等
5)MD5 处理。支持拼接多个字段生成MD5。
实时数据清洗组件与现有清洗组件的需求相同,但底层引擎不同。
实时数据清洗组件可以支持正则表达式。

