织梦 采集规则将采集定向到页面,但不将采集定向到页面的内容
优采云 发布时间: 2021-05-14 05:40织梦 采集规则将采集定向到页面,但不将采集定向到页面的内容
大量信息网站具有N个通道,网站也具有N个数据。 网站的管理员不可能一一发送每条数据!此时,为了节省人力和物力,采集器诞生了(对于优化的朋友,我不建议您使用它)!接下来,我将使用织梦管理系统随附的采集器来采集一个网站数据,向您展示采集规则的编写方式!
1登录到织梦管理后台,依次单击
2 采集 >> 采集节点管理>>添加新节点>>选择公共文章 >>确定
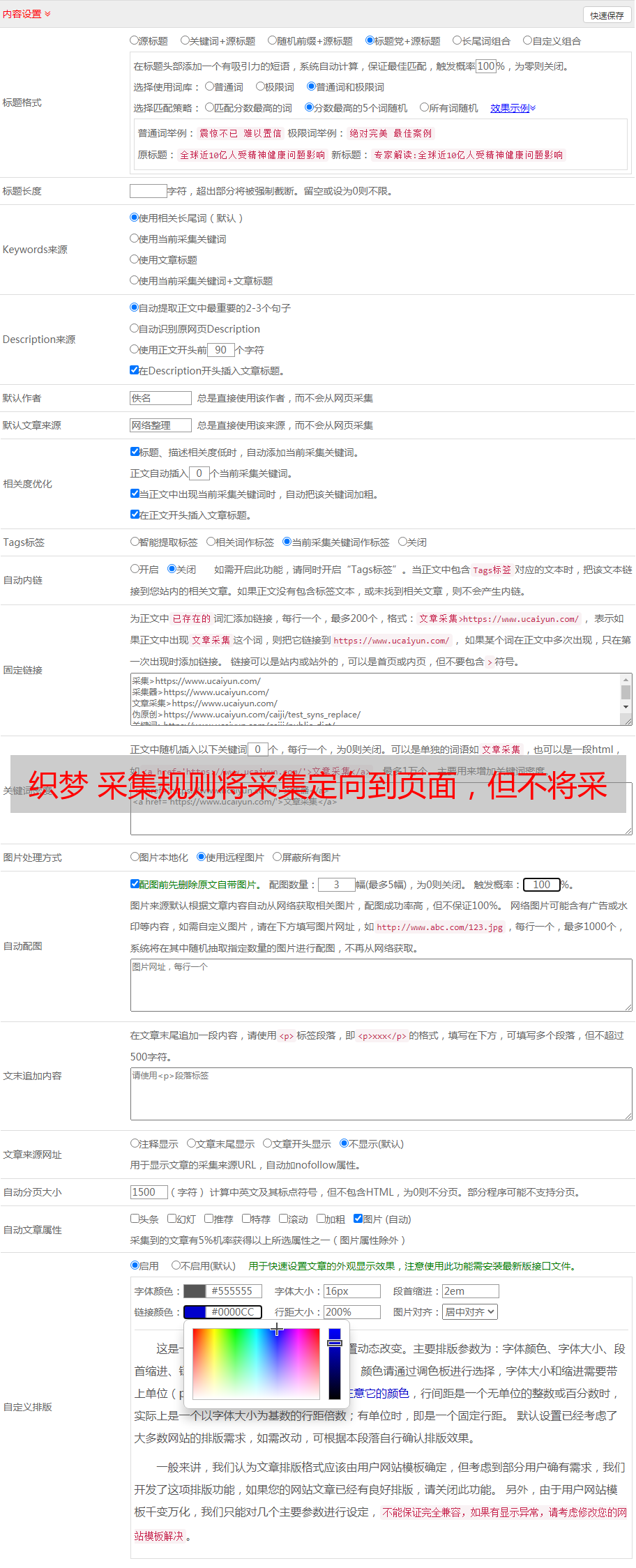
1个节点名称:任意名称(请注意,您必须能够区分它,因为如果节点太多,您可能会搞砸自己)
2目标页面的编码:查看目标页面的编码(例如,我的采集的网站的编码为GB231 2)
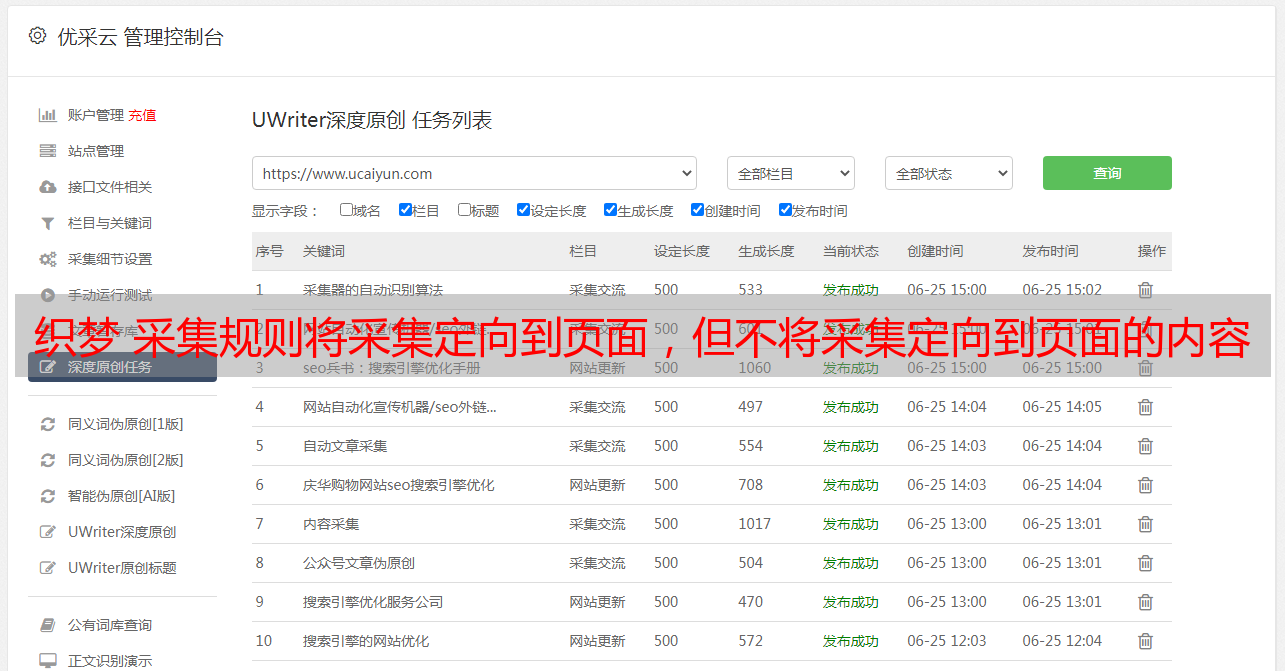
3匹配的URL:转到采集目标列表页面并检查其列表规则!例如,许多网站列表的首页与其他内部页面有很大不同,因此,我通常不采集定位列表的第一页!例如,我演示的网站列表规则是在第一页上设置默认首页,而看不到后面的实际路径,如图所示:因此,我们只能从第二页开始(尽管我们可以找到第一页)(一页),但是许多网站根本没有第一页,因此在这里我不会谈论如何找到第一页),!我们来比较一下采集目标页面的第二页和第三页!如图所示:您可以看到这两个页面有规律地增加,第二个页面是list_2!第三页是list_3!因此,我们上面写的匹配URL(*)代表列表页面的2或3或4或更多!在第三个小节上,我写了一个从2到5的(*),这意味着从2到5的+1增量与(*)而不是(*)匹配!
HTML在区域4的开头:在采集目标列表页面上打开源代码!在采集标题的文章标题附近找到一个部分,这是此页面上唯一的部分,而其他需要采集的页面也是唯一的html标签!
HTML在区域5的末尾:在采集目标列表页面上打开源代码!在采集的文章标题附近找到一节,这是此页面上唯一的部分,而其他需要采集的页面也是唯一的html标签!我们还没有使用过其他地方,所以我们可以忽略它!这样,列表页面的规则就被写入了!下图是我编写的列表规则的屏幕截图!完成后,单击以保存信息并转到下一步!如果规则编写正确,则将进行收录内容的网站访问规则测试:如下所示,然后单击“下一步”!输入以填写采集内容规则
6
1 文章标题:在文章标题之前和之后找到两个标签以标识标题!我的采集的网站的文章的标题前后唯一的标签是...,只需写下[content]。
2 文章内容:在文章内容之前和之后找到两个标签以标识内容!我的采集的网站的文章内容之前和之后的唯一标签是
...
定义常用的采集规则
1 {dede:trim replace =“&qu艺溾麾麾汤ot;}
{/ dede:trim} {d髫潋啜EDe:trim replace =“”}
{/ dede:trim} {dede:trim replace =“”} {/ dede:trim} {dede:trim replace =“”} {/ dede:trim} {dede:trim replace =“”} {/ dede:trim} {dede:trim replace =“”}] *)>(。*){/ dede:trim} {dede:trim replace =“”} {/ dede:trim} {dede:trim replace =“” } \#p \ #Subtitle \ #e \#{/ dede:trim}
以上是dede常用的采集规则,请与dede网站管理员共享以使用
网站的网站管理员朋友每个人都知道采集是织梦而不是织梦 网站由网站开发的非常简单易用的采集插件,但是很多人头疼采集如何采集 RSS内容,网站没有详细介绍,我接下来将分享采集如何采集 RSS内容。
1首先,我们需要找到目标站的RSS的页面位置。下面以百度新闻的RSS 采集为例。
2通常,大型网站将具有其自己的RSS订阅功能,但要查找它并不容易,那么我们将使用百度的“ 网站名+ rss”
3打开目标网站的rss页面,然后选择我们需要的[rs15]部分。
4复制我们需要的rss地址采集。
5然后我们进入后台网站,打开采集 Xia 采集设置,然后将复制的RSS地址粘贴到采集 Xia RSS设置中。
6单击以保留设置后,我们会发现采集任务状态将显示采集的RSS地址。
7这样,我们的采集 RSS设置已完成,如果采集不是文章,则可能是您的RSS地址填写错误,检查了RSS地址页面或更改了目标网站 采集可以。
我最近使用了dede cms 织梦 采集规则模块采集的内容,发现某些分页内容只能是采集第一页的内容,但是分页不是采集]到。版本文章的内容不完整。经过个人研究,对织梦 采集规则进行了调整,并且解决了dede cms 织梦 采集模块无法分页采集中的内容的问题。以下是针对该问题的个人解决方案。
1 1、登录到dede cms 织梦后台管理系统并打开采集规则模块界面。检查先前编写的采集规则,我发现采集列表,采集 文章,采集内容和采集分页均正常设置。单击采集进行测试,您也可以正常获取内容和页面URL。但是,当我打开前端页面查看文章时,发现文章未完成,并且从第二页中没有找到任何内容。
2 2、有这种情况。我猜想当我使用dede cms 织梦 采集模块设置规则时,列表规则,文章规则和分页规则应该都可以。因此,我查看了内容采集规则,并将内容开头的代码放在目标网站中的第一页和第二页中,以分别进行搜索。当然,在第一页中有这个。代码段,以及在第二个代码段中找不到相应的代码。如下图所示
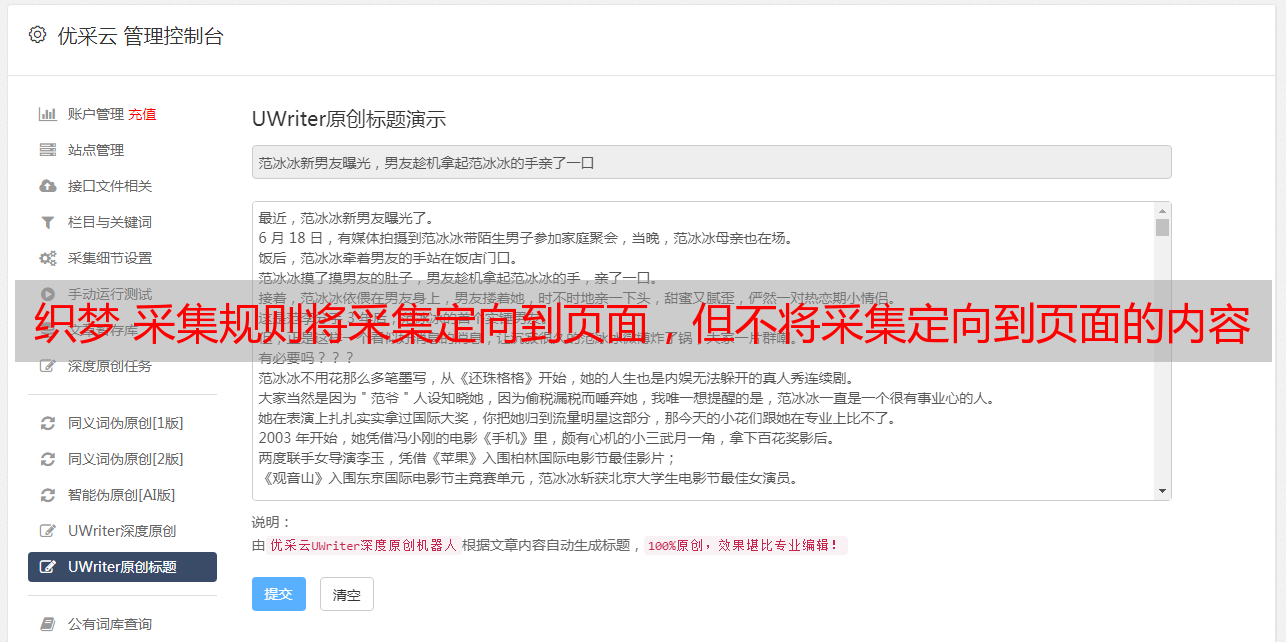
3 3、重新比较了第一个和第二个选项卡的网页代码,找到了两个页面中收录的片段,并在内容规则中对其进行了设置。
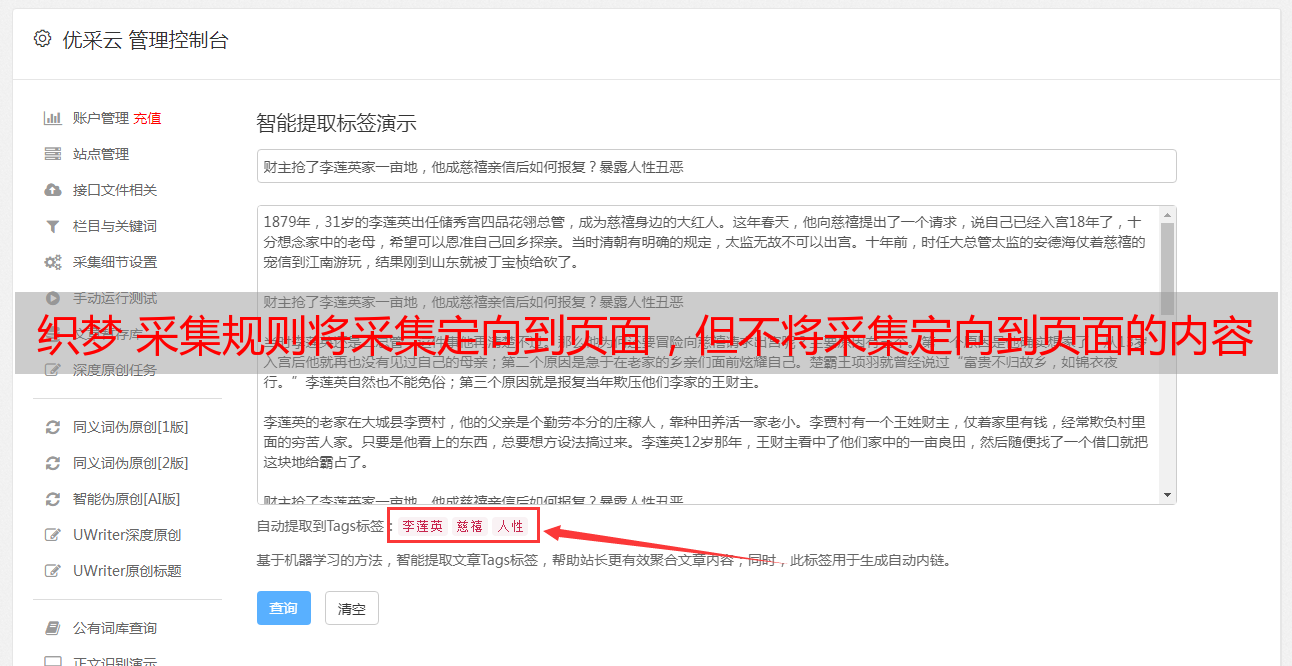
4 4、保存重置规则后,单击采集进行测试,您可以看到dede cms 织梦系统发布的文章已完成采集到页面的内容。
这种体验纯属手动原创编辑,请就缺点提出建议。如有任何疑问,可以联系我的百度帐户thinktan cn。您也可以与我联系以获取更多相关的dede cms 织梦 采集技术和服务器技术交流。
如何采集邮箱
1通常,用户需要使用论坛和网站上的某些可公开查看的邮箱采集进行公司营销。数据采集是大数据应用程序中最低,最基础的应用程序,已被熟练使用。 优采云 采集器将使用大数据时代的解决思路为您的Internet营销节省大量成本和时间。
2今天,如果您自己使用规则市场中的现有规则,我们将通过图片和文字进行解释!
3找到规则后,您可以将规则导入任务并开始运行,因此在此不再赘述。在运行过程中,需要特别注意一件事,即设置工作流程的链接,需要修改搜索条件。该示例中的搜索条件为:@ site :,您可以修改搜索条件并将其替换为您指定的URL和邮箱的类型。修改完成后,保存后即可开始操作。
4接下来,我们将重点介绍更常用的网站相关规则。有需要的用户可以在优采云规则市场中直接下载它们。 优采云团队还呼吁每个小伙伴加入。将设置的规则上载并共享到规则市场,以供其他小伙伴使用。如果您需要有关规则的帮助,则可以转到优采云 采集器论坛和优采云 采集交换组2组302187299。
对于旗舰版以上的用户,可以通过云采集实现多任务并发和单任务加速的采集效果,以便用户可以快速采集和组织Internet公共数据。本教程主要讨论云采集的原理和规则加速设置。
1 一、 Cloud 采集原理A. cloud 采集的规则任务至少占据一个云节点,并且最多可以占用所有云节点。 B.规则任务满足拆分为子任务的要求时,最多可以划分为199个子任务。 C.一个子任务占用一个节点,子任务的完成意味着该任务已完成。 D.常规任务分为多个子任务,并分配给不同的云节点以达到加速效果采集 E.如果云节点已满,则新启动的任务或拆分子任务将进入等待队列,直到用户的特定云节点执行用户的特定任务并释放节点资源。
2如图所示,将任务分配给红线处的云节点,并同时进行多任务采集数据,如红色框所示,因为节点已满,它们只能进入等待队列并等待让云节点完成执行并释放资源。 二、云采集加速设置根据云采集的原理D,如果您想让任务加速采集的效果,则该任务必须满足分割条件或将任务更改为具有以下条件的任务:满足拆分条件,因此为了达到单任务加速的效果。满足拆分条件的任务是:A. URL列表循环B.文本列表循环C.固定元素列表循环1、 URL列表循环,文本循环对于非AJA电台,以公共存储为例,假设I want 采集对于网站类别下的所有商店,我们可以首先采集类别URL,然后为采集商店信息建立URL循环,具体步骤如下:步骤1:首先,所有特定类别采集向下,如图2所示采集评论类别URL
3个提示采集对URL进行分类后,我们可以将此URL用作数据提取的URL循环。在这种情况下,通过优采云自动任务拆分,可以将不同的URL拆分为不同的子任务,并为数据采集分配给不同的云节点,以实现单任务加速采集的效果。步骤2:通过采集在第1步中,为数据采集建立一个URL循环,如屏幕快照3 URL循环列表所示
4步骤3:效果比较,如图4所示本地计算机采集与URL循环列表云采集 采集的效率比较
5个技巧云采集除了采集比本机采集更高效之外,它还可以节省用户自己的计算机和网络资源,这可与消耗本地采集的用户的本地计算机相提并论。资源和网络资源。相比之下,云采集使用的资源都是云节点资源,用户启动云采集后可以关闭客户端,优采云会自动在优采云客户端中组织数据,仅用户需要将数据提取到。之后,您可以通过客户端查看或导出数据以得出以下结论:URL循环教程已完成。对于文本循环,其原理与URL循环相同。通过拆分文本循环,可以实现单任务加速采集的效果。 ,以便增加采集 2、的比率固定元素列表周期固定元素列表周期也满足分割条件,需要将固定元素列表周期单击在一起使用,例如固定元素列表:
6但是,在以下情况下,采集的速率将不会加快:
7原因是因为固定元素列表提取数据可以拆分为子任务,但是由于提取相同页面数据本身的速度非常快,因此几乎没有任务加速效果。例如:子任务A:打开网页(20s)-提取位置a数据(0. 1s)子任务B:打开网页(20s)-提取位置b数据(0. 1s)子任务C:打开网页(20s)-提取位置c数据(0. 1s)。 .....子任务N:打开网页(20s)提取位置n数据(0. 1s)如上例所示,尽管任务被拆分,但实际任务执行时间仍约为21秒,并且任务未拆分时间比较如下:总任务S:打开网页(20s)提取位置a数据(0. 1s)提取位置b数据(0. 1s)提取位置c数据(0. 1s)...。提取位置n数据(0. 1s)在这一点上,我们可以看到时间T = 20 + 0. 1 * 10 = 21S没有拆分,因此尽管此时我们使用非固定元素拆分了任务,但并不会在提取数据的效率方面带来显着的提高。对于固定元素列表单击元素,它是不同的,因为单击元素通常会打开详细信息页面,例如:子任务A:打开网页(20s)-单击位置元素a(20s)-提取位置a数据(0. 1s)子任务B:打开网页(20s)-单击位置元素b(20s)提取位置b数据(0. 1s)子任务C:打开网页(20s)-单击Location元素c(20s) -提取位置c数据(0. 1s)...子任务N:打开网页(20s)-单击位置元素n(20s)n提取位置n数据(0. 1s)由于子任务在同时,时间T = 20 + 20 + 0. 1 = 4 0. 1S,大约需要41秒才能修复元素。单击元素,不拆分任务的时间比较如下:总任务S:打开网页(20s),单击位置元素a(20s)-提取位置a数据(0. 1s)单击位置元素b(20s)-提取位置b数据(0. 1s),单击location元素c(20s)-提取位置c数据(0. 1s).....单击o n个位置元素n(20s)-提取位置n数据(0. 1s)在这一点上,我们可以看到它不是拆分时间T = 20 +(20+ 0. 1) * n,n = 10时, T = 221S,与分割41S相比,时间几乎是分割的5倍。总结:满足拆分条件的任务是:A. URL列表循环B.文本列表循环C.固定元素列表循环

