前程无忧网站内容(讲下爬前程怎么去实现苦于获取子标签的所有文本内容 )
优采云 发布时间: 2022-04-02 04:19前程无忧网站内容(讲下爬前程怎么去实现苦于获取子标签的所有文本内容
)
先说一下攀登未来的思路:
1.首先想到的是通过下面页面的响应来获取Xpath路径的值
2.当我去获取class='e'对应的值时,发现不是我想要的。当我转到 class='t' 下面的跨度时,我无法获取值并返回一个空列表。
3. 这时候在网页上右键查看源码,发现class='e'得到的值在这里,继续往下看发现我们想要的值在javascript
4.我尝试点击第二页获取请求的地址。我想尝试获得一个纯 json URL。发现第二页的主界面还在,没有收录纯json的url。文本
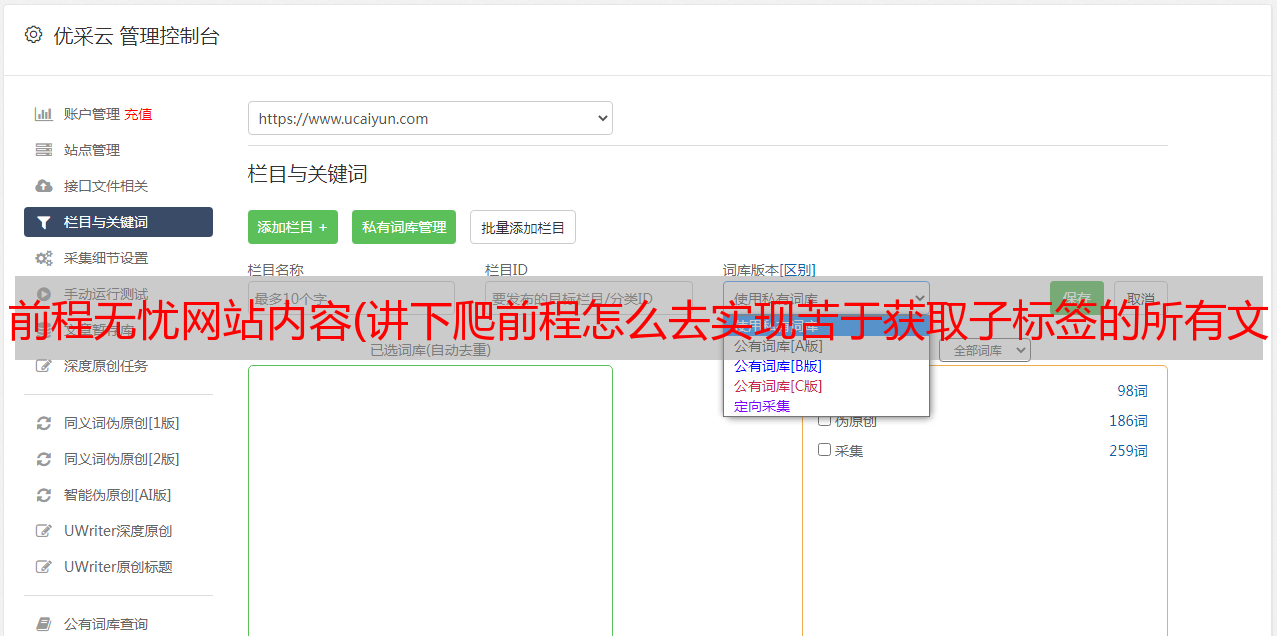
4. 那么只能想办法从之前的网页源码中获取内容了。这也是今后的反爬虫措施。想了很久,我知道如何实现了。保存html文件的方法,使用正则匹配我们想要的内容,我们想要的内容其实是一个json字符串给定一个变量window.SEARCH_RESULT。使用 json 方法将字符串转换为字典。后续操作就简单多了
5. 在页面上我们可以得到详细信息的url值
6. 然后通过scrapy.Request中的回调,使用新定义的方法请求这个url地址解析响应的文本内容
7. 然后通过父标签获取子标签的所有内容(我找了很久的方法,很实用) 可以参考父标签获取子标签的所有文字内容-标签
父级获取子标签的所有文本内容