文章采集链接( 再继续看下一步:头部源码我单独分出来的,结果我笑了)
优采云 发布时间: 2022-03-31 08:06文章采集链接(
再继续看下一步:头部源码我单独分出来的,结果我笑了)
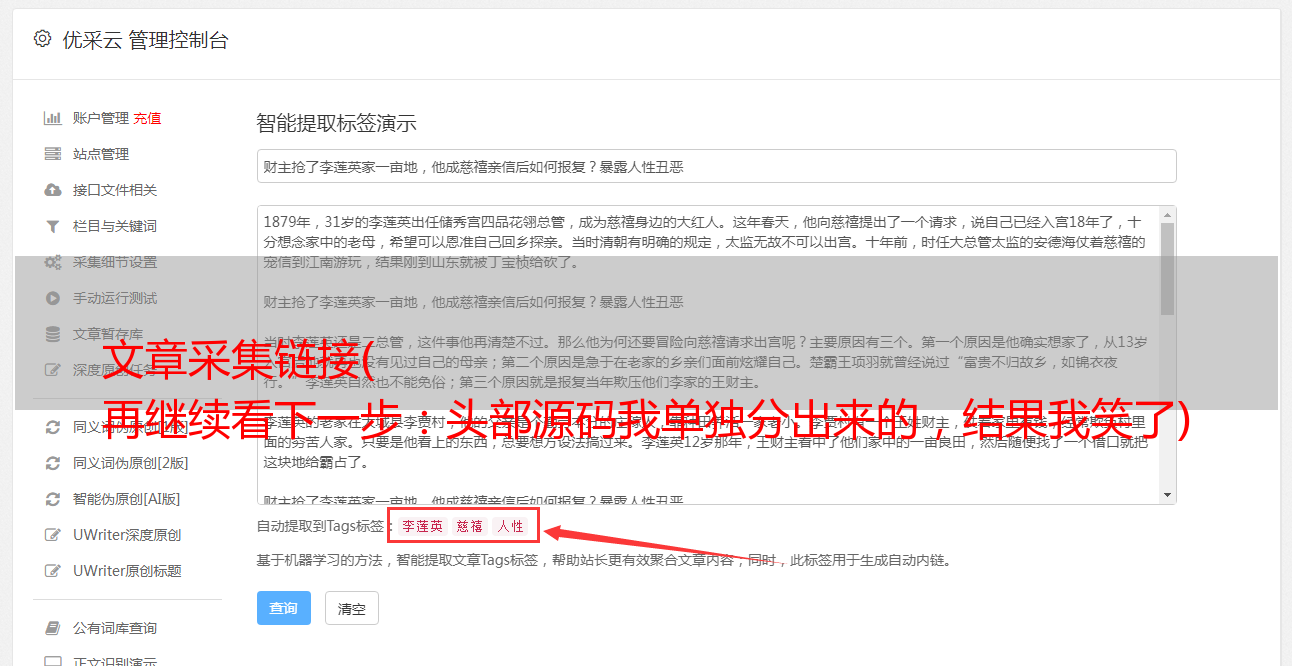
继续看下一步:
我单独划分了header的源代码。在想发这篇教程之前,我开始阅读360爬行诊断。结果我笑了,忘了删除这一步。
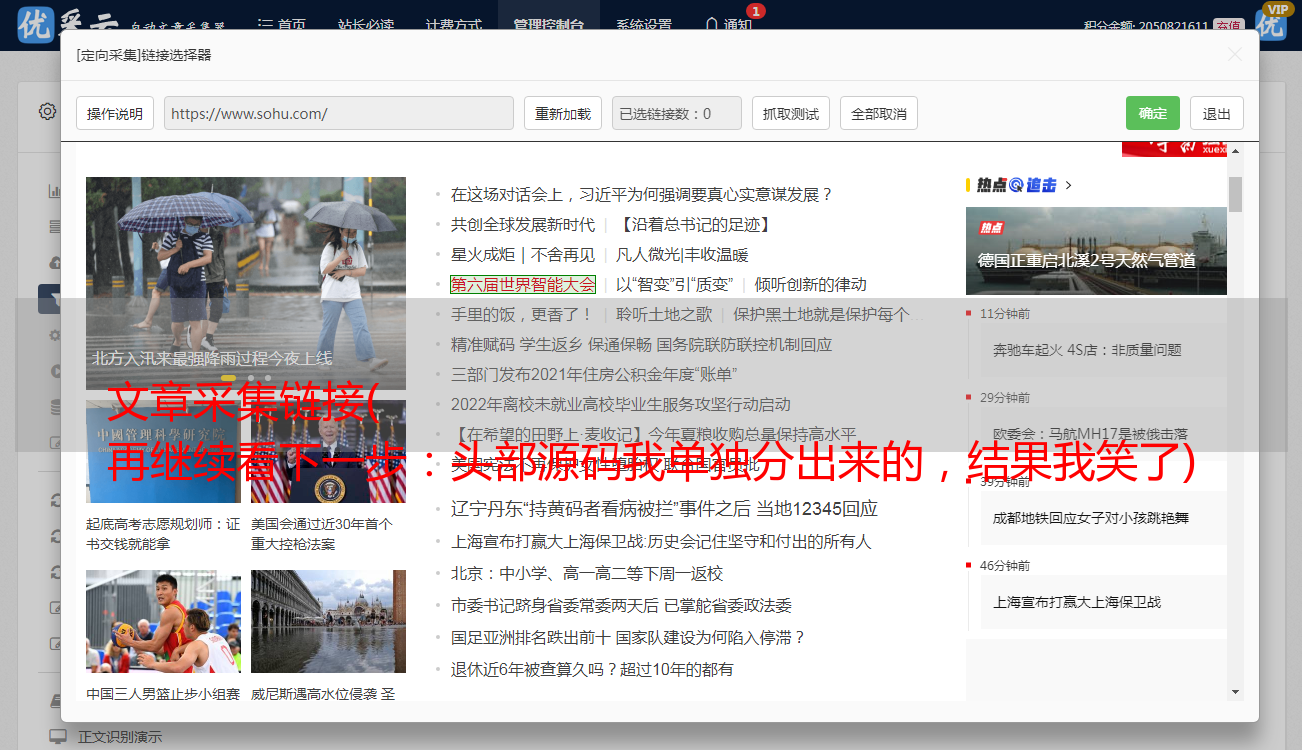
最后一步:
以下是相关内容:
这个方法可以做:采集,根目录扫描...
但是最好不要做根目录扫描软件,很烦,就说吧
首先,想要方便快捷,需要找到文本,然后判断(这个地方是一堆代码),然后根据连接和排序添加到树形框中(主要目录,二级和三级目录)...重新连接等,不包括特殊连接:如javascript,#,网站自己的域名等),为了避免数组成员错误,它是最好用时钟一步一步执行
在以上前提下,一定要多阅读网站源码来分析,否则问题多或连接少
如果第一步差不多完成了,steps的代码几乎都是执行第一步,你也会判断当前选中项,根据当前选中项进行第二次执行(后面我就不做了无论如何第一步)。,太烦人了)
采集软件:
分析单个或多个网站你要采集的整体源码,检查异同,然后判断编写代码。如果您遇到验证码,您可以在页面上使用精益模块或其他方式连接到您。
采集软件推荐(精益模块,精益助手(解析网页文章ID索引,浏览器也可以))完成。时钟必须有,会有很多正则表达式
正常情况下,网站应该取两次代码(文章栏目通用页面(获取本页每篇文章文章的标题和链接),然后连接两次,获取内容和图片)
采集一步一步完成,不要全部在显示屏上完成(程序卡,阵列错误)
总列下的一些 网站文章文章id 索引每次都会减少或增加一个。这里值得注意。

