文章采集内容(公众号文章数据采集与处理的优化应对与应对)
优采云 发布时间: 2022-03-30 21:02文章采集内容(公众号文章数据采集与处理的优化应对与应对)
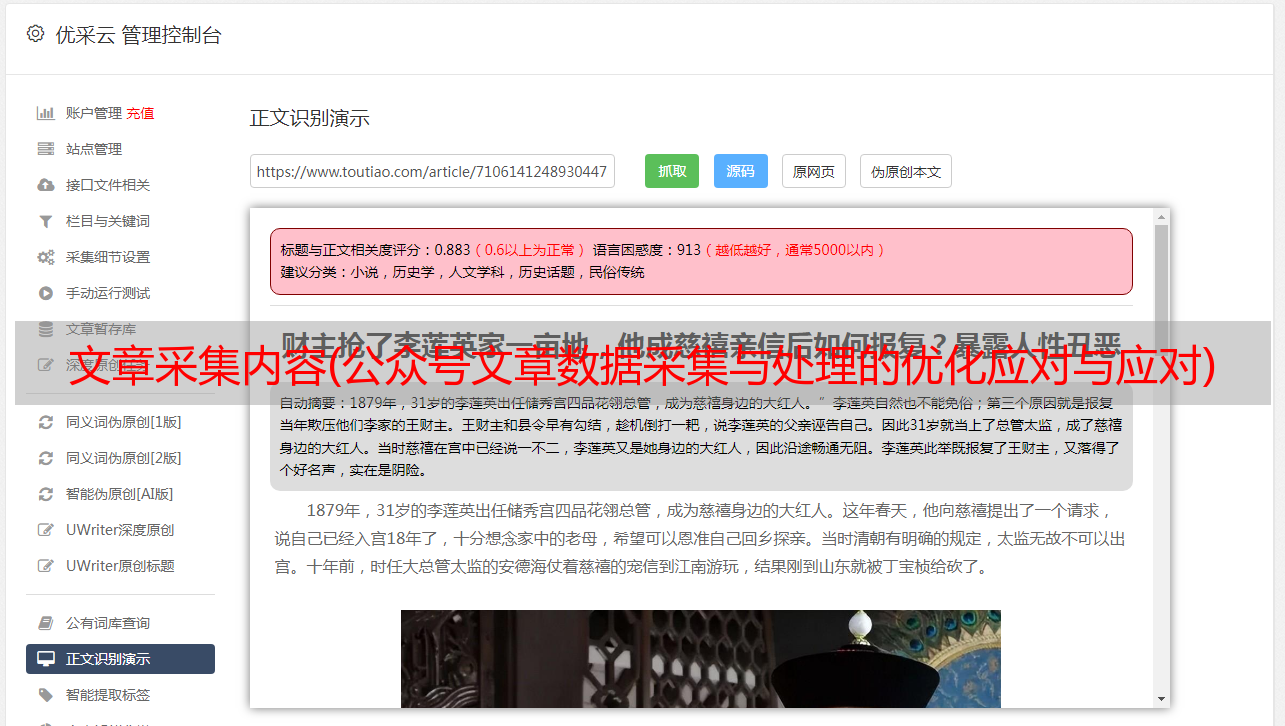
公众号文章资料采集和处理无处不在。并且数量庞大。我们目前处于数据爆炸的时代,数据采集和处理一直伴随着我们。无论是网站论坛、公众号文章还是朋友圈,每天都会产生数亿条数据、文章、内容等。
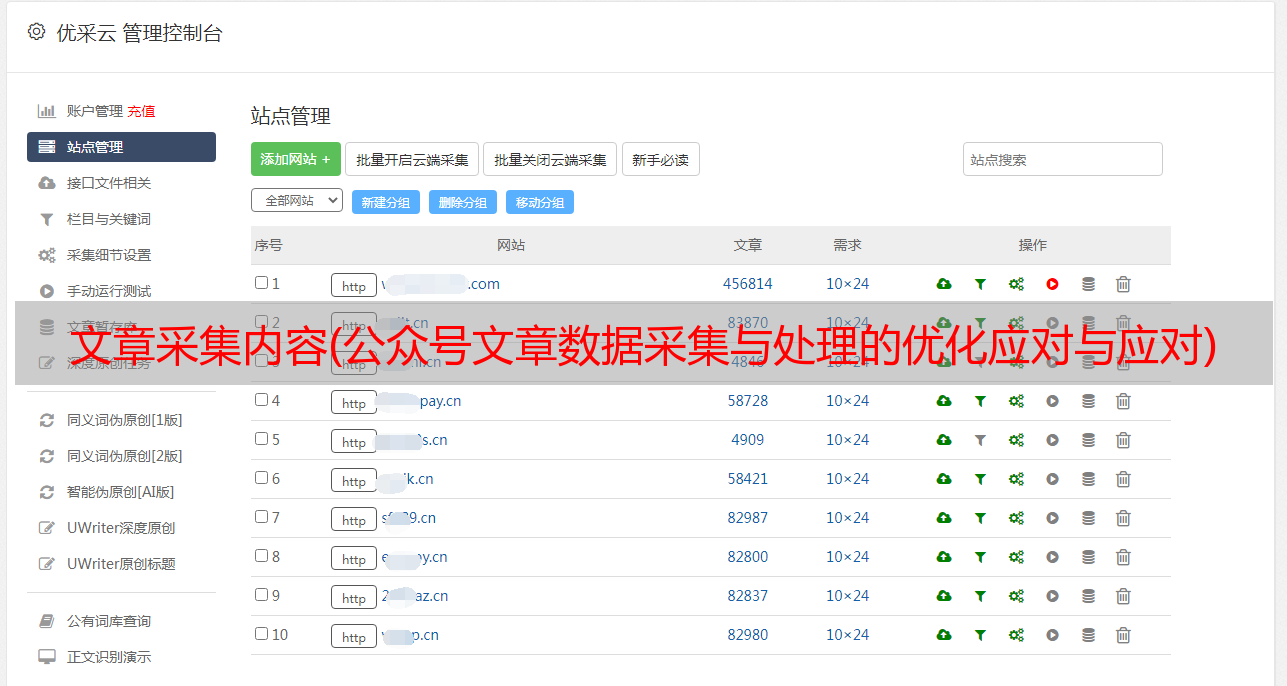
通过数据采集和处理工具,我们可以采集到我们需要采集的公众号文章的数据。将其保存在本地以进行数据分析或二次创建。
数据采集及处理工具操作简单,页面简洁方便。我们只需要鼠标点击即可完成采集的配置,然后启动目标网站采集。支持采集资源标签保留(更好的保存格式)、过滤原文中敏感词(去除电话号码、地址等)、去除原图水印等
有时网页抓取还不够;通常需要更深入地挖掘和分析数据,以揭示数据背后的真正含义并发现有价值的见解。数据和内容的分析利用可以说与我们的工作生活息息相关。
以网站SEO为例,通过数据分析,我们可以统计出网站每天的流量变化和页面跳出率,得出我们在某些环节的网站不足之处。数据还可以用于采集分析竞争对手排名关键词与我们之间的差距,以便我们及时调整,做出更好的优化响应。
当然,如果你不喜欢使用工具,我们也可以自己打代码来完成这部分工作:
第一步是通过创建蜘蛛从目标中抓取内容:
为了保存数据,以 Facebook 为例,我们将定义一个收录三个字段的项目:“title”、“content”和“stars”:
importscrapy
classFacebookSentimentItem(scrapy.Item):
title=scrapy.Field()
content=scrapy.Field()
stars=scrapy.Field()
我们还创建了一个蜘蛛来填充这些项目。我们为页面提供的起始 URL。
importscrapy
来自Facebook_sentiment.itemsimportFacebookSentimentItem
类目标蜘蛛(scrapy.Spider):
name="目标"
start_urls=[域名]
然后我们定义一个函数来解析单个内容并保存其数据:
defparse_review(self,response):
item=FacebookSentimentItem()
item['title']=response.xpath('//div[@class="quote"]/text()').extract()[0][1:-1]#stripthequotes(firstandlastchar)
item['content']=response.xpath('//div[@class="entry"]/p/text()').extract()[0]
item['stars']=response.xpath('//span[@class="ratesprite-rating_srating_s"]/img/@alt').extract()[0]
退货
之后,我们定义一个函数来解析内容页面,然后传递页面。我们会注意到,在内容页面上,我们看不到整个内容,而只是开始。我们将通过单击指向完整内容的链接并使用 parse_review 从该页面抓取数据来解决此问题:
defparse_Facebook(self,response):
forhrefinresponse.xpath('//div[@class="quote"]/a/@href'):
url=response.urljoin(href.extract())
yieldscrapy.Request(url,callback=self.parse_review)
next_page=response.xpath('//div[@class="unifiedpagination"]/child::*[2][self::a]/@href')
ifnext_page:
url=response.urljoin(next_page[0].extract())
yieldscrapy.Request(url,self.parse_Facebook)
最后,我们定义主解析函数,它会从主页面开始,解析其所有内容:
defparse(self,response):
forhrefinresponse.xpath('//div[@class="listing_title"]/a/@href'):
url=response.urljoin(href.extract())
yieldscrapy.Request(url,callback=self.parse_Facebook)
next_page=response.xpath('//div[@class="unifiedpaginationstandard_pagination"]/child::*[2][self::a]/@href')
ifnext_page:
url=response.urljoin(next_page[0].extract())
yieldscrapy.Request(url,self.parse)
所以,对于内容:我们告诉蜘蛛从主页开始,点击每条内容的链接,然后抓取数据。完成每一页后,它会得到下一页,所以它可以抓取我们需要的尽可能多的内容。
可见,通过代码处理我们的数据采集不仅复杂,还需要更多的专业知识。在网站优化方面,还是要坚持最优解。数据采集的共享和处理到此结束。如有不同意见,请留言讨论。返回搜狐,查看更多

