智能采集发布器(网页采集器可视化创建采集跨多页信息的自动规则(图))
优采云 发布时间: 2022-03-29 15:15智能采集发布器(网页采集器可视化创建采集跨多页信息的自动规则(图))
网页采集器,允许站长简单的数据采集,网页采集,和网络爬虫插件。仅需3次点击即可轻松完成多页自动采集爬取,内置强大的多级网页采集,无需任何编码,无需配置采集规则。网页采集器可视化创建采集跨多页信息的自动规则,让网站所有数据安全存储在本地,双重保护,网页采集器自动定时运行任务,定时增量是 关键词pan采集 或指定 采集。
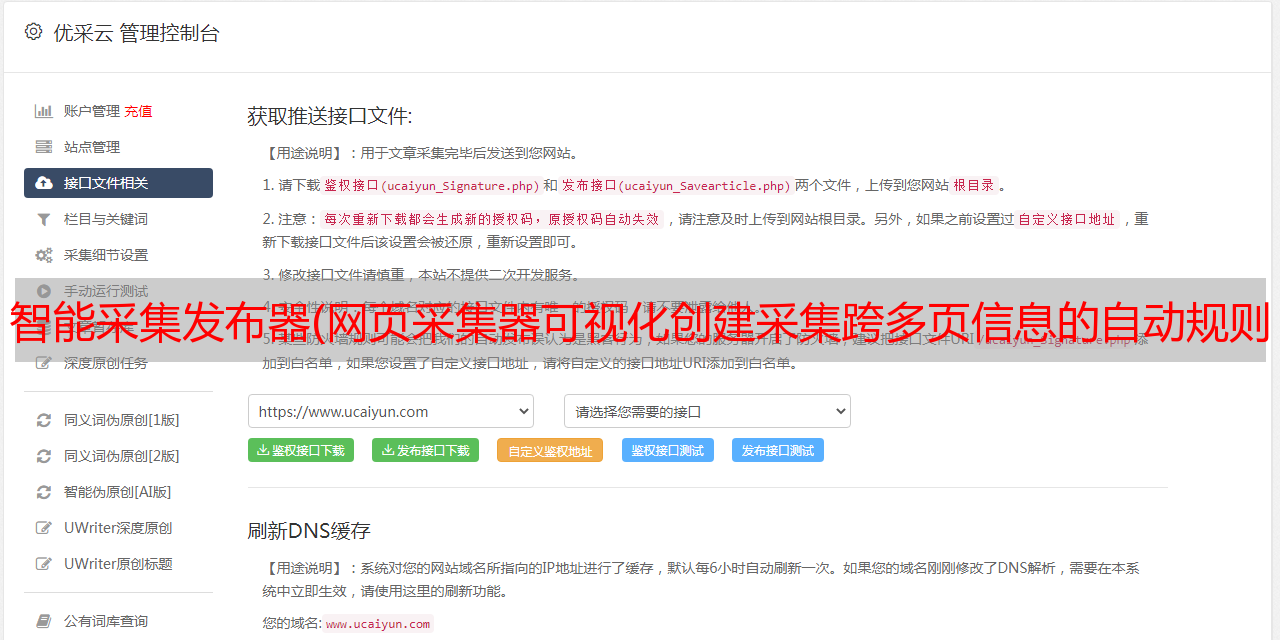
网页采集器不同于传统的爬虫,网页采集器是完全由站长控制的网络爬虫脚本。所有执行规则均由网站管理员定义。只需打开一个页面,让页面采集器自动识别表格数据或手动选择要抓取的元素,然后告诉页面采集器如何在页面(甚至站点)之间导航(它也会尝试查找导航按钮自动)。网页 采集器 可以智能地理解数据模式并通过自动导航页面提取所有数据。
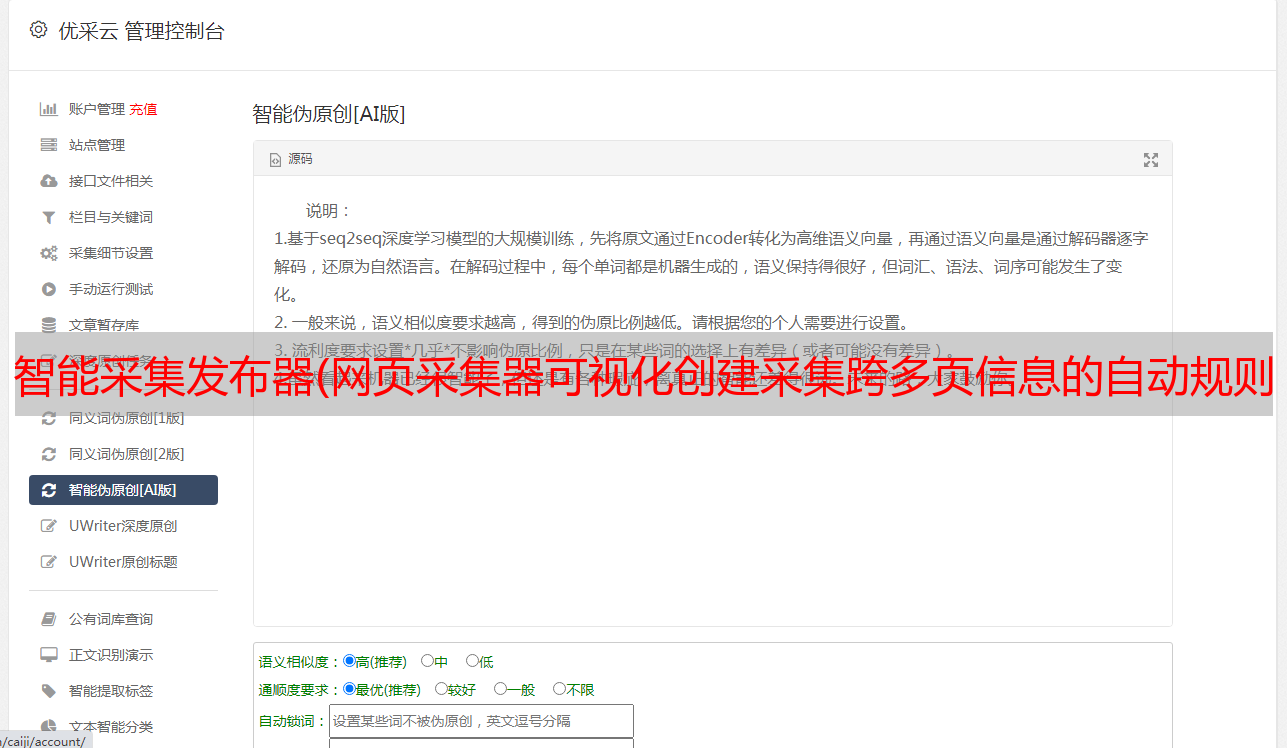
网页功能及功能采集器:自动识别表格数据;自动列表翻页识别;多页数据采集或转换;采集 图片到本地或云端;超简单的登录内容采集; 网页采集器的OCR方法识别加密字符或图像内容;批量 URL 地址,批量 关键词 查询采集。自动iFrame内容采集支持网页采集器,数据变化监控和实时通知,动态内容采集(JavaScript + AJAX),多种翻页模式支持。
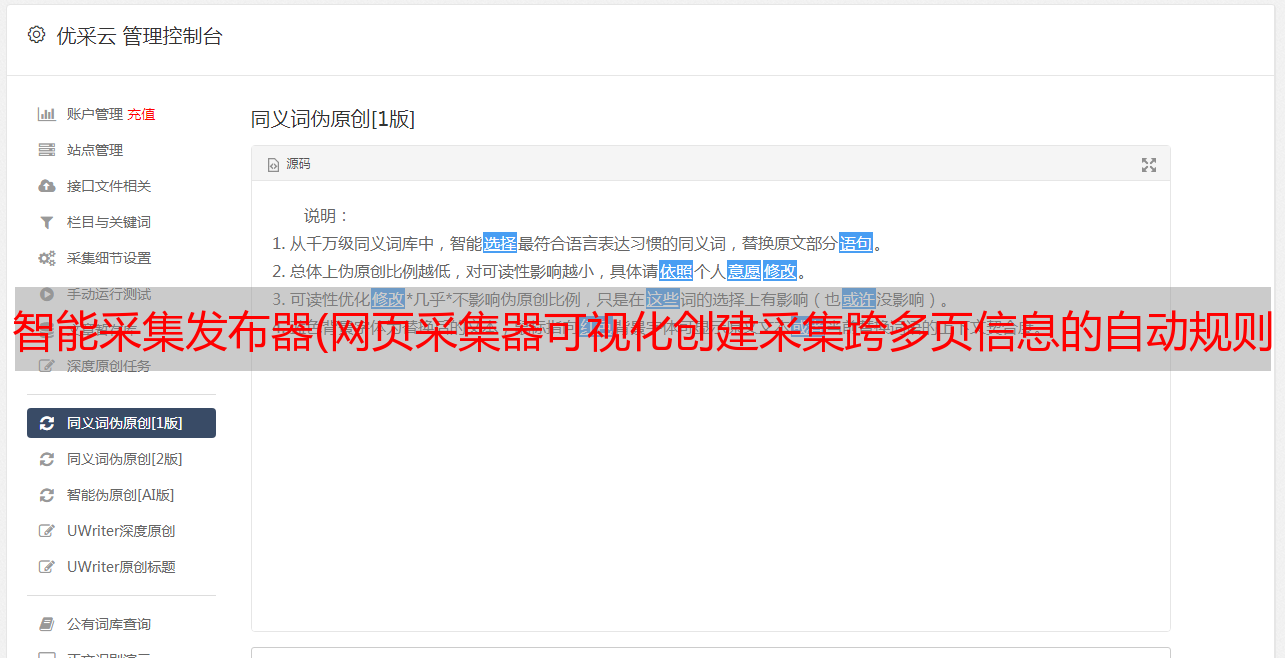
网页采集器可跨网站抓取或转换,增加数据增量采集,可视化编辑采集规则,无限数据可导出为Excel或CSV文件。网页采集器新增了100+语言转换,可以通过webHook无缝连接到网站自己的系统或者Zapier等平台,站长不需要学习python、PHP、JavaScript、xPath, Css、JSON、iframe 等技术技能。
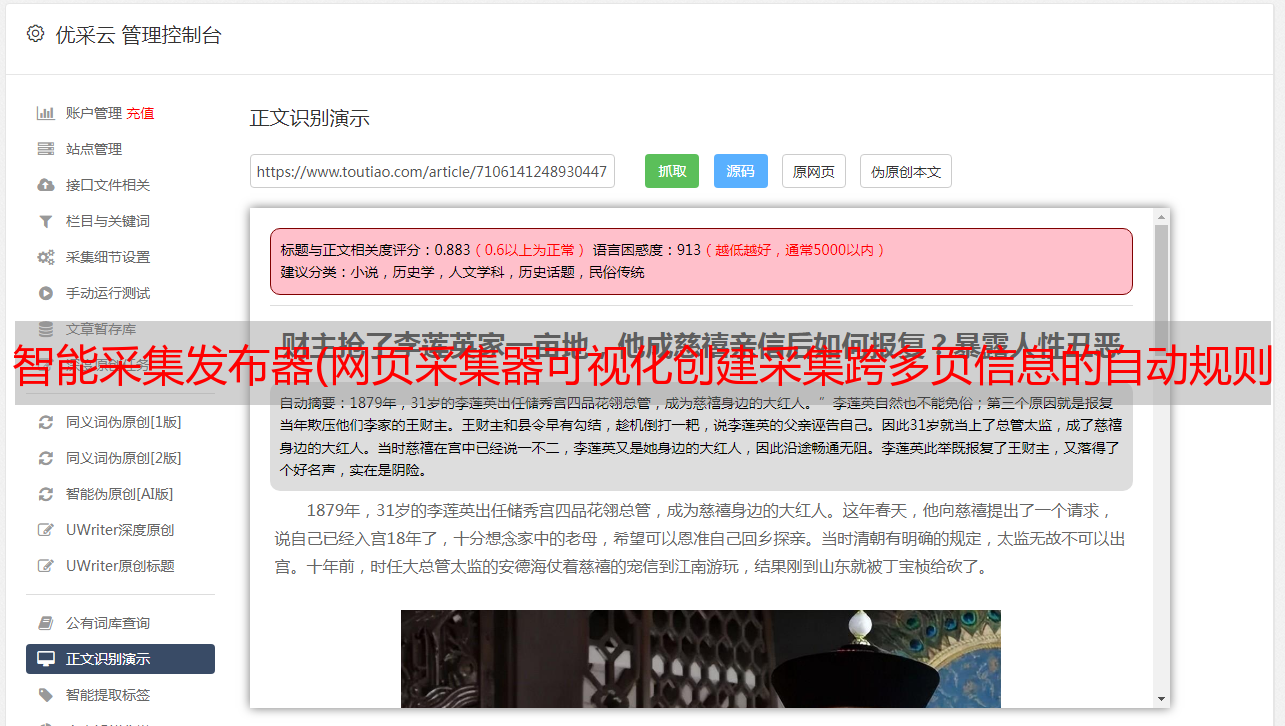
网页扩展采集器可以帮助应用实现文件输入输出、验证码识别、图片上传下载、数据列表处理、数学公式计算、API调用等功能。网页采集器的方法模拟网页的执行,可以动态抓取网页内容,模拟网页浏览、鼠标点击、键盘输入、页面滚动等事件,这是搜索引擎爬虫无法实现的. 对于有访问限制的网站,网页采集器采用防阻塞BT分发机制来解决这个问题,不需要设置代理IP来分发和运行任务。
网页采集器可配置多种网站采集规则,提供采集规则有效性检测功能(网页变化监控),支持错误发送通知。网页采集器同步采集API支持异步采集模式。网页采集器有数据查询API,支持JSON、RSS(快速创建自己的feed)数据返回格式,增加并发速率配置。网页采集器可以调度和循环多种采集定时任务配置,可以在控制台实时查看采集日志,支持查看日志文件。
网页采集器提供分布式爬虫部署,支持基于爬虫速率、随机选择、顺序选择的负载均衡方式。网页采集器的采集任务的备份和恢复功能,嵌套的采集功能,解决数据分布在多个页面的情况,循环匹配支持数据合并函数,并解决了一个文章当它被分成多个页面的时候。网页采集器配置了正则、XPath、CSSPath多种匹配方式,以及基于XPath的可视化配置功能。网页采集器可以生成四个插件:URL抓取插件、数据过滤插件、文件保存插件、数据发布插件,使网页采集器可以适应越来越复杂的需求。回到搜狐,

