网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的抓取)
优采云 发布时间: 2022-03-18 07:13网页源代码抓取工具(如何通过Chrome开发者工具寻找一个网站上特定数据的抓取)
网上爬虫教程太多了,去知乎搜索,估计能找到不少于100篇。每个人都高兴地从互联网上刮下另一个 网站。但是只要对方网站更新,很有可能文章中的方法已经失效了。
每一个网站捕获的代码都不一样,但是背后的原理是一样的。对于绝大多数 网站 来说,爬取程序就是这样。今天的文章文章不讲任何具体的捕获网站,只讲一个常见的事情:
如何使用 Chrome DevTools 找到一种方法来抓取 网站 上的特定数据。
我这里演示的是Mac上的英文版Chrome,在Windows上使用中文版的方法是一样的。
> 查看网页源代码
右键单击网页并选择“查看页面源代码”以在新选项卡中显示与此 URL 对应的 HTML 代码文本。
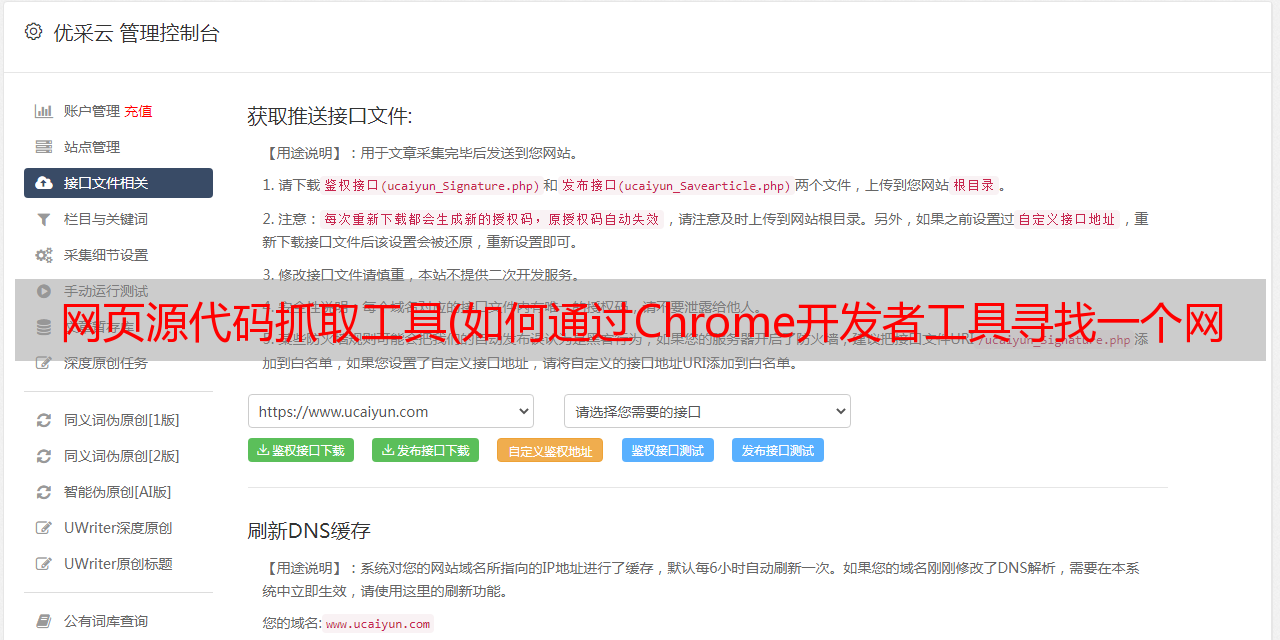
此功能不被视为“开发人员工具”的一部分,但非常常用。此内容与您直接从代码中向该 URL 发出 GET 请求(无论权限如何)所获得的内容相同。如果你能在这个源码页上搜索到你想要的内容,你可以按照它的规则通过regular、bs4、xpath等方式提取文本中的数据。
但是,对于许多异步加载数据的 网站,您无法从该页面中找到您想要的内容。或者因为权限、验证等限制,代码中得到的结果与页面显示不一致。在这些情况下,我们需要更强大的开发人员工具来提供帮助。
> 元素
在网页上右击选择“Inspect”进入Chrome开发者工具的元素选择器。在工具中是元素选项卡。
元素有几个功能:
从 Elements 工具中定位数据比我们之前在源代码中直接搜索更方便,因为您可以清楚地看到它所在的元素结构。但这里有一个特别提醒:
Elements中看到的代码不等于请求URL得到的返回值。
它是网页经过浏览器渲染后的最终效果,包括异步请求数据,以及浏览器本身对代码的优化更改。因此,您无法完全按照 Elements 中显示的结构获取元素,在这种情况下,您可能不会得到正确的结果。
> 网络
选择开发者工具中的Network选项卡,进入网络监控功能,也就是我们常说的“抓包”。
这是爬虫使用的最重要的功能。主要解决两个问题:
抓什么
怎么抓
抓什么是指如何找到通过异步请求获取的数据的来源。
打开Network页面,打开记录,然后刷新页面,可以看到所有发送的请求,包括数据、JS、CSS、图片、文档等都会显示出来。您可以从请求列表中找到您的目标。
一个一个找到它们会很痛苦。分享几个tips:
找到收录数据的请求后,下一步是以编程方式获取数据。现在是第二个问题:如何捕捉它。
并不是所有的 URL 都可以直接通过 GET 获取(相当于在浏览器中打开地址),通常还要考虑以下几点:
请求方法,GET 或 POST。
请求附带的参数数据。GET 和 POST 以不同的方式传递参数。
头信息。常用的有user-agent、host、referer、cookie等。cookie是用来识别请求者身份的关键信息。对于需要登录的网站,这个值是必不可少的。网站 经常使用其他项目来识别请求的合法性。相同的请求可以在浏览器中完成,但不能在程序中完成。大多数情况下,标题信息不正确。您可以将这些信息从 Chrome 复制到程序中,从而绕过对方的限制。
通过单击列表中的特定请求,可以找到上述所有信息。
找到正确的请求,设置正确的方法,传递正确的参数和头信息,网站上的大部分信息都可以做到。
网络还有一个功能:右键点击列表,选择“Save as HAR with content”,保存到文件。该文件收录列表中所有请求的参数和返回值信息,方便您查找和分析。(实践中发现直接搜索往往无效,保存到文件后才能搜索)
除了 Elements 和 Network 之外,开发者工具中还有一些功能,例如:
来源,查看资源列表和调试 JS。
控制台,显示页面的错误和输出,可以执行JS代码。很多网站都会把彩蛋放在这里招募(找比较有名的网站试试)。
但这些功能与爬虫关系不大。如果开发 网站 并优化 网站 以提高速度,则需要处理其他功能。这里不多说。
总结一下,其实你应该牢记以下几点:
在“查看源代码”中可以看到的数据可以通过程序直接请求当前的URL来获取。
Elements 中的 HTML 代码不等于请求返回值,只能作为辅助。
在网络中使用内容关键字搜索,或保存为 HAR 文件并搜索以找到收录数据的实际请求
查看请求的具体信息,包括方法、头、参数等,复制到程序中使用。
了解了这些步骤后,网上的大部分资料都可以得到。说“解决一半问题”不是头条新闻。
当然,说起来容易一些,但是想要精通的话,还有很多细节需要考虑,还需要不断的练习。但是考虑到这几点,再看各种爬虫案例,思路就会更加清晰。

