ptcms4.2.8自动采集配置教程已被主动采集详细信息
优采云 发布时间: 2020-08-06 11:16采集教程也很简单. 如果您是从Internet购买的用户,我将给您三个长期稳定的收款规则. 无效的包裹将得到赔偿. 该集合不需要太多的三个或五个.
导出采集规则,然后按网站分类选择一个新网站. 向下滚动到背面并选择导入规则. 下拉菜单后,选择以确认修改. 您只需要在开始时选择新站点,而无需修改其他站点.
然后我们在这里选择任务,因为这是自动采集.
选择60秒作为采集间隔. 默认值为600秒,我们选择60秒!
在这里您可以看到添加的采集任务,我们单击以打开它.
然后,我们发现获取主流程状态失败. 时间显示1970
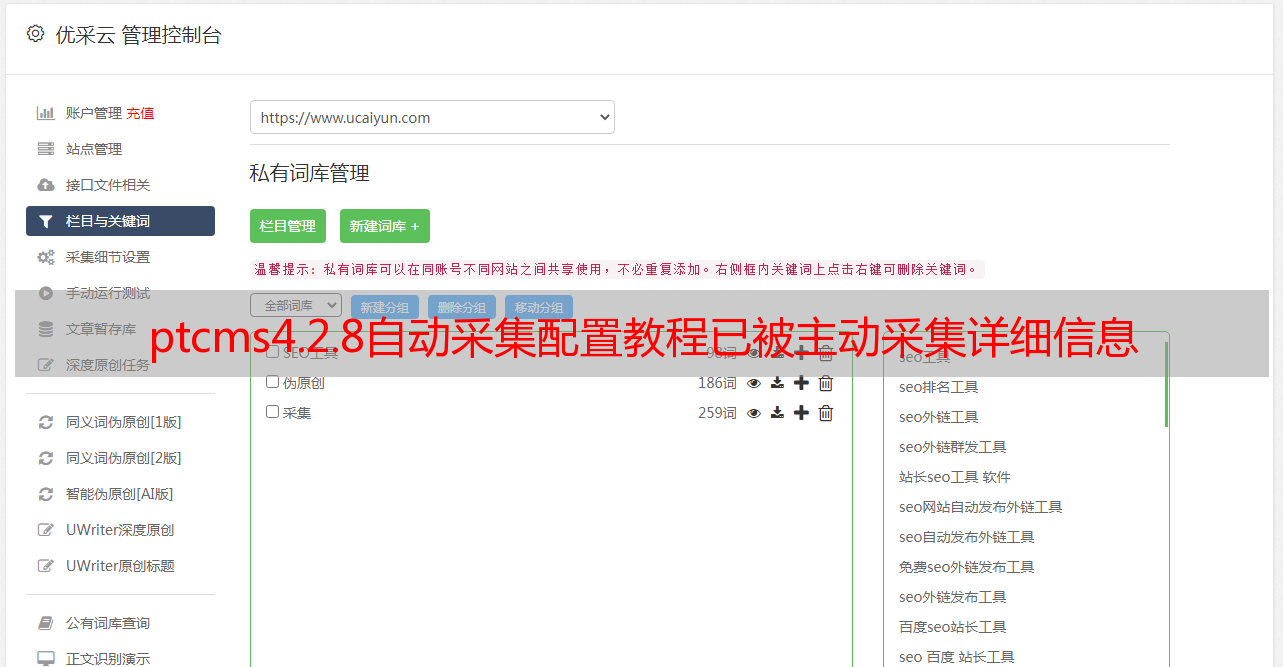
接下来,我们将像这样配置,配置cron
使用命令进入网站根目录,并将“网站根目录名称”更改为您的实际网站目录.
cd /www/wwwroot/网站根目录名称/
再次输入.
/www/server/php/73/bin/php kx cron:check
以便背景可以自动采集.
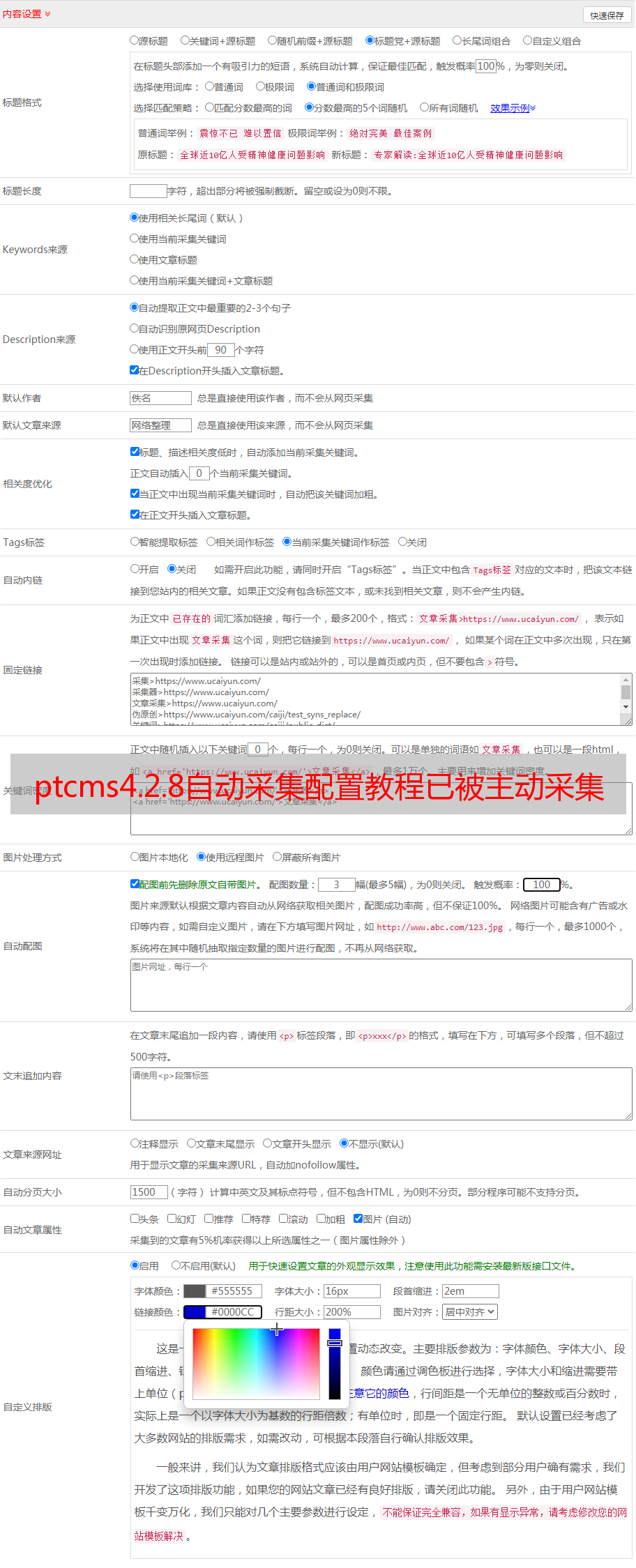
其中许多现在已启用. 这个主要过程等同于您的QQ. 您可能会挂断一段时间,并且它将离线而不会采集. 您需要再次执行此步骤. 如果服务器重新启动,则主进程将无法获取,需要重新启动. 做吧.
现在让我们谈谈活跃的采集,但是由于ptcms的特性,每天的自动采集只有几百个. 有些人刚刚建立了一个网站,小说太少了,太慢了. 我希望我会先积极采集多少本书. 再次挂断以自动采集,现在让我们解释一下.
通常使用后台脱机采集,选择规则,自定义页面,然后填写要采集的页面,例如
此页为第一页,第二页仅将1更改为2. 例如,您可以使用[page]的页码代码
[page] .html
例如,如果要采集此页的第1-5页,可以编写如下所示的内容. 本教程就是这样. 我没有在里面使用书号集合. 采集书号很容易采集废旧小说或许多没有封面的小说.

