资讯内容采集系统(100万标题数据足够网站站长操作所有大数据站群)
优采云 发布时间: 2022-03-11 11:24资讯内容采集系统(100万标题数据足够网站站长操作所有大数据站群)
新闻采集,可以采集到国内新闻源文章,从文章的数据容量,网站到< @文章的需求,对文章有严格要求的用户,对文章的质量也会有更高的要求,新闻采集的文章可以追溯到 15 年前,由于服务器数据量巨大,很多搜索引擎会逐渐删除和修剪 10 年前的 收录 索引,所以几年前的 采集文章 发布,为蜘蛛,可以看成原创。
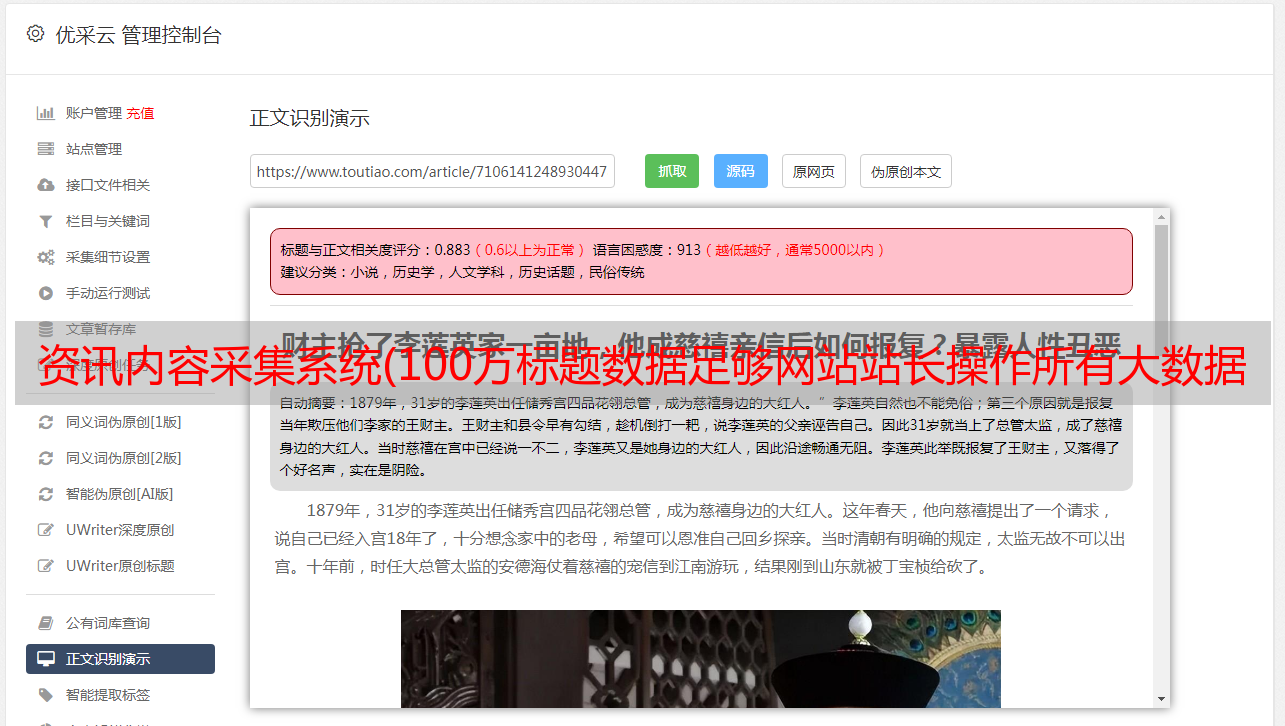
新闻采集保存内容时,会自动生成一个时间戳TXT,每个txt的容量为50Kb。超过容量后会重新创建txt继续保存。该功能是为网站或站群设计的大数据站群高频率运行和读取系统,如果TXT容量大,比如有些新手站长放TXT的时候,文件有几兆甚至几十兆,站群读取txt数据的时候CPU会很高,甚至阻塞。新闻采集为了让网站和站群运行更高效,小编建议大家放置txt文件大小不要超过50kb,不仅文章、关键词 域名等文本txt也应该严格遵循这个文件大小。
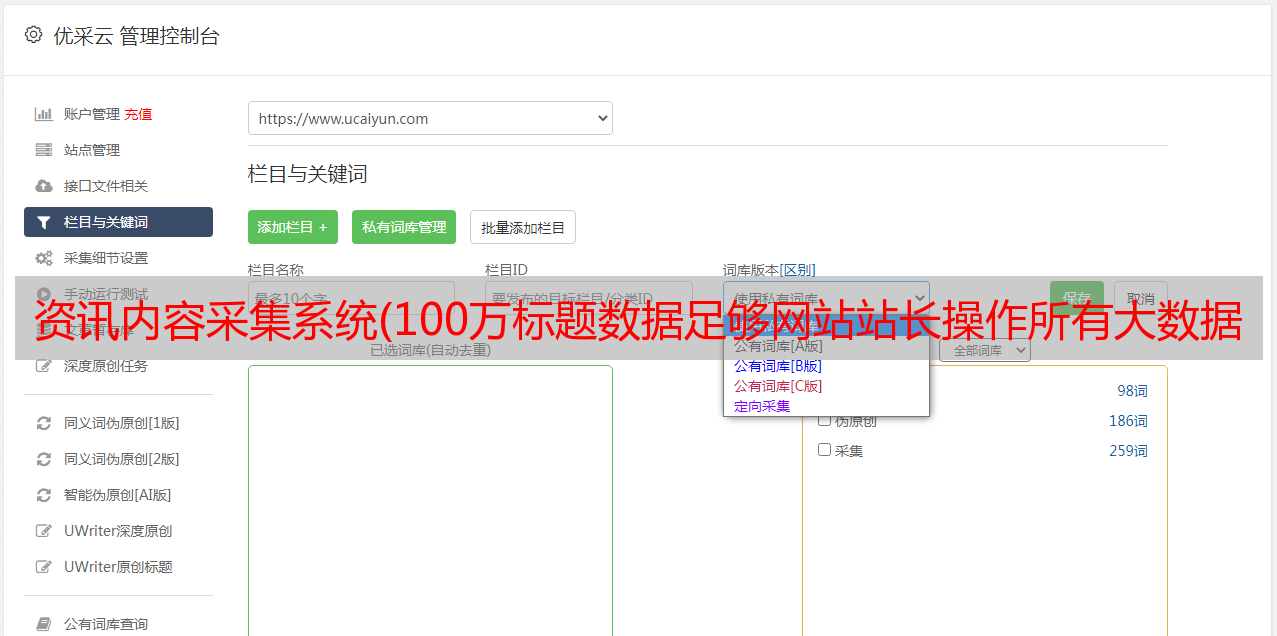
在第一个采集之后,新闻采集会建立一个标题文本库,采集接收到的标题不会重复采集,接收到的标题新闻采集 不再重复。是独一无二的,永远不会重复。 100万条头条数据足以让网站站长操作所有大数据站群,无论是个人网站,还是内页站群,目录站群@ >、新闻热词站群、新闻采集都能满足你的需求。
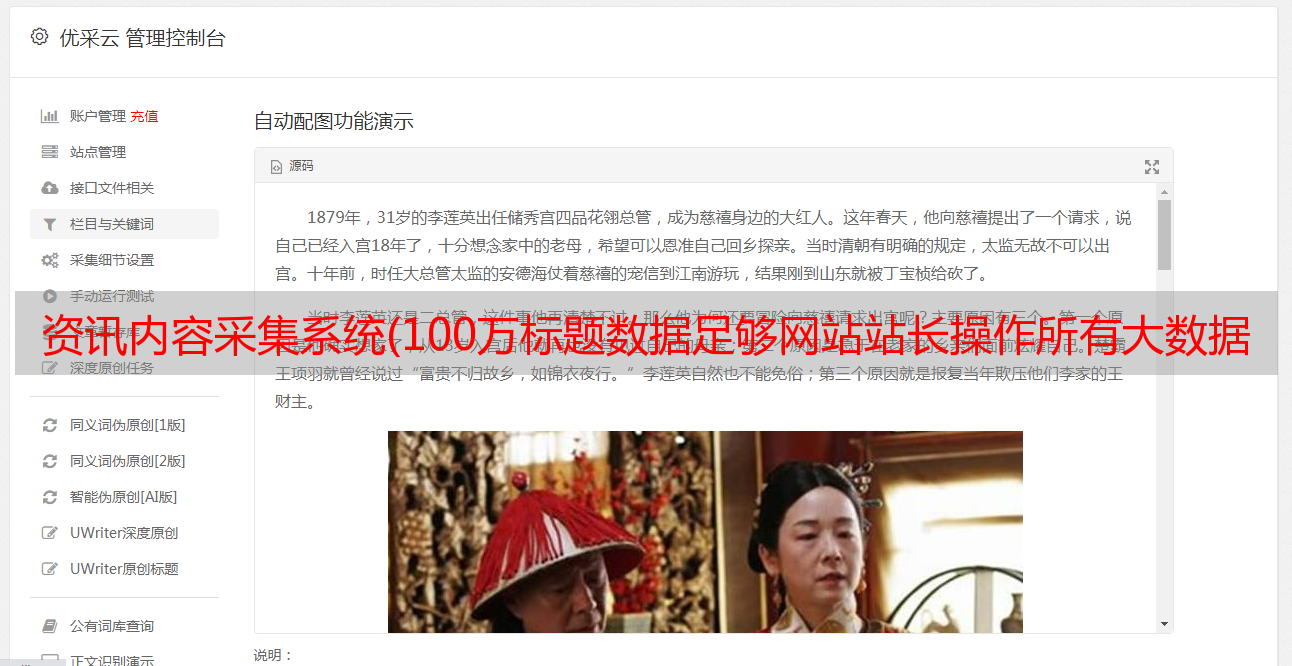
拥有新闻采集的站长不再需要编写采集规则,因为不是每个人都可以,也不适合所有网站。新闻采集也可以采集文章不收录,一般网站可以采集。新闻采集6大功能:查看收录、查看页面状态、查看收录文章、查看所有文章、判断原创度数、设置文章字数。
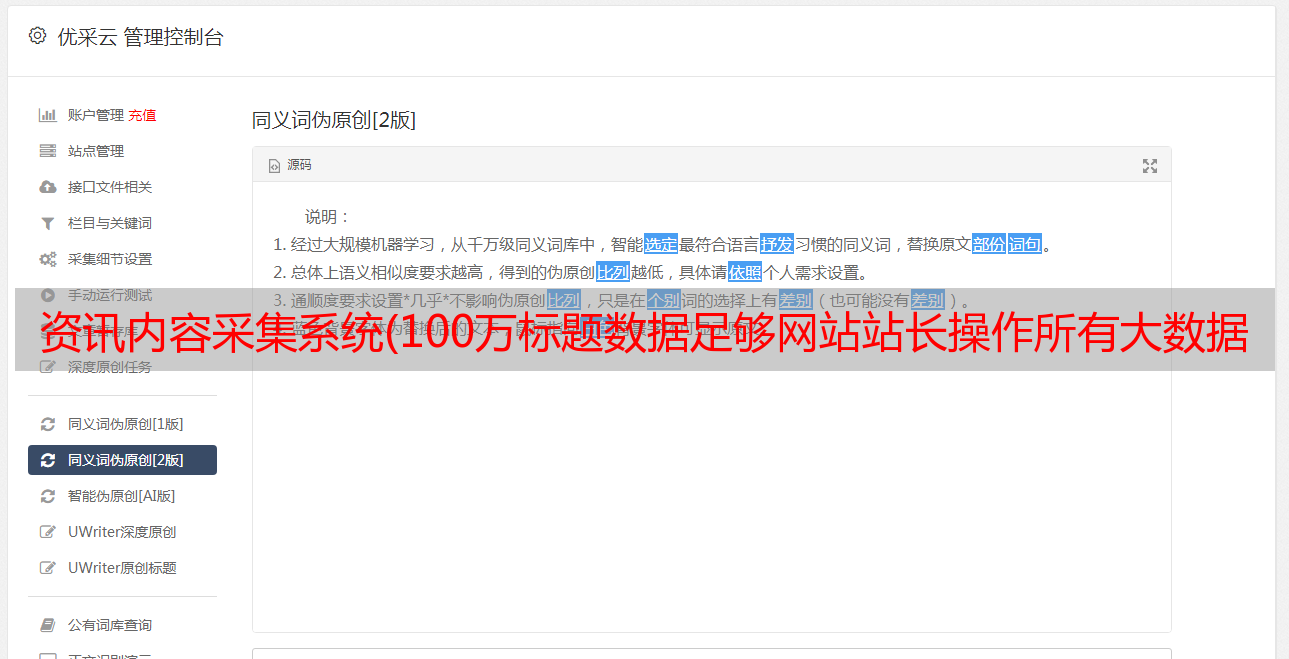
使用智能采集,您可以在不编写采集规则(正则表达式)的情况下采集新闻内容。无限采集功能,可以采集远程图片到本地,自动选择合适的图片生成新闻内容缩略图。新闻采集所有新闻页面均由静态页面(.htm文件)生成,大大提高了服务器的负载能力(也可根据需要生成.aspx、shtml等类型文件)。 RSS新闻采集可以转成静态页面文件,新闻采集集成了企业级流量分析统计系统,让站长知道网站的访问状态。新闻采集WYSIWYG采集、智能内存采集、无重复采集、强大实时采集、分页批处理采集等。
实现原理
新闻采集也在这里与你分享。 news采集通过python获取html非常方便,只需要几行代码就可以实现我们需要的功能。代码如下:
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
page.close()
返回html
我们都知道html链接的标签是“a”,链接的属性是“href”,即获取html中所有的tag=a,attrs=href值。查阅资料后,本来打算用HTMLParser,也写了。但是它有个问题,就是不能处理汉字。
类解析器(HTMLParser.HTMLParser):
def handle_starttag(self, tag, attrs):
如果标签 == 'a':
对于 attr,attrs 中的值:
如果 attr == 'href':
打印值
os.getcwd()#获取当前文件夹路径
os.path.sep#当前系统路径分隔符windows下为“\”,linux下为“/”
#判断文件夹是否存在,如果不存在则新建文件夹
如果 os.path.exists('newsdir') == False:
os.makedirs('newsdir')
#str() 用于将数字转换为字符串
i = 5
str(i)

