网页爬虫抓取百度图片(爬虫项目学习之爬取地址特点通过右键的分析方法(图))
优采云 发布时间: 2022-02-26 10:23网页爬虫抓取百度图片(爬虫项目学习之爬取地址特点通过右键的分析方法(图))
1、总结
目的:学习爬虫项目,使用requests方法爬取*敏*感*词*美容吧每篇帖子的图片,并保存在本地。
方法:首先通过requests请求美容吧网页的内容;二、通过xpath方法清理数据,获取每个post的url地址;再次请求每个帖子的地址,从每个帖子地址爬取图片链接;最后,请求图像数据并将数据以二进制格式保存在本地。
2、网页分析
如下图,这是本次爬取的目标网站,百度美吧,要求:爬取每个帖子里的图片,保存到本地。爬取网站首先需要分析网站的特征。需要分析的内容包括:网站页面的特征、post url地址的特征、图片链接地址的获取方式。以下是我需要分析的内容:
2.1 美容吧网页特色
美容棒:%E7%BE%8E%E5%A5%B3&ie=utf-8&pn=0
观察可以看出kw为搜索内容,pn为页码,第一页为0,第二页为50,所以页码的公式为pn=(页数-1)*50。
2.2 Post url 地址功能
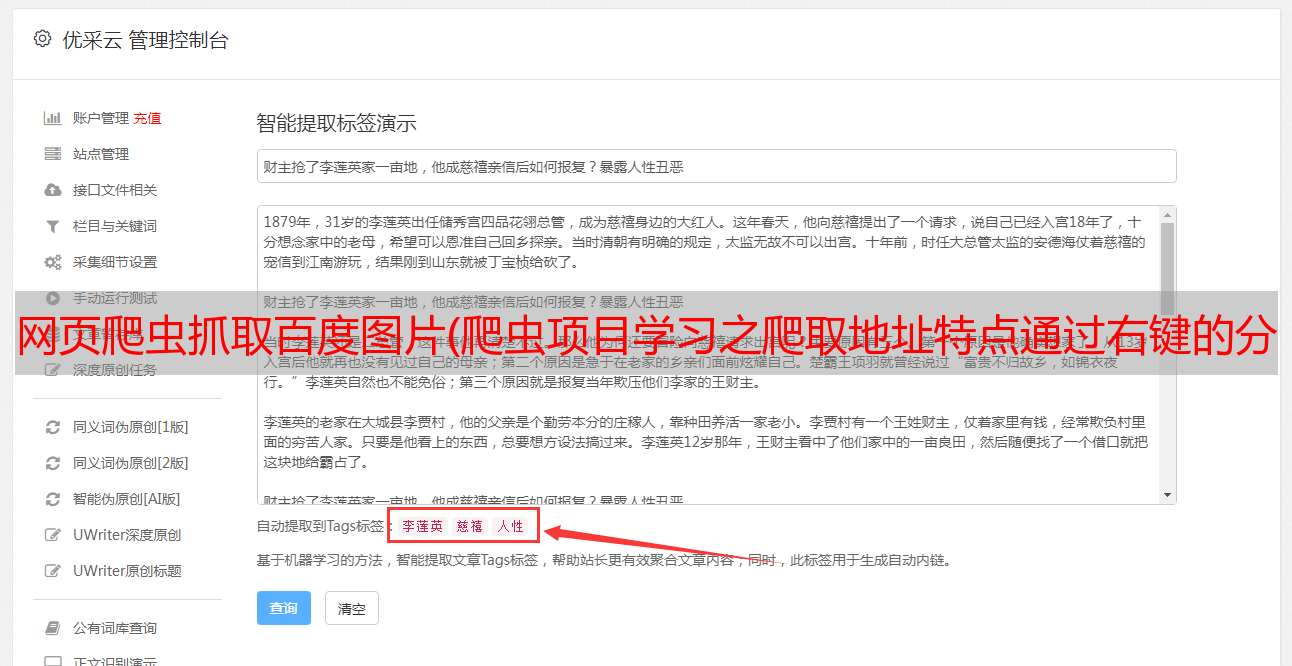
通过右键-勾选,可以查看网页的源代码信息,从中我们可以定位到每个帖子的代码,如下图:
可以看到,点击“我真的很漂亮”的帖子,定位到代码,可见帖子的url地址在这段代码中;然后点击href =p/6593341944,发现跳转到帖子“我真的很漂亮”太漂亮了,此时的url地址是:,所以可以发现帖子的地址主要是由两部分组成:+href的内容,所以我们只需要爬取href =p/6593341944的内容,然后拼接,就可以得到每个帖子的地址。
通过xpath_help工具,写: //div[@class="threadlist_title pull_left j_th_tit "]/a/@href 得到每个url地址的一部分。
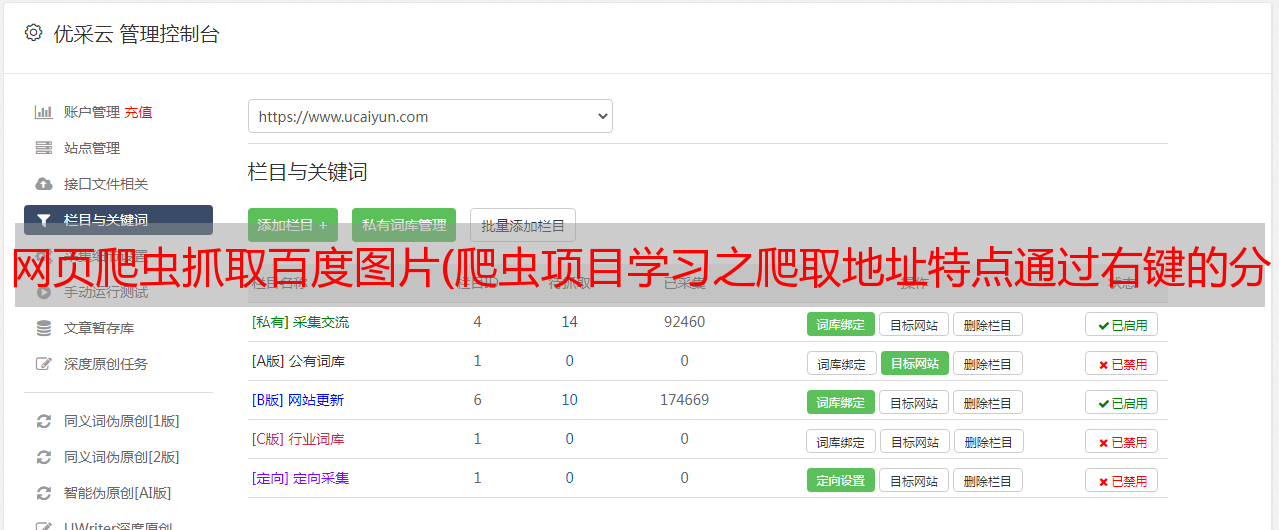
2.3 获取帖子的图片链接
获取每个帖子的链接,通过类似操作找到帖子中图片的链接地址,如下图定位到图片的链接
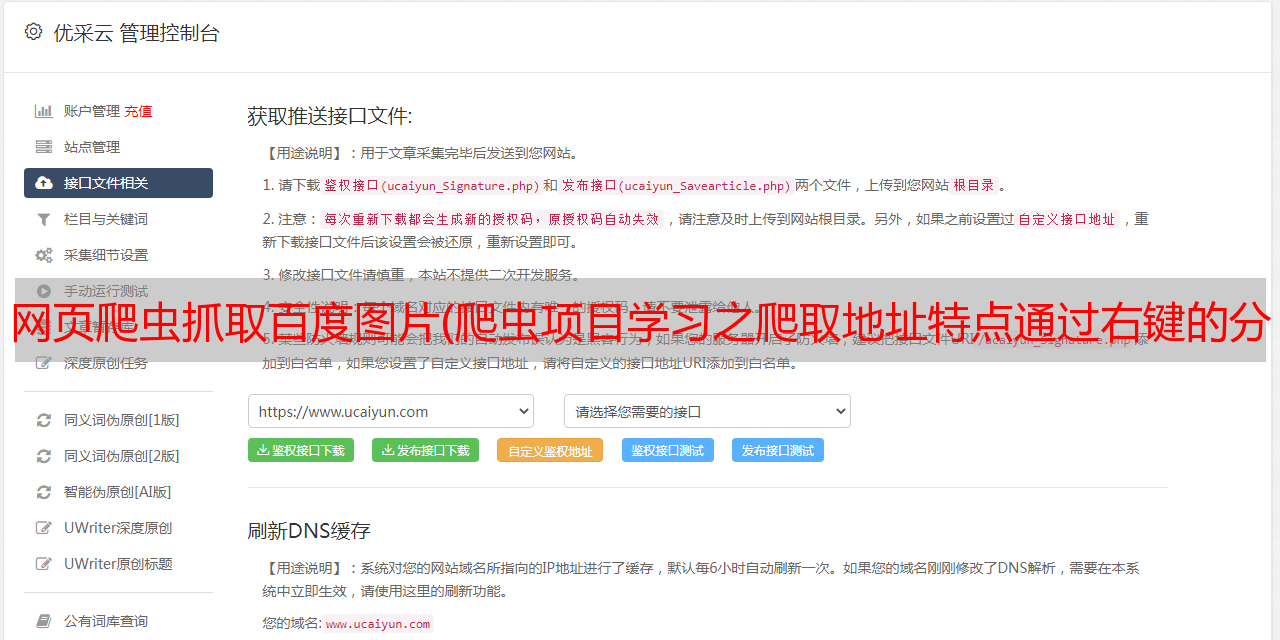
同理,通过xpath_help匹配图片链接,代码为://img[@class="BDE_Image"]/@src
3、程序代码:
# -*- 编码:utf-8 -*-import requestsfrom lxml import etreeimport os#爬虫类BtcSpider(object):def __init__(self):#爬取美女图片#解析:美妆吧url地址,pn值决定页码, pn = 0 第一页, pn = 50 第二页...self.url = '%E7%BE%8E%E5%A5%B3&ie=utf-8&pn={}'self.headers = { ' User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',}os.makedirs('美颜图片',exist_ok=True)self.dir = '美颜图片\'#发送请求def get_response(self,url):response = requests.get(url,headers = self.headers)data = response.textreturn data#发送请求获取网页数据,数据以二进制内容形式读取 def get_data(self,url) :data = requests.get(url,headers = self.headers).contentreturn data#parse data, 封装 xpathdef get_xpath(self,html,pattern):#build tree p = etree.HTML(html)#解析网页内容,获取url_listsresult = p.xpath(pattern)return result#下载图片 &def download_src(self,url):html = self.get_response(url)html = html.replace ("
内容

