querylist采集微信公众号文章(一个就是ip代理的质量不行,哪里不行呢?)
优采云 发布时间: 2022-02-22 21:21querylist采集微信公众号文章(一个就是ip代理的质量不行,哪里不行呢?)
关注上一篇未完成的爬虫项目,继续更新最终代码片段
最近比较忙,没时间更新文章的下一篇。就在这几天,有时间重新调整代码,更新里面的细节。发现调整代码有很多问题,主要是ip代理质量不好,哪里不好,往下看就知道了。三、获取每篇文章文章的阅读和点赞数
想要获取文章的阅读量,在微信公众平台里面直接点击,是获取不了文章的阅读量的,测试如下:
然后我们可以去fiddler查看这个文章的包,可以看到这个包是
文章的内容可以从body的大小来判断,也就是文章的内容。
但是我们无法从这个路由中获取文章的阅读量,因为这个请求是一个get请求。如果要获取文章的阅读点赞,第一个请求是post请求,然后需要携带三个重要参数pass_ticket、appmsg_token、phoneCookie。要获取这三个参数,我们要把公众号中的文章放到微信中点击,然后从fiddler查看抓包情况。
我们去fiddler看一下抓包情况:我们可以看到上面还有一个get请求,但是下面添加了一个post请求的内容,然后看一下携带的参数,这三个是重要的得到我们想要的阅读量参数,以及响应的内容,可以看出已经获取到文章的阅读量信息。现在我们可以拼接参数来发送请求了。
#获取文章阅读量
def get_readNum(link,user_agent):
pass_ticket ="N/Sd9In6UXfiRSmhdRi+kRX2ZUn9HC5+4aAeb6YksHOWNLyV3VK48YZQY6oWK0/U"
appmsg_token = "1073_N8SQ6BkIGIQRZvII-hnp11Whcg8iqFcaN4Rd19rKluJDPVMDagdss_Rwbb-fI4WaoXLyxA244qF3iAp_"
# phoneCookie有效时间在两个小时左右,需要手动更新
phoneCookie = "rewardsn=; wxtokenkey=777; wxuin=2890533338; devicetype=Windows10x64; version=62090529; lang=zh_CN; pass_ticket=N/Sd9In6UXfiRSmhdRi+kRX2ZUn9HC5+4aAeb6YksHOWNLyV3VK48YZQY6oWK0/U; wap_sid2=CNqTqOIKElxWcHFLdDFkanBJZjlZbzdXVmVrejNuVXdUb3hBSERDTTBDcH*敏*感*词*VAxTTFIeEpwQmdrWnM1TWRFdWtuRUlSRDFnUzRHNkNQZFpVMXl1UEVYalgyX1ljakVFQUFBfjCT5bP5BTgNQAE="
mid = link.split("&")[1].split("=")[1]
idx = link.split("&")[2].split("=")[1]
sn = link.split("&")[3].split("=")[1]
_biz = link.split("&")[0].split("_biz=")[1]
url = "http://mp.weixin.qq.com/mp/getappmsgext"
headers = {
"Cookie": phoneCookie,
"User-Agent":user_agent
}
data = {
"is_only_read": "1",
"is_temp_url": "0",
"appmsg_type": "9",
'reward_uin_count': '0'
}
params = {
"__biz": _biz,
"mid": mid,
"sn": sn,
"idx": idx,
"key": '777',
"pass_ticket": pass_ticket,
"appmsg_token": appmsg_token,
"uin": '777',
"wxtoken": "777"
}
success = False
a=1
while not success:
ip_num = ranDom_ip()[0] # 使用不同的ip进行阅读、点赞量的获取
try:
print("获取阅读量使用ip:%s"%ip_num)
content = requests.post(url, headers=headers, data=data, params=params, proxies=ip_num,timeout=6.6)#设置超时时间5秒
time.sleep(4)
content = content.json()
print(link)#文章链接
print(content)#文章内容
if 'appmsgstat' in content:
readNum = content["appmsgstat"]["read_num"]
like_num=content["appmsgstat"]["old_like_num"] #点赞量
zai_kan=content["appmsgstat"]["like_num"] #在看量
else:
readNum = 0
like_num = 0
success=True
return readNum, like_num
except:
print("获取阅读量ip出现问题,更换ip进入第二次循环获取!!!")
a+=1
# if a%5==0:
content = requests.post(url, headers=headers, data=data, params=params,timeout=5)
time.sleep(3)
content = content.json()
print(link) #文章链接
print(content)#文章内容
if 'appmsgstat' in content:
readNum = content["appmsgstat"]["read_num"]
like_num = content["appmsgstat"]["old_like_num"] # 点赞量
zai_kan = content["appmsgstat"]["like_num"] # 在看量
else:
print('文章阅读点赞获取失败!')
readNum=0
like_num=0
# else:
# continue
return readNum, like_num
需要注意的是,在这三个重要参数中,phoneCookie 是时间敏感的,需要手动更新,这是最麻烦的,就像 cookie 一样。通过传入的文章链接,我们可以在链接中提取一些有用的参数,用于后期拼接post请求。不好,所以代码略显冗余(需要改进)。
四、使用UA代理和IP代理设置每个文章的爬取速度
通过以上操作,我们基本可以爬取文章的链接、标题、链接,完成初步需求:
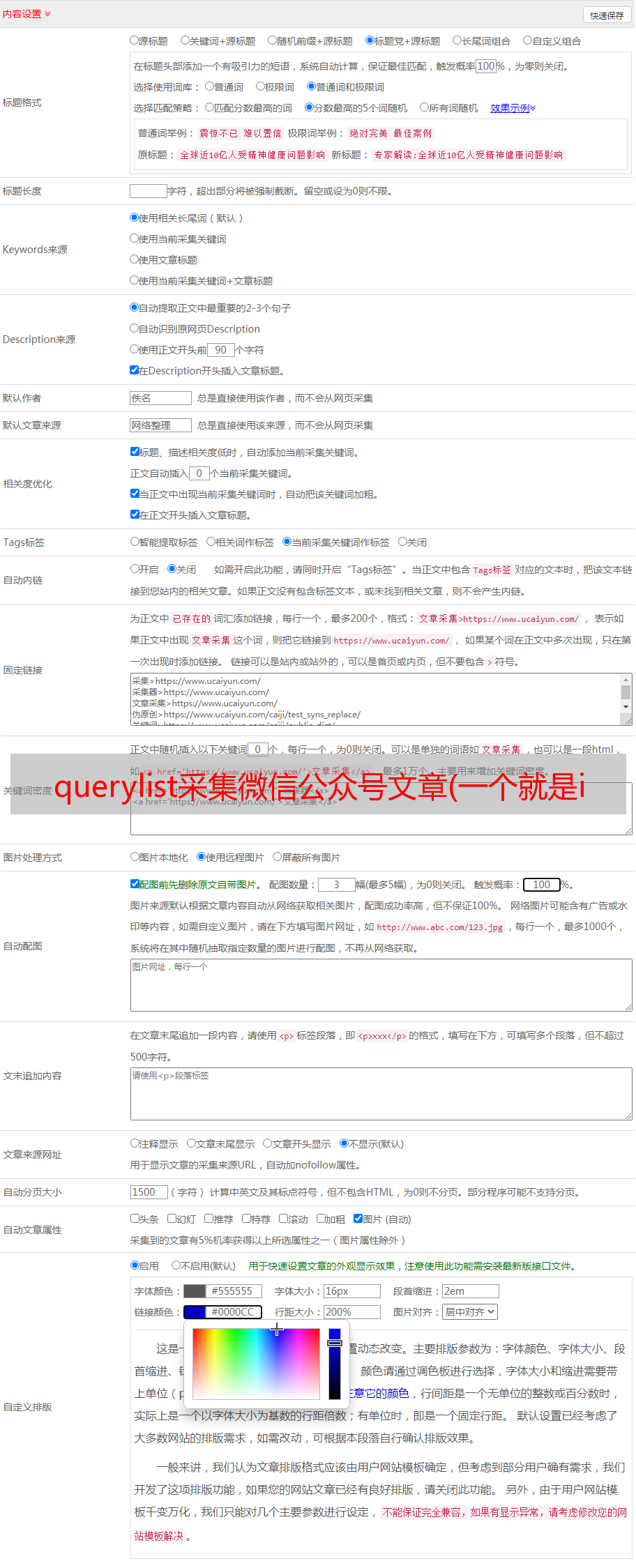
但是我在开心爬的时候发现很快就被反爬发现了,直接屏蔽了我公众号的请求。
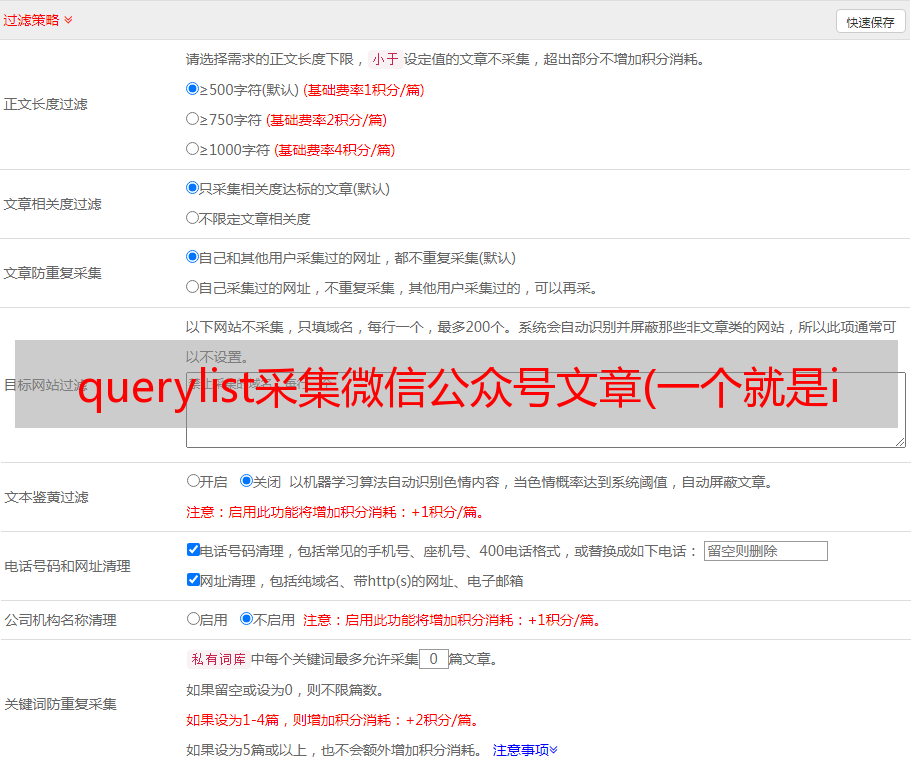
这时候就想到了ip proxy来识别我们是否反爬,主要是从ip和UA,所以后来做了一个ip代理池,从一些ip网站爬取ip,通过了代码大赛选择有用的 IP 形成 IP 池。贡献一段我爬ip的代码,感兴趣的朋友可以直接试试:
import requests
from bs4 import BeautifulSoup
import json
import random
import re
ip_num=[]
url="http://www.66ip.cn/1.html"
headers={
"Host": "www.66ip.cn ",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Referer": "http://www.66ip.cn/index.html",
"Cookie": "Hm_lvt_1761fabf3c988e7f04bec51acd4073f4=1595575058,1595816310; Hm_lpvt_1761fabf3c988e7f04bec51acd4073f4=1595832351",
}
content=requests.get(url,headers=headers)
content.encoding="gbk"
html=BeautifulSoup(content.text,"html.parser")
# print(html)
content=html.find_all("table",{"border":"2px"})
ip=re.findall('(\d{1,4}.\d{1,4}.\d{1,4}.\d{1,4})',str(content))
port=re.findall('(\d{1,5})',str(content))
for i in range(len(port)):
ip_num.append(ip[i]+":"+port[i])
proxies = [{'http':ip_num[num]} for num in range(len(ip_num))]
for i in range(0, len(ip_num)):
proxie = random.choice(proxies)
print("%s:当前使用的ip是:%s" % (i, proxie['http']))
try:
response = requests.get("http://mp.weixin.qq.com/", proxies=proxie, timeout=3)
print(response)
if response.status_code == 200:
# with open('ip.txt', "a", newline="")as f:
# f.write(proxie['http'] + "\n")
print("保存成功")
except Exception as e:
print("ip不可用")
我将过滤掉网站的ip,保存在本地,然后通过写一个函数来创建一个ip地址:
#代理池函数
def ranDom_ip():
with open('ip.txt',"r")as f:
ip_num=f.read()
ip_list=ip_num.split("\n")
num=random.randint(0,len(ip_list)-1)
proxies = [{'http': ip_list[num]}]
return proxies
然后在函数循环中调用这个ip代理的函数,就可以不断更新自己使用的ip。这是给你的流程图,所以我们可以知道在哪里使用ip代理功能。
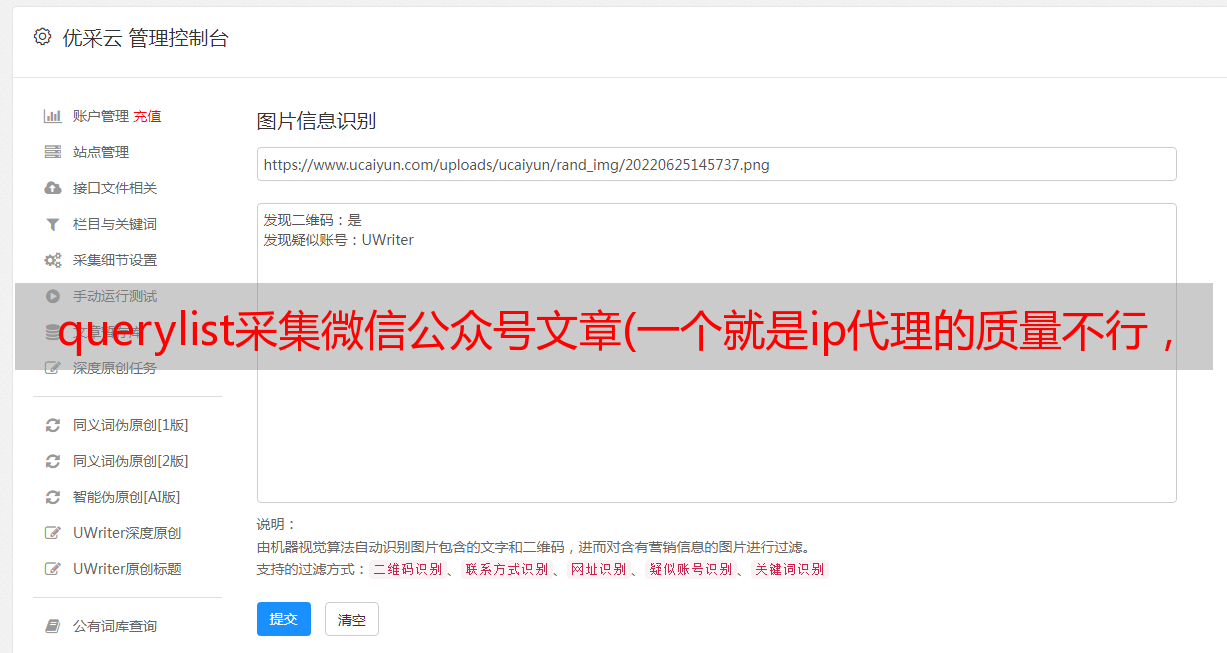
通过将以上三个地方加入到我们使用的ip池中,不断变化的ip就是成功绕过反爬的点。当我们不断更改 ip 时,我仍然感到有点不安全。我觉得UA也需要不断更新,所以我导入了一个ua代理池
from fake_useragent import UserAgent #导入UA代理池
user_agent=UserAgent()
但需要注意的是,我们不能更改headers中的所有UA,我们只能添加UA代理的一部分,因为公众号的请求是由两部分组成的,我们只能添加前半部分。
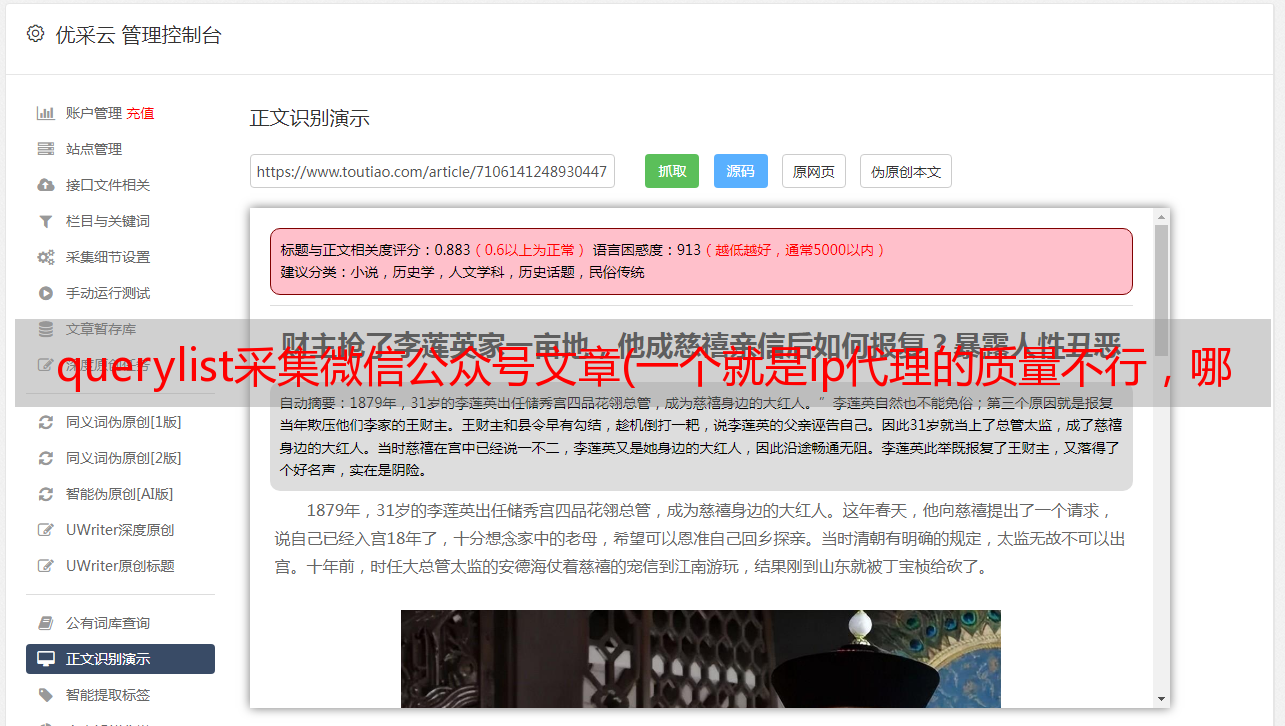
就像下面的请求头一样,我们的Ua代理只能替换前半部分,这样Ua也是不断变化的,而且变化的位置和上面ip函数的位置一样,我们就可以实现ip,UA在之后每个请求都是不同的。
headers={
"Host":"mp.weixin.qq.com",
"User-Agent":user_agent.random +"(KHTML, like Gecko) Version/4.0 Chrome/78.0.3904.62 XWEB/2469 MMWEBSDK/200601 Mobile Safari/537.36 MMWEBID/3809 MicroMessenger/7.0.16.1680(0x27001033) Process/toolsmp WeChat/arm64 NetType/WIFI Language/zh_CN ABI/arm64"
}
在这两个参数之后,我们基本可以控制不被反爬虫发现了,但是还有一点很重要,就是控制爬取的速度,因为ip和ua是不断变化的,但是你公众号的cookie不能被改变。如果爬取速度过快,会识别出访问你公众号某个界面的频率太快,直接禁止你公众号搜索的界面文章,所以我们需要做一个请求延迟,那么在这个过程中我们哪里可以做得更好呢?可以在流程图中标记的位置进行延迟。
这样既能控制速度,又能防止本地ip和ua被发现,妙不可言。缺点是我没有找到高质量的ip池。我用的是free ip,所以很多都是在换ip的过程中拿不到的。读取量方面(穷人叹),如果有高级IP代理池,速度是非常快的。完整的代码不会在这里粘贴。有兴趣我可以私发。

