标签归档: 大数据语义智能分析平台
优采云 发布时间: 2020-08-06 06:02
NLPIR大数据语义智能分析平台由北京理工大学大数据搜索与挖掘实验室张华平博士领导. 它最近推出了一个新版本,这是一个建议. 张华平博士最著名的产品是ICTCLAS中文分词平台. 相信这将帮助您了解NLPIR大数据语义智能分析平台. 以下摘自“ NLPIR大数据语义智能分析平台新版本上线”.
NLPIR大数据语义智能分析平台满足了大数据内容获取,编辑,挖掘和搜索的综合需求,并集成了准确的网络采集,自然语言理解,文本挖掘和语义搜索的最新研究成果. 它已经为世界服务了18年. 在大数据时代,400,000个机构用户是进行语义智能分析的重要工具.
NLPIR大数据语义智能挖掘平台,满足大数据内容处理的需求,它集成了精确的网络采集,自然语言理解,文本挖掘和网络搜索技术,并提供客户端工具,云服务和二次开发接口. . 开发平台由多个中间件组成. 每个中间件API都可以无缝集成到客户的各种复杂应用系统中. 它与Windows,Linux,Android,Maemo5,FreeBSD等不同的操作系统平台兼容. 可以用于Java,C,C#和其他使用的开发语言.
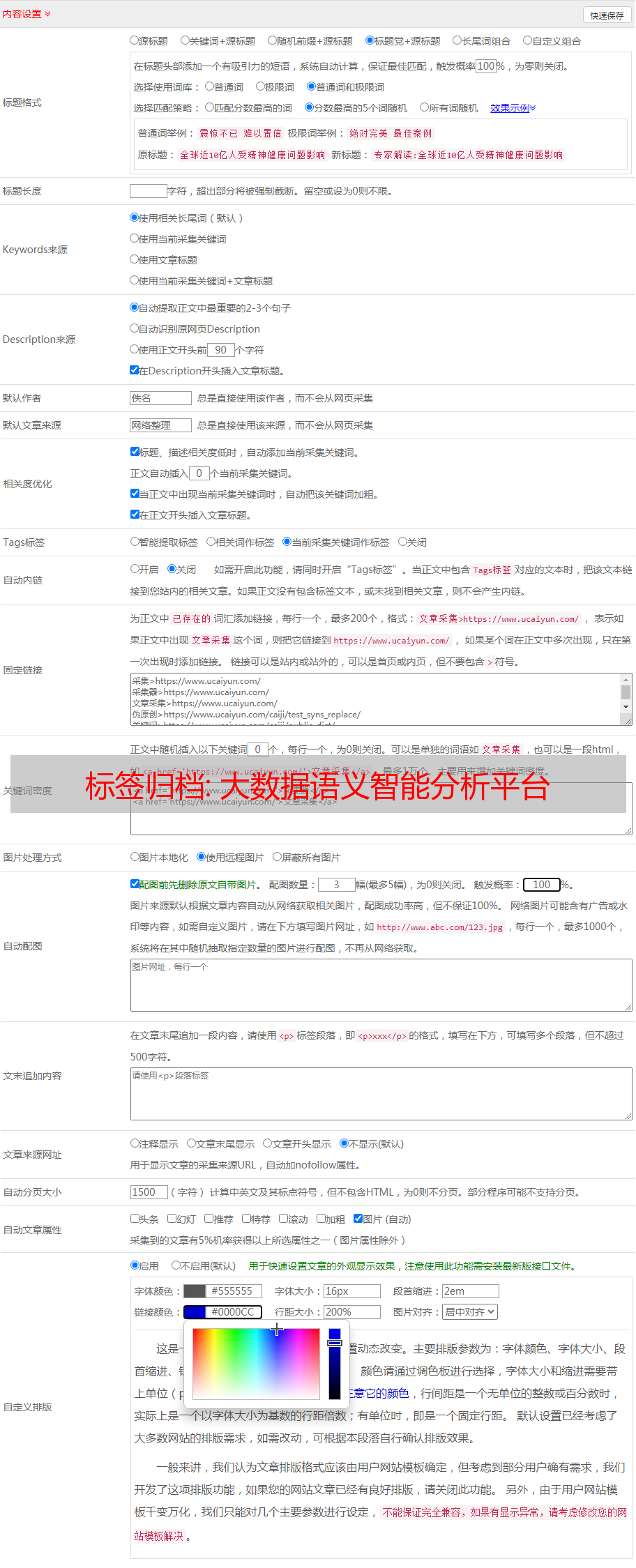
NLPIR大数据语义智能分析平台的十三个功能:
1. 准确采集: 通过两种方式实时准确地从*敏*感*词*互联网采集海量信息: 主题采集(根据信息需求进行主题采集)和网站采集(给定URL列表的内部定点采集功能)
2. 文档提取: 从多种主流文档格式(例如doc,excel,pdf和ppt)中提取文本信息. 信息提取准确,效率满足大数据处理要求.
3. 新词发现: 从文本中发现新词和新概念. 用户可以使用它们来编译专业词典. 他们还可以对其进行编辑和标记,然后将其导入到分词词典中,以提高分词系统的准确性并适应新的语言更改.
4. 批量单词分割: 原创语料库的单词分割,自动识别未注册的单词(例如名称,地名和组织名称),新单词标记和词性标记. 然后在分析过程中,导入用户定义的字典.
5. 语言统计: 根据分割和标注结果,系统可以自动对一元词的频率进行统计,对二元词的转移概率进行统计. 对于常用术语,将自动给出相应的英语解释.
6. 文本聚类: 它可以自动分析来自*敏*感*词*数据的热点事件,并提供事件主题的关键功能描述. 它还适用于长文本和短文本(例如,短文本和微博)的热点分析.
7. 文本分类: 根据规则或训练方法对大量文本进行分类,可用于新闻分类,简历分类,邮件分类,办公文档分类,区域分类等许多方面.
8. 摘要实体: 对于单个或多个文章,将自动提取内容摘要,并提取人员名称,地点,组织,时间和主题关键字;方便用户快速浏览文本内容.
9. 智能过滤: 智能过滤和审查文本内容的语义,内置中国最完整的单词数据库,智能识别各种变形: 变形,声音变化,传统和简化等,并在语义上准确消除歧义.
10. 情感分析: 对于预先指定的分析对象,系统会自动分析大量文档的情感趋势: 情感极性和情感价值测量,并在原文中给出正负分和句子示例.
11. 文档重复数据删除: 快速,准确地确定文件集合或数据库中是否存在内容相同或相似的记录,同时找出所有重复的记录.
12. 全文搜索: 支持各种数据类型,例如文本,数字,日期,字符串等,在多个字段中高效搜索,支持查询语法(例如AND / OR / NOT和NEAR接近),并支持维吾尔文,藏文和蒙古文搜索多种少数民族语言,例如阿拉伯语,阿拉伯语和韩语.
13. 代码转换: 自动识别内容的代码,并将代码统一转换为其他代码.
欢迎下载和使用.
NLPIR大数据语义智能分析平台白皮书:
(大约3MB)
NLPIR大数据语义智能分析平台:
(约160MB)

