文章内容采集(4.网页内容获取规则上面介绍了列表设置的方法(图))
优采云 发布时间: 2022-02-19 13:01文章内容采集(4.网页内容获取规则上面介绍了列表设置的方法(图))
4.网页内容获取规则
上面介绍了列表设置的方法。接下来,我们进入内容获取规则的设置。如果采集是上菜,上面前三步的作用只是为后面的主菜做开胃菜。带领。接下来介绍如何从目标站传输文章内容采集。这一步是整个采集的核心部分。
继续返回织梦的PHP教程列表,在列表中随机打开一个文章。这里我们以“正则表达式”的文章为例: 将地址复制到“预览网址”;因为所有织梦文章都没有分页,所以这里的分页不需要设置,直接进入“固定采集项目”页面
(注意:如果采集的内容收录分页,只需要在分页导航部分设置匹配规则即可。有全部列出的分页列表,有上下页,也有不完整的分页列表根据内容可设置)
[td]引用如下:
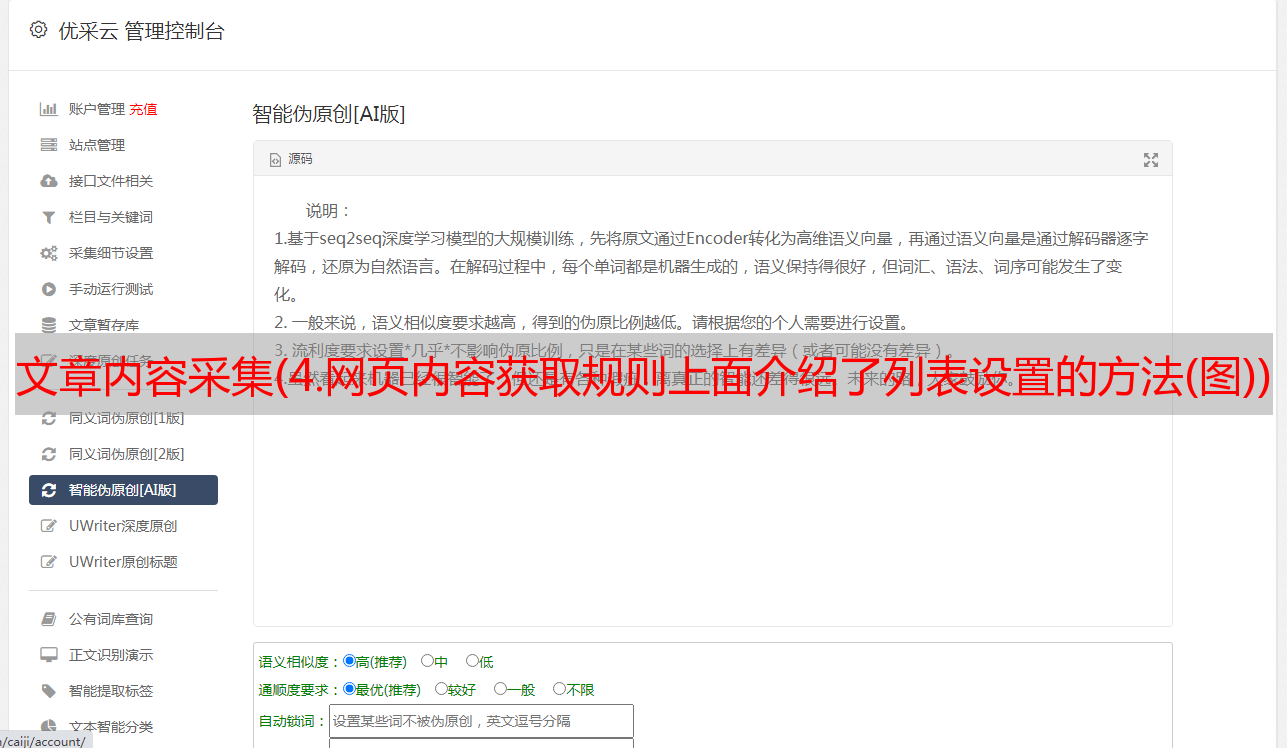
所有列出的分页列表:分页内容列出了所有的链接,如下图
上下翻页形式或不完整的分页列表:单页显示当前分页内容,不完整的显示列表形式
[/td]
5. 修复采集项目
在这一步,我们开始分析页面的源代码。 采集 无非就是分析 HTML 页面的结构来获取我们需要的内容。因此,要求我们对HTML代码有一定的了解,通过查看页面源文件可以找到需要的内容。最好多开几页分析一下。
建议您使用 Dreamweaver 分析。在分析页面代码的时候,多使用搜索功能会方便很多,尤其是找到标签后,搜索一下是否有重复,减少分析错误。
1)文章标题:这个页面的标题是“正则表达式”复制一下,在Dreamweaver中按Ctrl+F搜索全部,有30条记录。由于其唯一性,这里我们选择第105行的“正则表达式”标签,将其复制到“固定采集项”文章标题的匹配规则中,并将标题替换为关键字“ [content]" ,最终成为 [content]。
2)作者:以作者为关键字继续搜索,只有110行有唯一出现,将它们与alluse前后的标签一起复制到匹配规则中,用[content]替换地点是 采集 .
3) 来源:同上,找到第109行的标签,复制,用[content]替换你想要的地方采集。如果源中收录超链接标签,想要去掉,那么在过滤规则框中,填写以下规则过滤掉:
]*)>

