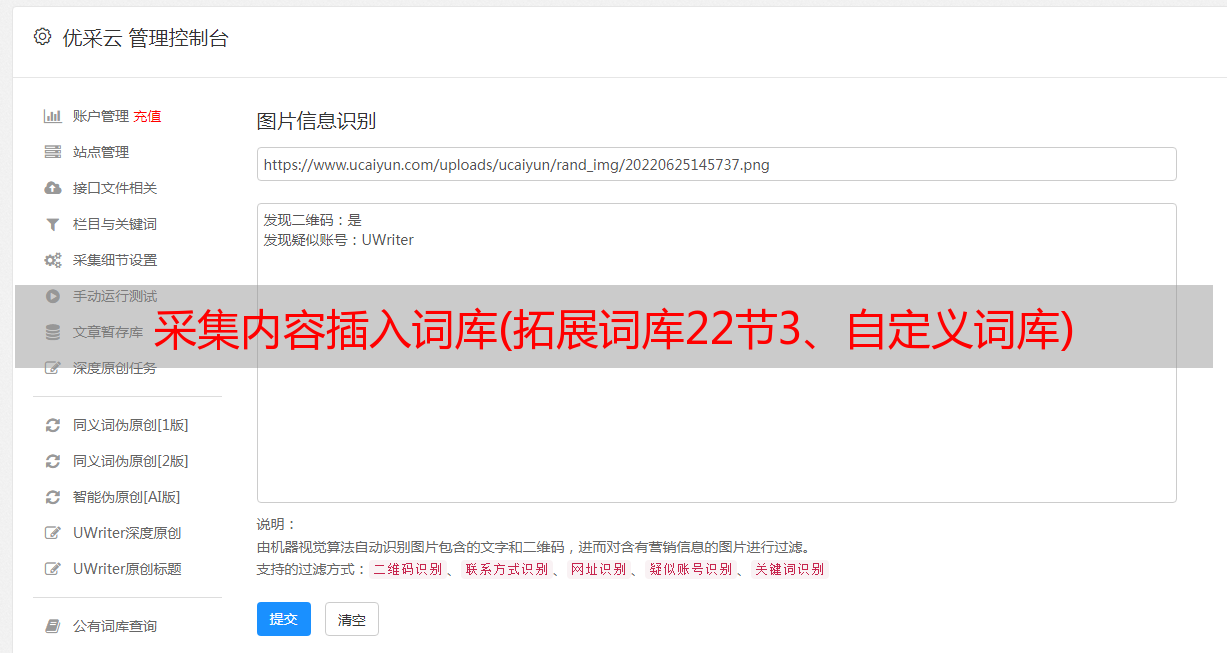
采集内容插入词库(拓展词库22节3、自定义词库)
优采云 发布时间: 2022-02-16 08:09采集内容插入词库(拓展词库22节3、自定义词库)
【ES从入门到实战】2十三、全文搜索-ElasticSearch-分词-自定义扩展词库
继续第 22 节
3),自定义词库
ik tokenizer 的默认分词不能满足我们的需求。对于一些新的网络术语,ik tokenizer 将无法准确识别分词,例如:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "乔碧萝殿下"
}
分词后显示如下,可以看到ik分词器无法识别“乔碧落”是人名:
在此处插入图像描述
因此,需要自定义扩展词库。
自定义扩展词库,可以修改ik分词器的配置文件,指定一个远程词库,让ik分词器向远程请求获取一些最新的词,这样最新的词将作为最新的词源。分解。
自定义词库有两种实现方式:
自己实现一个服务,处理ik tokenizer的请求,让ik tokenizer向自定义项目发送请求,搭建一个nginx服务器,把最新的词库放到nginx中,让ik tokenizer向nginx发送请求,nginx会ik 分词器返回最新的词典,以便 ik 分词器可以将原创词典与新词典结合起来。
nginx安装参考六、附录-安装nginx
这里我使用第二种方法来自定义词库。您需要在创建 nginx 之前安装它。相关内容请参见第 6 章。
在/mydata/nginx/html/路径下新建es目录,新建词库fenci.txt:
在此处插入图像描述
要访问,您可以请求词库的内容:
在此处插入图像描述
修改/usr/share/elasticsearch/plugins/ik/config/中的IKAnalyzer.cfg.xml
在此处插入图像描述
/usr/share/elasticsearch/plugins/ik/config
IK Analyzer 扩展配置
http://192.168.56.10/es/fenci.txt
在此处插入图像描述
注意:如果打开IKAnalyzer.cfg.xml是乱码,可以先退出当前文件,在命令行输入vi /etc/virc,
然后在文件中添加set encoding=utf-8,保存退出,重新打开IKAnalyzer.cfg.xml。
在此处插入图像描述
原创xml:
IK Analyzer 扩展配置
重启 ES:
docker restart elasticsearch
再次在kibana中进行分词,可以看到之前无法识别的“乔碧萝”现在可以识别为单词了:
在此处插入图像描述
如果以后有新词组,可以直接在上面自定义词库fenci.txt中添加,然后重启ES。
由于之前安装nginx的时候重装了ES,所以需要设置ES的自动启动服务:
docker update elasticsearch --restart=always
参考文献分析
参考:
弹性搜索参考
松紧带
全文搜索引擎 Elasticsearch 入门教程

