wordpress文章采集软件(声明一下wordpress采集插件常见采集规则)
优采云 发布时间: 2022-02-15 20:16wordpress文章采集软件(声明一下wordpress采集插件常见采集规则)
首先需要声明wordpress采集插件需要有一定的采集规则基础。如果你之前没有接触过regularity和xpath,可能看起来有点难,但不要着急!本次博主分享的wordpress采集内容分为两种,一种是0基础初学者也可以直接使用wordpress采集,一种是基于采集规则< @采集 内容。
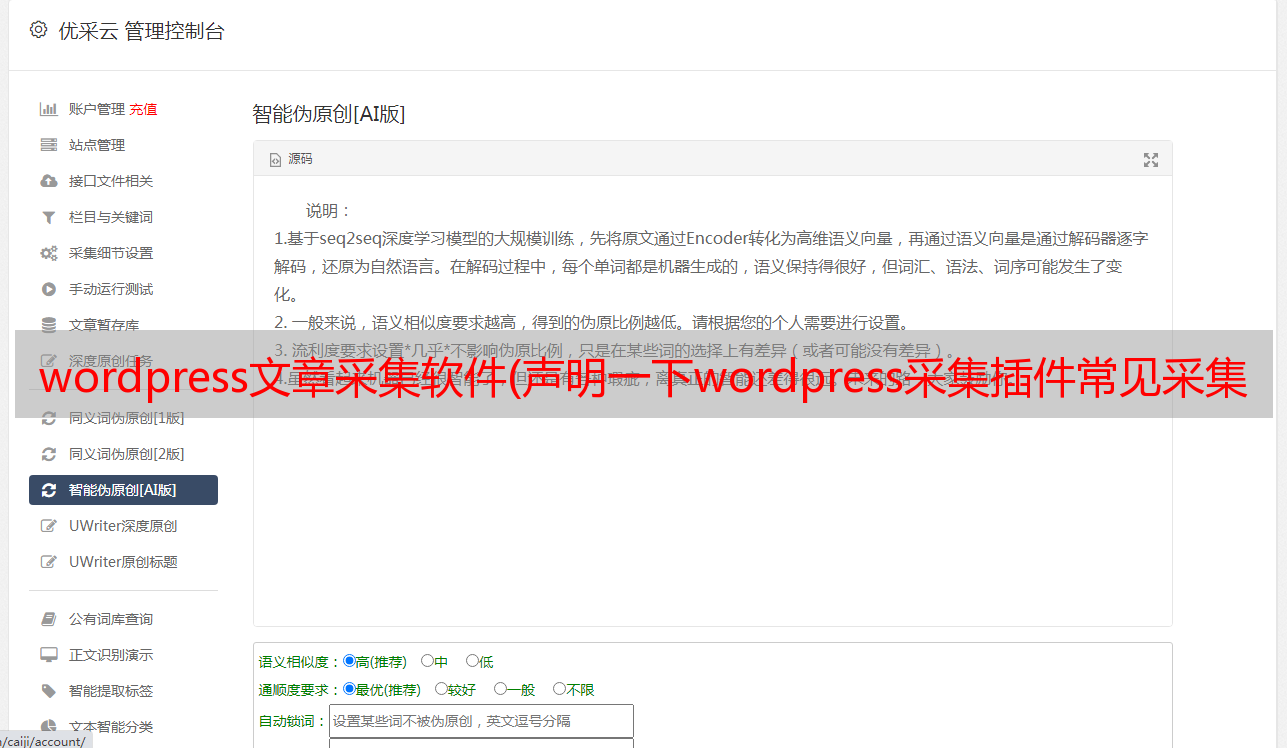
一、wordpress采集插件工具
无需学习更多专业技能,只需几个简单的步骤即可轻松采集内容数据,精准发布站点,用户只需对软件进行简单设置,完成后软件会根据用户设置< @k4@ >内容与图片的高精度匹配,自动执行文章采集伪原创发布,提供方便快捷的内容填充服务!!
与自己编写规则相比,采集 的门槛更低。您无需花费大量时间学习正则表达式或 html 标签。您可以在一分钟内开始。只需输入关键词即可实现采集。一路挂断!设置任务自动执行采集发布任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类工具还是为小白配备了强大的SEO功能,可以通过软件采集自动采集和发布文章,并设置自动下载图片保存到本地或第三方派对。自动内部链接、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“伪原创”。使用这些小的 SEO 功能提高 网站page原创网站收录 的度数。软件工具上还有监控功能,可以通过软件直接查看文章采集的发布状态。目前博主亲测软件是免费的,可以直接下载使用!
二、WordPress 插件常用采集规则
以下是每个任务的设置:
1、任务名称:每个任务的别名方便好记,没有其他作用。
2、入口地址:每个任务爬虫的起始地址。此 URL 通常是主页或列表页。然后,爬虫将从该页面启动 采集。
3. 爬取间隔时间:每个任务(爬虫)运行之间的间隔时间。
4、常规列表页url/常规内容页url:爬虫进入第一个URL(入口URL)后,需要区分哪些内容页需要采集。所以需要设置匹配的内容页面url正则表达式。
爬取还需要知道如何翻页,找到更多的内容页面,所以需要设置列表页url的正则表达式。
所以正则表达式如下:
常规列表页面网址:\/page/[1-9]\d*$
常规内容页面网址:\/[1-9]\d*.html$
如果只需要采集前三页的更新内容,只需将列表页的正则表达式改为\/page/[1-3]$即可。
配置这两个参数时,可以打开“正则表达式在线测试”页面进行测试。
5、 文章Title(xpath)/文章Content(xpath):进入内容页面后,爬虫要选择要爬取的内容,比如文章@的标题> 和 文章 @ 的正文的标题。所以你需要设置xpath来告诉爬虫。
6、内容开始字符串/内容结束字符串:一般网站会有广告,或者内容中混入了一些其他的东西,所以我们需要过滤掉这些内容,只保存我们需要的部分。而这部分无用的东西(广告、分享按钮、标签等)大多在文章的开头或结尾,内容固定。所以我们可以通过简单的字符串过滤掉。
7、文章图片:采集插件可以自动将文章中出现的图片保存到本地,默认是按年月保存到文件夹中,图片的标签将设置为 文章 标题。如果不需要本地保存,可以选择“不处理”。
8、 文章类别:选择要保存到的类别。像 wordpress 一样,您可以选择多个类别。
9、文章标签:每个任务可以单独设置标签,多个标签用|分隔。
10、发布方式:可选择“立即发布”或“放入草稿箱”。
爬取线程数:此选项根据自己的主机配置设置。如果在单独的主机上,可以设置为多线程采集,比如同时开启10个线程。如果是在虚拟主机上,不要设置太大,否则CPU占用率太高,网站会被阻塞。
Crawl Delay:每页采集传完后的延迟,防止采集过快。该参数还用于防止 网站 虚拟主机和 采集 中的 网站 因为 采集 太快而被阻塞。
博主目前正在使用上述软件来维护他们的网站。收录目前有90万左右,重量稍微低一点,只有4个重量。好在方便快捷。看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!关注博主,每天为你带来不一样的SEO知识。你的一举一动都会成为小编源源不断的动力!

