网页数据抓取(数据可视化(Datavisualization)中提取制作的人物关系图)
优采云 发布时间: 2022-02-12 22:12网页数据抓取(数据可视化(Datavisualization)中提取制作的人物关系图)
前提介绍:首先感谢@drizzt 协助我爬取数据。
本文章介绍了数据可视化的一些具体应用。
使用的主要工具有 Python(抓取和分析数据)、Gephi(数据可视化软件)
(另外:我将介绍两个在Facebook上抓取数据的应用程序(Netvizz v1.42))第一张图:
这是五一粉丝-mily(原May Day Fan-mily)Facebook Group制作的社交网络图,作为数据采集的来源。
而这张图是从《哈利波特与魔法石》中提取的人物关系图。
好的!我们正式开始了!!
首先,让我们看看如何获取数据。
数据获取方式主要有两种:
1.直接从网络获取的数据
2、通过数据分析得到的数据
有很多方法可以直接从网络获取数据。像流行的 Python 爬虫或来自 网站 的开放 API。
这里介绍的Netvizz是Facebook开放API提取数据的app。
会翻墙的同学可以直接在Facebook搜索栏输入Netvizz进行查找。
图1
但有一点需要注意,为了保障用户隐私,Facebook 已经关闭了针对个人用户的 API 接口数据提取服务。
因此,我们现在只获取组和页面的数据。
图 2
选择组数据(Group data)后,我们会进入一个选项页面(图3)。这里我们需要填写组id(group id),如何获取组ID?点击next找到组ids here. 回车,填写所选FB组的连接,会得到一串数字,即组ID(图5).
(注意,Data to get 的勾去掉)
图 3
图 4
图 5
然后返回 Netvizz 页面。输入 ID,您就可以抓取了。
下载文件里面会有一个.gdf文件夹,用Gehpi打开就可以看到初始化画面了。
图 6
控制面板的左侧是:
节点(node):控制屏幕中的小圆点。
边:连接点的线。
布局:根据算法改变点和线的分布。
风格自由发挥,难度不大。想了解更多的同学可以去Gephi官网,里面有很多具体的教程。
图 7
正如我这次所说,Node中的Attribute设置为Comment_count,Layout选择Fruchterman Reingold算法。对于这些布局算法(force-directed layout algorithm)的细节,其基本思想是移动节点并改变它们之间的力以尽量减少系统能量。您可以在 wiki 上搜索其他算法。然后黑色网格变得富有结构和色彩。
图 8
右侧是统计相关数据。我不明白很多意思。我还在学习,这里就不介绍了。
哈利波特与魔法石的画面是怎么来的?
首先要做的是从网上找到哈利波特与魔法石的文字并下载。
爬虫的这一部分是由@drizzt 为我完成的,再次感谢!
拿到小说后。
这需要用 Python 对整本书进行文本分析。
在分析之前,我们首先需要创建一个人名列表。
百度搜索哈利波特的字符表制作成txt如下:
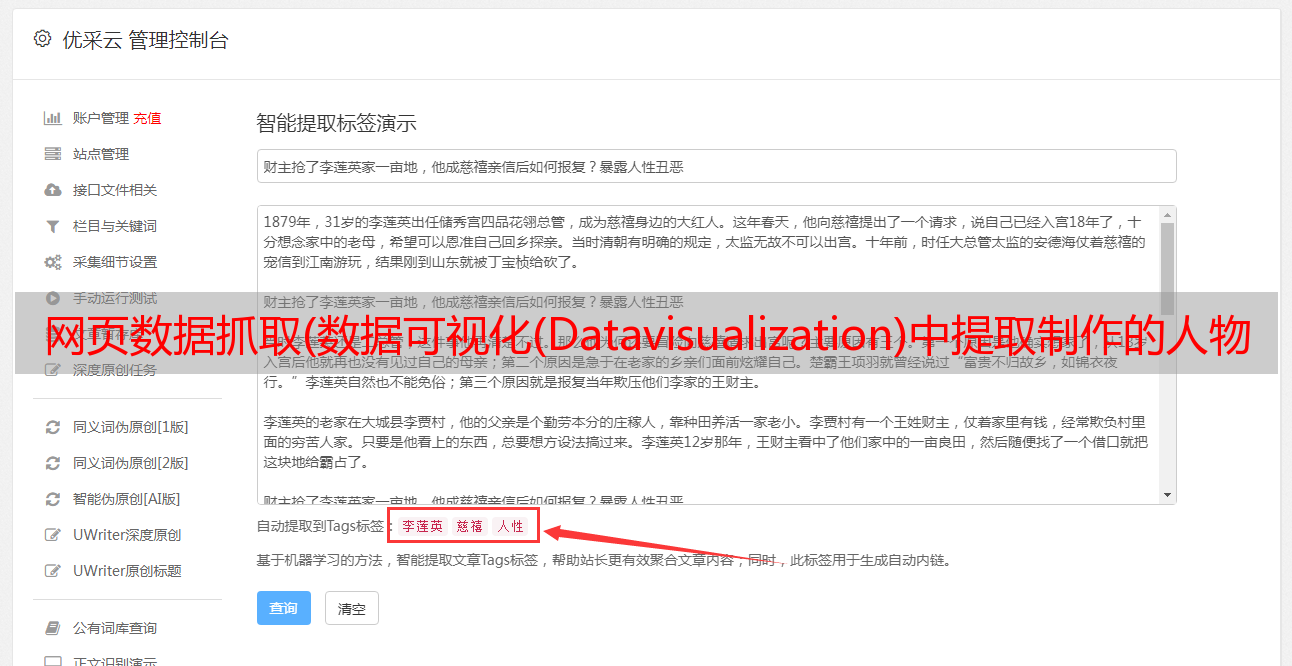
这里选择使用jieba进行分词
然后定义3个关系
然后根据字典类型名称保存字符,字典的key是字符名,value是字符在全文中出现的次数。字典类型关系保存了字符之间关系的有向边。字典的key是有向边的起点,value是一条字典边,边的key是有向边的终点,value是有向边的权重,代表两个的接近度人物之间的联系。lineNames 是一个缓存变量,用于存储每个段的当前段落中出现的字符名称。lineNames[i] 是一个存储出现在第 i 段中的字符的列表。
获取node.txt和edge.txt,然后导入Gephi。选择导入电子表格,导入node.txt(在选项中选择节点图)和edge.txt(
选项,选择边表图)。
美化和算法调整布局后,大家可以自由发挥了。
最后,让我们介绍一些社交网络分析的概念。
第一:网络密度
网络的密度是给定网络中关系(边)的数量与网络中节点之间可能的关系总数的比率
这是确定如何连接良好网络的常用措施
全连接网络的密度为 1
下面的网络示例显示了 0.83 的密度
公式:可观察到的实际连接数/总潜在连接数 = 关系密度
如图,可以看出关系数为(5),可能的关系数(6),所以关系密度为5/6)
密度是一种有用的衡量网络相互比较的方法
密度测量与跟踪现象有关,例如信息的传播(例如,思想、谣言、疾病等的传播)。
这是因为它假设在紧密连接的网络中,信息传播得更快并到达更广泛的节点集
网络越密集,就越有可能被认为是一个有凝聚力的社区(即社会支持和有效沟通的来源)
第二:层(度)
指特定参与者与网络的其他成员所拥有的关系的数量和类型
要点:单向关系(directed relationship)和对称关系(symmetric relationship)
学位
特定节点与其他节点之间的关系
出度
表示节点 1 和 2 之间的往复运动
基本上是联系强度的一种度量,与分析整个网络同样相关(权重度)
衡量权重可以是:互动频率、交换项目数量、个人对关系强度的感知
3.结构孔
结构孔的想法描述了网络密度的对立面,即缺乏连接。
结构洞归因于节点,否则网络的密集连接部分被划分为重要的连接节点。这些连接网络部分的节点称为“经纪人”。
和大的一样。
弱关系的概念与结构空洞的概念密切相关
与结构洞相似,弱关系在网络中的嵌入较少。
尽管如此,它们仍执行重要的功能:
它们促进集群之间的信息流(即来自网络的遥远部分)
弱联系有助于整合原本支离破碎且不连贯的社会系统
4. 聚类
计算和识别网络中的集群,尤其是大型网络可能很麻烦
预定义算法有助于识别网络中的集群和社区
Force Atlas 和 Force Altas 2:大型网络社区中最常用的确定算法之一(例如在 Gephi 中)
所用算法的优点:不需要现有的知识图论来可视化和分析集群网络
缺点:它们的准确性高度依赖于我们正在分析的网络类型。
参考:
对于算法内容,可以从这个文章Force Atlas开始:ForceAtlas2,一个为Gephi软件设计的便捷网络可视化的连续图布局算法
Python基于同现提取《釜山行》人物关系教程完成:Python基于同现提取《釜山行》人物关系 - 侯景仪的博客 - 博客频道 - CSDN.NET

