文章采集调用(无界数据来源于正则表达式Filter帮您解决数据的问题!)
优采云 发布时间: 2022-02-07 06:19文章采集调用(无界数据来源于正则表达式Filter帮您解决数据的问题!)
介绍
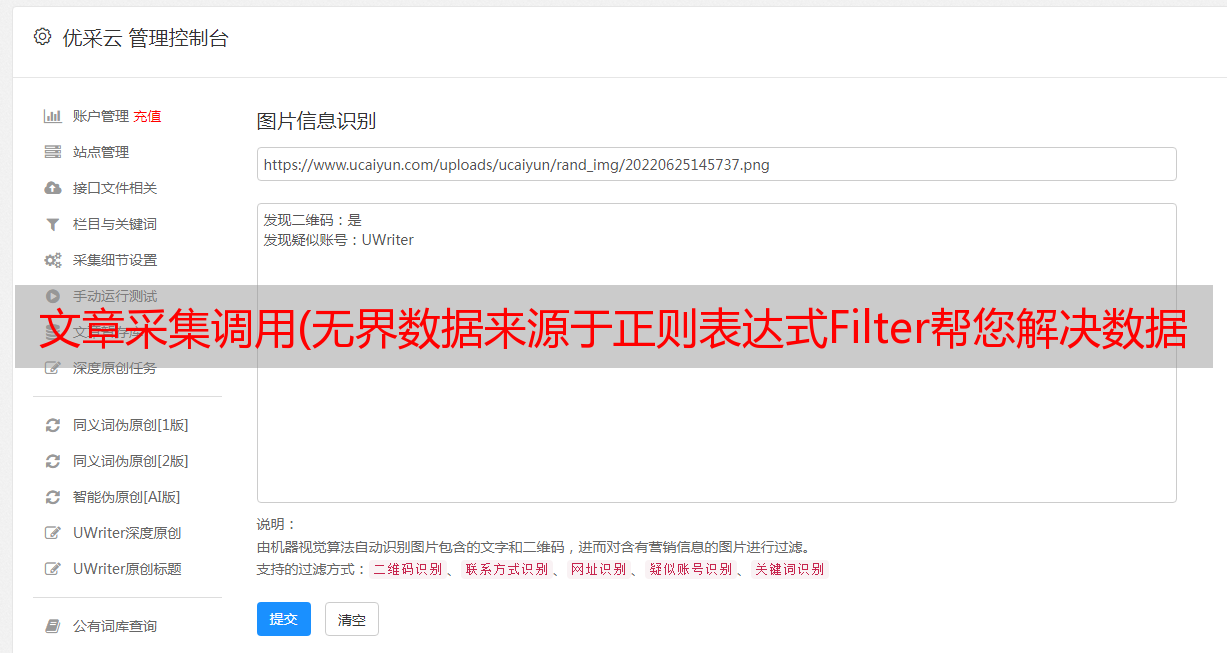
AnyMetrics - 面向开发人员的、声明性的 Metrics 采集 和监控系统,可以对结构化和非结构化、有界和无界数据执行 采集,通过提取、过滤、逻辑运算等,将结果存储起来在流行的监控系统或存储引擎(如Prometheus、ES)中构建完整的监控系统,用grafana完成数据可视化
数据采集、提取、过滤、存储等都是由配置驱动,无需额外开发。对应AnyMetrics,分别配置数据源、采集规则、采集器。基于这些配置,AnyMetrics 将使用 pipeline 的方式自动完成从 data采集 到数据存储的所有工作
对于有界数据的任务,AnyMetrics 将以固定频率从数据源中提取数据。AnyMetrics 具有内置的 MySQL 数据源。对于具有无限数据的任务,AnyMetrics 会在一个时间窗口内从数据源中拉取数据。批量拉取数据,AnyMetrics 内置 Kafka 类型无界数据源
AnyMetrics的数据源可以是任何系统,例如可以将HTTP请求结果作为数据源,也可以将ES检索结果作为数据源
将非结构化数据转换为结构化数据的目的,可以通过对数据源的原创数据进行提取和过滤来实现。AnyMetrics 中有两个内置的采集规则(Filter),正则表达式和 Spring EL 表达式。完成数据的提取和过滤,使用Spring EL表达式对原创数据和正则表达式提取后的数据完成逻辑运算。过滤器可单独使用或组合使用。FilterChain的方式是顺序执行的
数据提取和过滤后,下一步就是将数据以指定的方式存储在目标系统中。Prometheus 采集器内置于 AnyMetrics 中。通过定义 Metrics,可以将数据推送到 Prometheus 的 PushGateway。
AnyMetrics 的采集器可以将数据推送到任何系统,例如 MySQL、ES 甚至是 WebHook
无论是采集规则配置还是采集器配置,都可以通过可变配置来完成动态配置的替换。变量数据来自正则表达式Filter,通过定义如(.*)可以得到一个名为
的变量,有Spring EL的地方可以使用#来使用变量,其他地方可以使用使用变量,以满足从数据提取到数据的重组或者操作操作,什么配置可以支持变量或者Spring EL表达式 根据采集规则和采集器的具体实现,Spring内置的表达式配置AnyMetrics 的 EL 过滤器和 Prometheus 采集器中的值配置支持 Spring EL 表达式和变量(#),AnyMetrics采用插件化设计方式,无论是数据源、采集规则还是采集器都可以扩展。甚至 AnyMetrics 中的内置插件也是以点对点的方式实现的。加载和使用什么插件完全由声明决定。配置
建筑学
技术栈
SpringBoot + Nacos + Vue + ElementUI
安装
启动前需要安装的依赖
安装 nacos(必填)
安装普罗米修斯(可选)
安装推送网关(可选)
启动
启动 AnyMeitris
1 mvn clean package
2 cd boot/target
3 java -Dnacos.address=nacos.ip:8848 -Dnacos.config.dataId=AnyMetricsConfig -Dnacos.config.group=config.app.AnyMetrics -Dauto=true -jar AnyMetrics-boot.jar
启动参数说明
通过 nacos.address 参数指定nacos地址
通过 nacos.config.dataId 参数指定配置在nacos的dataId,默认值为 AnyMetricsConfig
通过 nacos.config.group 参数指定配置在nacos的group,默认值为 DEFAULT
通过 auto 参数控制任务是否自启动,默认值为 false
启动后访问:8080/index.html
如何配置
1、选择任务类型
2.1、有界数据
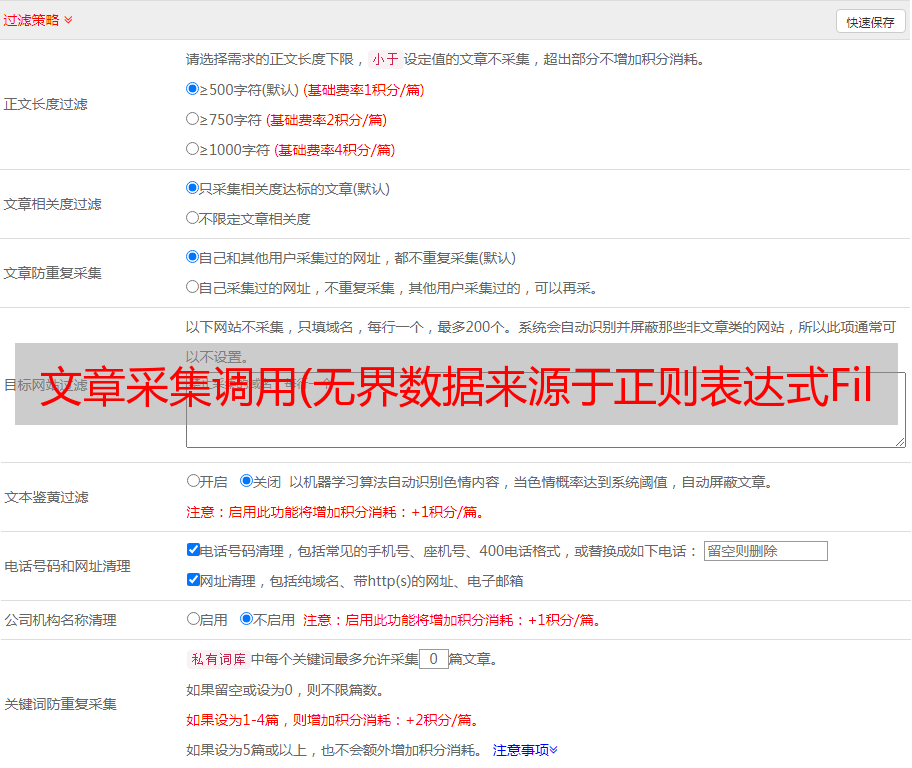
选择调度间隔,以秒为单位
2.2、选择数据源
选择数据源为mysql(目前只支持mysql),并完善相关配置
3.1、无限数据

输入时间窗口,单位:秒
3.2、选择数据源
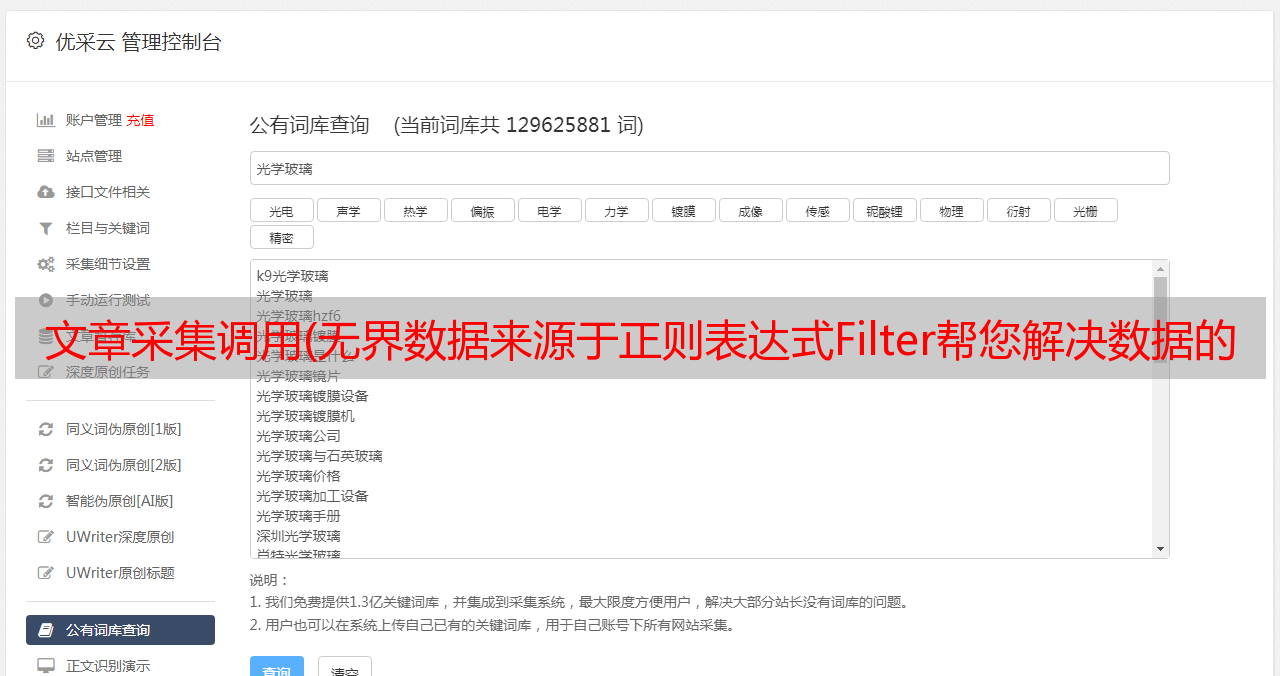
选择kafka作为数据源(目前只支持kafka),并完善相关配置
4、采集规则
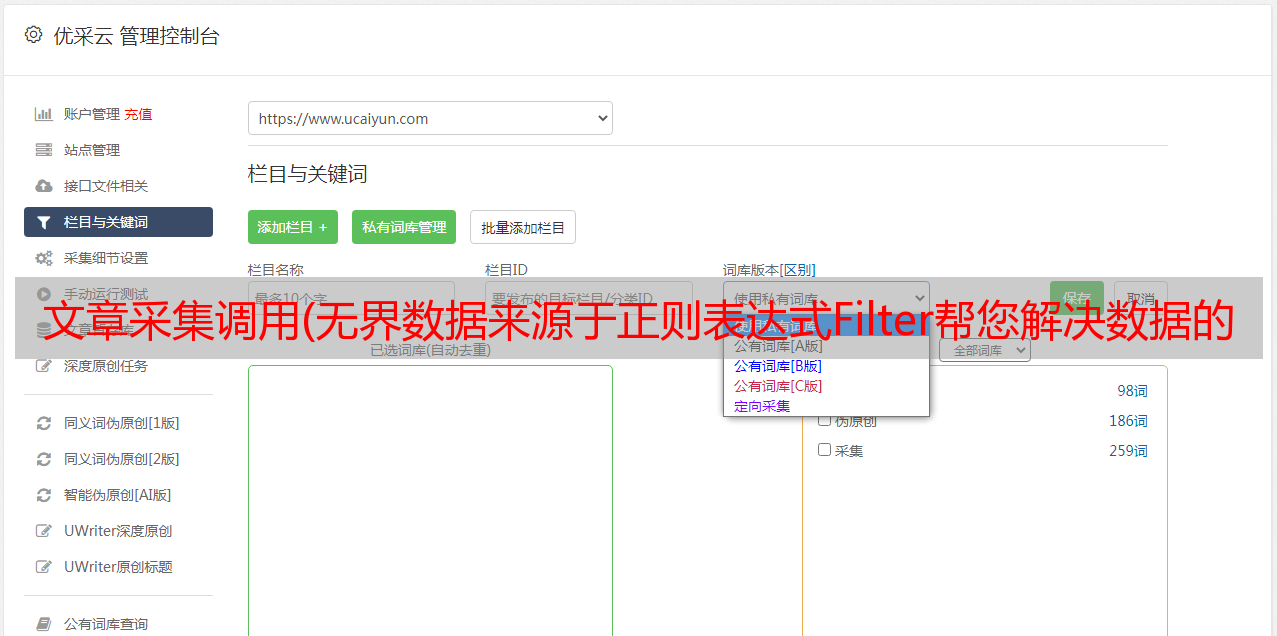
过滤器支持两种类型,regular 和 el。在正则中使用括号来提取所需的变量。多个变量以
、文章采集调用(无界数据来源于正则表达式Filter帮您解决数据的问题!)
优采云 发布时间: 2022-02-07 06:19文章采集调用(无界数据来源于正则表达式Filter帮您解决数据的问题!)
介绍
AnyMetrics - 面向开发人员的、声明性的 Metrics 采集 和监控系统,可以对结构化和非结构化、有界和无界数据执行 采集,通过提取、过滤、逻辑运算等,将结果存储起来在流行的监控系统或存储引擎(如Prometheus、ES)中构建完整的监控系统,用grafana完成数据可视化
数据采集、提取、过滤、存储等都是由配置驱动,无需额外开发。对应AnyMetrics,分别配置数据源、采集规则、采集器。基于这些配置,AnyMetrics 将使用 pipeline 的方式自动完成从 data采集 到数据存储的所有工作
对于有界数据的任务,AnyMetrics 将以固定频率从数据源中提取数据。AnyMetrics 具有内置的 MySQL 数据源。对于具有无限数据的任务,AnyMetrics 会在一个时间窗口内从数据源中拉取数据。批量拉取数据,AnyMetrics 内置 Kafka 类型无界数据源
AnyMetrics的数据源可以是任何系统,例如可以将HTTP请求结果作为数据源,也可以将ES检索结果作为数据源
将非结构化数据转换为结构化数据的目的,可以通过对数据源的原创数据进行提取和过滤来实现。AnyMetrics 中有两个内置的采集规则(Filter),正则表达式和 Spring EL 表达式。完成数据的提取和过滤,使用Spring EL表达式对原创数据和正则表达式提取后的数据完成逻辑运算。过滤器可单独使用或组合使用。FilterChain的方式是顺序执行的
数据提取和过滤后,下一步就是将数据以指定的方式存储在目标系统中。Prometheus 采集器内置于 AnyMetrics 中。通过定义 Metrics,可以将数据推送到 Prometheus 的 PushGateway。
AnyMetrics 的采集器可以将数据推送到任何系统,例如 MySQL、ES 甚至是 WebHook
无论是采集规则配置还是采集器配置,都可以通过可变配置来完成动态配置的替换。变量数据来自正则表达式Filter,通过定义如(.*)可以得到一个名为$1的变量,有Spring EL的地方可以使用#$1来使用变量,其他地方可以使用$1使用变量,以满足从数据提取到数据的重组或者操作操作,什么配置可以支持变量或者Spring EL表达式 根据采集规则和采集器的具体实现,Spring内置的表达式配置AnyMetrics 的 EL 过滤器和 Prometheus 采集器中的值配置支持 Spring EL 表达式和变量(#$1),
AnyMetrics采用插件化设计方式,无论是数据源、采集规则还是采集器都可以扩展。甚至 AnyMetrics 中的内置插件也是以点对点的方式实现的。加载和使用什么插件完全由声明决定。配置
建筑学
技术栈
SpringBoot + Nacos + Vue + ElementUI
安装
启动前需要安装的依赖
安装 nacos(必填)
安装普罗米修斯(可选)
安装推送网关(可选)
启动
启动 AnyMeitris
1 mvn clean package
2 cd boot/target
3 java -Dnacos.address=nacos.ip:8848 -Dnacos.config.dataId=AnyMetricsConfig -Dnacos.config.group=config.app.AnyMetrics -Dauto=true -jar AnyMetrics-boot.jar
启动参数说明
通过 nacos.address 参数指定nacos地址
通过 nacos.config.dataId 参数指定配置在nacos的dataId,默认值为 AnyMetricsConfig
通过 nacos.config.group 参数指定配置在nacos的group,默认值为 DEFAULT
通过 auto 参数控制任务是否自启动,默认值为 false
启动后访问:8080/index.html
如何配置
1、选择任务类型
2.1、有界数据
选择调度间隔,以秒为单位
2.2、选择数据源
选择数据源为mysql(目前只支持mysql),并完善相关配置
3.1、无限数据
输入时间窗口,单位:秒
3.2、选择数据源
选择kafka作为数据源(目前只支持kafka),并完善相关配置
4、采集规则
过滤器支持两种类型,regular 和 el。在正则中使用括号来提取所需的变量。多个变量以 $1、$2 ... $N 的形式命名。在el中,可以使用_#$1 _变量来执行操作
5、采集器
选择prometheus(目前只支持prometheus)并完善metrics相关配置信息,type支持gauge、counter、histogram类型,labels支持$1变量,value支持Spring EL表达式变量操作
运行任务
1、开始任务
点击开始按钮开始任务
2、查看运行日志
点击日志选项卡,查询任务运行日志
3、iframe
点击iframe Tab,将外部系统嵌入到任务中,比如将grafana的dashboard链接嵌入到系统中进行展示
4、停止任务
单击停止按钮以停止任务
例子
示例一:APM 监控 - 采集 所有执行时间超过 3 秒的慢速链接并配置警报策略
1、设置kafka为数据源
从 kafka 读取跟踪日志
{
"groupId":"anymetrics_apm_slow_trace",
"kafkaAddress":"192.168.0.1:9092",
"topic":"p_bigtracer_metric_log",
"type":"kafka"
}
2、设置采集规则
通话记录是结构化数据,例如:
1617953102329,operation-admin-web,10.8.60.41,RESOURCE_MYSQL_LOG,com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList,1,1,0,0,1
因此,第一步是使用正则规则对数据进行提取和过滤,对应的正则规则为:
(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?)
提取的数据为:
{
"$4":"RESOURCE_MYSQL_LOG",
"$5":"com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList",
"$6":"1",
"$7":"1",
"$10":"1",
"$8":"0",
"$9":"0",
"$1":"1617953102329",
"$2":"operation-admin-web",
"$3":"10.8.60.41"
}
我们有 10 个变量,从 1 美元到 10 美元。由于我们监控的是超过3秒的慢速链接,我们只需要采集RT超过3秒的日志数据,所以我们需要定义一个逻辑运算表达式Filter,对应的EL表达式公式为:
(new java.lang.Double(#$10) / #$6) > 3000
其中#$10是链接的总响应时间,#$6是接口的总调用次数,先通过#$10/#$6运算得到平均RT,再通过(#$10/#$过滤掉3 6) > 3000 几秒内的慢速链接数据
根据以上两条采集规则,完整配置为:
{
"timeWindow": 40,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\n",
"type": "regular"
},
{
"expression": "(new java.lang.Double(#$10) / #$6) > 3000",
"type": "el"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_apm_slow_trace",
"labelNames": [
"application",
"type",
"endpoint"
],
"name": "anymetrics_apm_slow_trace",
"type": "gauge",
"value": "new java.lang.Double(#$10) / #$6",
"labels": [
"$2",
"$4",
"$5"
]
}
],
"type": "prometheus",
"job": "anymetrics_apm_slow_trace"
}
promethus的metrics需要定义,名字是anymetrics_apm_slow_trace,类型是gauge,lableNames使用application,type,endpoint,对应变量$2、$4、$5,因为响应时间采集RT,所以值为#$10 / #$6
其中#$10是链接的总响应时间,#$6是接口的总调用次数,通过#$10/#$6的运算得到平均RT
4、配置警报和可视化
4.1 可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_apm_slow_trace{}
关于 PromQL 可以参考
4.2 配置 Grafana 警报
在面板中选择警报选项卡以定义警报规则,例如:
每 1m 评估 1m
条件
NoData 和错误处理
通知
一个比较完整的APM监控组合如下:
通过调用链log采集不同维度的metrics,完成对链路RT、项目错误数、项目平均RT、链路RT分布等的多维度监控。
示例2:可视化注册用户总数
1、设置mysql为数据源
根据sql查询总用户数
{
"password": "root",
"jdbcurl": "jdbc:mysql://192.168.0.1:3306/user",
"type": "mysql",
"sql": "select count(1) from user",
"username": "root"
}
2、设置采集规则
根据sql查询的结果,提取count(1),用正则表达式采集规则:
{
"kind": "schedule",
"interval": 5,
"filters": [
{
"expression": "\\{\\\"count\\(1\\)\\\":(.*)\\}",
"type": "regular"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_member_count",
"name": "anymetrics_member_count",
"type": "gauge",
"value": "#$1"
}
],
"type": "prometheus",
"job": "anymetrics_member_count"
}
promethus的metrics需要定义,名字是anymetrics_member_count,类型是gauge,因为只需要采集用户总数,所以不需要定义labels和labelNames,值为#$1
4、配置可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_member_count{}
示例 3:Nginx 日志监控
Nginx请求延迟监控,Nginx状态码监控
1、设置kafka为数据源
使用 nginx access_log 日志
{
"groupId":"anymetrics_nginx",
"kafkaAddress":"192.168.0.1:9092",
"topic":"nginx_access_log",
"type":"kafka"
}
2、设置采集规则
假设nginx的log_format配置如下:
log_format main '"$http_x_forwarded_for" $remote_addr - $remote_user [$time_local] $http_host "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" $upstream_addr $request_method $upstream_status $upstream_response_time';
因此,在第一步中,使用正则Filter对数据进行提取和过滤,对应的正则为:
(.*?)\\s+(.*?)\\s+-(.*?)\\s+\\[(.*?)\\]\\s+(.*?)\\s+\\\"(.*?)\\s+(.*?)\\s+(.*?)\\s+\\\"?(\\d+)\\s+(\\d+)\\s\\\"(.*?)\\\"\\s+\\\"(.*?)\\\"\\s+(.*?)\\s+(.*?)\\s+(\\d+)\\s+(.*)",
提取的数据为:
$1:"-"
$2:192.168.198.17
$3: -
$4:13/Apr/2021:10:48:14 +0800
$5:dev.api.com
$6:POST
$7:/yxy-api-gateway/api/json/yuandouActivity/access
$8:HTTP/1.1"
$9:200
$10:87
$11:http://192.168.0.1:8100/yxy-edu-web/coursetrialTemp?id=123
$12:Mozilla/5.0 (iPhone; CPU iPhone OS 13_4_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko)Mobile/15E148 MicroMessenger/7.0.11(0x17000b21)NetType/WIFI Language/zh_CN
$13:10.8.43.18:8080
$14:POST
$15:200
$16:0.005
一共得到了16个变量,通过对比log_format就可以知道每个变量的含义
完整的采集规则配置为:
{
"timeWindow": 30,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\\s+(.*?)\\s+-(.*?)\\s+\\[(.*?)\\]\\s+(.*?)\\s+\\\"(.*?)\\s+(.*?)\\s+(.*?)\\s+\\\"?(\\d+)\\s+(\\d+)\\s\\\"(.*?)\\\"\\s+\\\"(.*?)\\\"\\s+(.*?)\\s+(.*?)\\s+(\\d+)\\s+(.*)",
"type": "regular"
}
]
}
3、设置采集器
采集每个请求的响应时间和请求的状态码,并将数据存储在promethus中
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "nginx_log_host_status",
"labelNames": [
"host",
"status"
],
"name": "nginx_log_host_status",
"type": "gauge",
"value": "1",
"labels": [
"$5",
"$9"
]
},
{
"help": "nginx_log_req_rt (seconds)",
"labelNames": [
"host",
"endpoint"
],
"name": "nginx_log_req_rt",
"type": "gauge",
"value": "new java.lang.Double(#$16)",
"labels": [
"$5",
"$7"
]
}
],
"type": "prometheus",
"job": "anymetrics_nginx_log"
}
4、配置可视化
Nginx状态码监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_host_status{}
Nginx 请求延迟监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_req_rt{}
问答
如何采集 APM 日志?
如果系统中有调用链跟踪系统,可以使用调用链日志,或者通过定义*敏*感*词*来记录目标方法。定义好日志格式后,可以直接逐行打印,也可以在内存中聚合后以固定频率打印,日志一般收录RT延迟、错误/成功次数、端点、应用等关键数据。
日志是如何采集到kafka的?
可以使用filebeat采集nginx的access_log和tomcat的应用日志到kafka
目前支持哪些数据源?
有界数据目前支持mysql、http;无界数据目前支持kafka
目前支持哪些采集器?
目前只支持prometheus,使用pushgateway推送数据到prometheus
如果我已经使用了 Skywalking 和 Zipkin 等呼叫链跟踪系统,是否需要使用 AnyMetrics?
两者之间没有冲突。调用链跟踪系统采集链路的调用关系和APM指标数据。AnyMetrics不仅可以将结构化调用链跟踪系统的指标日志作为数据源来监控系统,还可以将结构化日志作为数据源来监控系统运行,比如监控一些Exception事件,还可以可视化或监控数据库表数据。同时,AnyMetrics 支持跨平台系统,任何系统生成的日志都可以作为数据源。监控系统运行
最后附上github项目地址:
0 个评论
官方客服QQ群


在
线
客
服
5、采集器
选择prometheus(目前只支持prometheus)并完善metrics相关配置信息,type支持gauge、counter、histogram类型,labels支持
变量,value支持Spring EL表达式变量操作运行任务
1、开始任务
点击开始按钮开始任务
2、查看运行日志
点击日志选项卡,查询任务运行日志
3、iframe
点击iframe Tab,将外部系统嵌入到任务中,比如将grafana的dashboard链接嵌入到系统中进行展示
4、停止任务
单击停止按钮以停止任务
例子
示例一:APM 监控 - 采集 所有执行时间超过 3 秒的慢速链接并配置警报策略
1、设置kafka为数据源
从 kafka 读取跟踪日志
{
"groupId":"anymetrics_apm_slow_trace",
"kafkaAddress":"192.168.0.1:9092",
"topic":"p_bigtracer_metric_log",
"type":"kafka"
}
2、设置采集规则
通话记录是结构化数据,例如:
1617953102329,operation-admin-web,10.8.60.41,RESOURCE_MYSQL_LOG,com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList,1,1,0,0,1
因此,第一步是使用正则规则对数据进行提取和过滤,对应的正则规则为:
(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?)
提取的数据为:
{
"":"RESOURCE_MYSQL_LOG",
"":"com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList",
"":"1",
"":"1",
"":"1",
"":"0",
"":"0",
"
":"1617953102329","
文章采集调用(无界数据来源于正则表达式Filter帮您解决数据的问题!)
优采云 发布时间: 2022-02-07 06:19文章采集调用(无界数据来源于正则表达式Filter帮您解决数据的问题!)
介绍
AnyMetrics - 面向开发人员的、声明性的 Metrics 采集 和监控系统,可以对结构化和非结构化、有界和无界数据执行 采集,通过提取、过滤、逻辑运算等,将结果存储起来在流行的监控系统或存储引擎(如Prometheus、ES)中构建完整的监控系统,用grafana完成数据可视化
数据采集、提取、过滤、存储等都是由配置驱动,无需额外开发。对应AnyMetrics,分别配置数据源、采集规则、采集器。基于这些配置,AnyMetrics 将使用 pipeline 的方式自动完成从 data采集 到数据存储的所有工作
对于有界数据的任务,AnyMetrics 将以固定频率从数据源中提取数据。AnyMetrics 具有内置的 MySQL 数据源。对于具有无限数据的任务,AnyMetrics 会在一个时间窗口内从数据源中拉取数据。批量拉取数据,AnyMetrics 内置 Kafka 类型无界数据源
AnyMetrics的数据源可以是任何系统,例如可以将HTTP请求结果作为数据源,也可以将ES检索结果作为数据源
将非结构化数据转换为结构化数据的目的,可以通过对数据源的原创数据进行提取和过滤来实现。AnyMetrics 中有两个内置的采集规则(Filter),正则表达式和 Spring EL 表达式。完成数据的提取和过滤,使用Spring EL表达式对原创数据和正则表达式提取后的数据完成逻辑运算。过滤器可单独使用或组合使用。FilterChain的方式是顺序执行的
数据提取和过滤后,下一步就是将数据以指定的方式存储在目标系统中。Prometheus 采集器内置于 AnyMetrics 中。通过定义 Metrics,可以将数据推送到 Prometheus 的 PushGateway。
AnyMetrics 的采集器可以将数据推送到任何系统,例如 MySQL、ES 甚至是 WebHook
无论是采集规则配置还是采集器配置,都可以通过可变配置来完成动态配置的替换。变量数据来自正则表达式Filter,通过定义如(.*)可以得到一个名为$1的变量,有Spring EL的地方可以使用#$1来使用变量,其他地方可以使用$1使用变量,以满足从数据提取到数据的重组或者操作操作,什么配置可以支持变量或者Spring EL表达式 根据采集规则和采集器的具体实现,Spring内置的表达式配置AnyMetrics 的 EL 过滤器和 Prometheus 采集器中的值配置支持 Spring EL 表达式和变量(#$1),
AnyMetrics采用插件化设计方式,无论是数据源、采集规则还是采集器都可以扩展。甚至 AnyMetrics 中的内置插件也是以点对点的方式实现的。加载和使用什么插件完全由声明决定。配置
建筑学
技术栈
SpringBoot + Nacos + Vue + ElementUI
安装
启动前需要安装的依赖
安装 nacos(必填)
安装普罗米修斯(可选)
安装推送网关(可选)
启动
启动 AnyMeitris
1 mvn clean package
2 cd boot/target
3 java -Dnacos.address=nacos.ip:8848 -Dnacos.config.dataId=AnyMetricsConfig -Dnacos.config.group=config.app.AnyMetrics -Dauto=true -jar AnyMetrics-boot.jar
启动参数说明
通过 nacos.address 参数指定nacos地址
通过 nacos.config.dataId 参数指定配置在nacos的dataId,默认值为 AnyMetricsConfig
通过 nacos.config.group 参数指定配置在nacos的group,默认值为 DEFAULT
通过 auto 参数控制任务是否自启动,默认值为 false
启动后访问:8080/index.html
如何配置
1、选择任务类型
2.1、有界数据
选择调度间隔,以秒为单位
2.2、选择数据源
选择数据源为mysql(目前只支持mysql),并完善相关配置
3.1、无限数据
输入时间窗口,单位:秒
3.2、选择数据源
选择kafka作为数据源(目前只支持kafka),并完善相关配置
4、采集规则
过滤器支持两种类型,regular 和 el。在正则中使用括号来提取所需的变量。多个变量以 $1、$2 ... $N 的形式命名。在el中,可以使用_#$1 _变量来执行操作
5、采集器
选择prometheus(目前只支持prometheus)并完善metrics相关配置信息,type支持gauge、counter、histogram类型,labels支持$1变量,value支持Spring EL表达式变量操作
运行任务
1、开始任务
点击开始按钮开始任务
2、查看运行日志
点击日志选项卡,查询任务运行日志
3、iframe
点击iframe Tab,将外部系统嵌入到任务中,比如将grafana的dashboard链接嵌入到系统中进行展示
4、停止任务
单击停止按钮以停止任务
例子
示例一:APM 监控 - 采集 所有执行时间超过 3 秒的慢速链接并配置警报策略
1、设置kafka为数据源
从 kafka 读取跟踪日志
{
"groupId":"anymetrics_apm_slow_trace",
"kafkaAddress":"192.168.0.1:9092",
"topic":"p_bigtracer_metric_log",
"type":"kafka"
}
2、设置采集规则
通话记录是结构化数据,例如:
1617953102329,operation-admin-web,10.8.60.41,RESOURCE_MYSQL_LOG,com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList,1,1,0,0,1
因此,第一步是使用正则规则对数据进行提取和过滤,对应的正则规则为:
(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?)
提取的数据为:
{
"$4":"RESOURCE_MYSQL_LOG",
"$5":"com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList",
"$6":"1",
"$7":"1",
"$10":"1",
"$8":"0",
"$9":"0",
"$1":"1617953102329",
"$2":"operation-admin-web",
"$3":"10.8.60.41"
}
我们有 10 个变量,从 1 美元到 10 美元。由于我们监控的是超过3秒的慢速链接,我们只需要采集RT超过3秒的日志数据,所以我们需要定义一个逻辑运算表达式Filter,对应的EL表达式公式为:
(new java.lang.Double(#$10) / #$6) > 3000
其中#$10是链接的总响应时间,#$6是接口的总调用次数,先通过#$10/#$6运算得到平均RT,再通过(#$10/#$过滤掉3 6) > 3000 几秒内的慢速链接数据
根据以上两条采集规则,完整配置为:
{
"timeWindow": 40,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\n",
"type": "regular"
},
{
"expression": "(new java.lang.Double(#$10) / #$6) > 3000",
"type": "el"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_apm_slow_trace",
"labelNames": [
"application",
"type",
"endpoint"
],
"name": "anymetrics_apm_slow_trace",
"type": "gauge",
"value": "new java.lang.Double(#$10) / #$6",
"labels": [
"$2",
"$4",
"$5"
]
}
],
"type": "prometheus",
"job": "anymetrics_apm_slow_trace"
}
promethus的metrics需要定义,名字是anymetrics_apm_slow_trace,类型是gauge,lableNames使用application,type,endpoint,对应变量$2、$4、$5,因为响应时间采集RT,所以值为#$10 / #$6
其中#$10是链接的总响应时间,#$6是接口的总调用次数,通过#$10/#$6的运算得到平均RT
4、配置警报和可视化
4.1 可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_apm_slow_trace{}
关于 PromQL 可以参考
4.2 配置 Grafana 警报
在面板中选择警报选项卡以定义警报规则,例如:
每 1m 评估 1m
条件
NoData 和错误处理
通知
一个比较完整的APM监控组合如下:
通过调用链log采集不同维度的metrics,完成对链路RT、项目错误数、项目平均RT、链路RT分布等的多维度监控。
示例2:可视化注册用户总数
1、设置mysql为数据源
根据sql查询总用户数
{
"password": "root",
"jdbcurl": "jdbc:mysql://192.168.0.1:3306/user",
"type": "mysql",
"sql": "select count(1) from user",
"username": "root"
}
2、设置采集规则
根据sql查询的结果,提取count(1),用正则表达式采集规则:
{
"kind": "schedule",
"interval": 5,
"filters": [
{
"expression": "\\{\\\"count\\(1\\)\\\":(.*)\\}",
"type": "regular"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_member_count",
"name": "anymetrics_member_count",
"type": "gauge",
"value": "#$1"
}
],
"type": "prometheus",
"job": "anymetrics_member_count"
}
promethus的metrics需要定义,名字是anymetrics_member_count,类型是gauge,因为只需要采集用户总数,所以不需要定义labels和labelNames,值为#$1
4、配置可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_member_count{}
示例 3:Nginx 日志监控
Nginx请求延迟监控,Nginx状态码监控
1、设置kafka为数据源
使用 nginx access_log 日志
{
"groupId":"anymetrics_nginx",
"kafkaAddress":"192.168.0.1:9092",
"topic":"nginx_access_log",
"type":"kafka"
}
2、设置采集规则
假设nginx的log_format配置如下:
log_format main '"$http_x_forwarded_for" $remote_addr - $remote_user [$time_local] $http_host "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" $upstream_addr $request_method $upstream_status $upstream_response_time';
因此,在第一步中,使用正则Filter对数据进行提取和过滤,对应的正则为:
(.*?)\\s+(.*?)\\s+-(.*?)\\s+\\[(.*?)\\]\\s+(.*?)\\s+\\\"(.*?)\\s+(.*?)\\s+(.*?)\\s+\\\"?(\\d+)\\s+(\\d+)\\s\\\"(.*?)\\\"\\s+\\\"(.*?)\\\"\\s+(.*?)\\s+(.*?)\\s+(\\d+)\\s+(.*)",
提取的数据为:
$1:"-"
$2:192.168.198.17
$3: -
$4:13/Apr/2021:10:48:14 +0800
$5:dev.api.com
$6:POST
$7:/yxy-api-gateway/api/json/yuandouActivity/access
$8:HTTP/1.1"
$9:200
$10:87
$11:http://192.168.0.1:8100/yxy-edu-web/coursetrialTemp?id=123
$12:Mozilla/5.0 (iPhone; CPU iPhone OS 13_4_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko)Mobile/15E148 MicroMessenger/7.0.11(0x17000b21)NetType/WIFI Language/zh_CN
$13:10.8.43.18:8080
$14:POST
$15:200
$16:0.005
一共得到了16个变量,通过对比log_format就可以知道每个变量的含义
完整的采集规则配置为:
{
"timeWindow": 30,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\\s+(.*?)\\s+-(.*?)\\s+\\[(.*?)\\]\\s+(.*?)\\s+\\\"(.*?)\\s+(.*?)\\s+(.*?)\\s+\\\"?(\\d+)\\s+(\\d+)\\s\\\"(.*?)\\\"\\s+\\\"(.*?)\\\"\\s+(.*?)\\s+(.*?)\\s+(\\d+)\\s+(.*)",
"type": "regular"
}
]
}
3、设置采集器
采集每个请求的响应时间和请求的状态码,并将数据存储在promethus中
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "nginx_log_host_status",
"labelNames": [
"host",
"status"
],
"name": "nginx_log_host_status",
"type": "gauge",
"value": "1",
"labels": [
"$5",
"$9"
]
},
{
"help": "nginx_log_req_rt (seconds)",
"labelNames": [
"host",
"endpoint"
],
"name": "nginx_log_req_rt",
"type": "gauge",
"value": "new java.lang.Double(#$16)",
"labels": [
"$5",
"$7"
]
}
],
"type": "prometheus",
"job": "anymetrics_nginx_log"
}
4、配置可视化
Nginx状态码监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_host_status{}
Nginx 请求延迟监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_req_rt{}
问答
如何采集 APM 日志?
如果系统中有调用链跟踪系统,可以使用调用链日志,或者通过定义*敏*感*词*来记录目标方法。定义好日志格式后,可以直接逐行打印,也可以在内存中聚合后以固定频率打印,日志一般收录RT延迟、错误/成功次数、端点、应用等关键数据。
日志是如何采集到kafka的?
可以使用filebeat采集nginx的access_log和tomcat的应用日志到kafka
目前支持哪些数据源?
有界数据目前支持mysql、http;无界数据目前支持kafka
目前支持哪些采集器?
目前只支持prometheus,使用pushgateway推送数据到prometheus
如果我已经使用了 Skywalking 和 Zipkin 等呼叫链跟踪系统,是否需要使用 AnyMetrics?
两者之间没有冲突。调用链跟踪系统采集链路的调用关系和APM指标数据。AnyMetrics不仅可以将结构化调用链跟踪系统的指标日志作为数据源来监控系统,还可以将结构化日志作为数据源来监控系统运行,比如监控一些Exception事件,还可以可视化或监控数据库表数据。同时,AnyMetrics 支持跨平台系统,任何系统生成的日志都可以作为数据源。监控系统运行
最后附上github项目地址:
0 个评论
官方客服QQ群
在
线
客
服
"":"10.8.60.41"
}
我们有 10 个变量,从 1 美元到 10 美元。由于我们监控的是超过3秒的慢速链接,我们只需要采集RT超过3秒的日志数据,所以我们需要定义一个逻辑运算表达式Filter,对应的EL表达式公式为:
(new java.lang.Double(#) / #) > 3000
其中#是链接的总响应时间,#是接口的总调用次数,先通过#/#运算得到平均RT,再通过(#/#$过滤掉3 6) > 3000 几秒内的慢速链接数据
根据以上两条采集规则,完整配置为:
{
"timeWindow": 40,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\n",
"type": "regular"
},
{
"expression": "(new java.lang.Double(#) / #) > 3000",
"type": "el"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_apm_slow_trace",
"labelNames": [
"application",
"type",
"endpoint"
],
"name": "anymetrics_apm_slow_trace",
"type": "gauge",
"value": "new java.lang.Double(#) / #",
"labels": [
"
文章采集调用(无界数据来源于正则表达式Filter帮您解决数据的问题!)
优采云 发布时间: 2022-02-07 06:19文章采集调用(无界数据来源于正则表达式Filter帮您解决数据的问题!)
介绍
AnyMetrics - 面向开发人员的、声明性的 Metrics 采集 和监控系统,可以对结构化和非结构化、有界和无界数据执行 采集,通过提取、过滤、逻辑运算等,将结果存储起来在流行的监控系统或存储引擎(如Prometheus、ES)中构建完整的监控系统,用grafana完成数据可视化
数据采集、提取、过滤、存储等都是由配置驱动,无需额外开发。对应AnyMetrics,分别配置数据源、采集规则、采集器。基于这些配置,AnyMetrics 将使用 pipeline 的方式自动完成从 data采集 到数据存储的所有工作
对于有界数据的任务,AnyMetrics 将以固定频率从数据源中提取数据。AnyMetrics 具有内置的 MySQL 数据源。对于具有无限数据的任务,AnyMetrics 会在一个时间窗口内从数据源中拉取数据。批量拉取数据,AnyMetrics 内置 Kafka 类型无界数据源
AnyMetrics的数据源可以是任何系统,例如可以将HTTP请求结果作为数据源,也可以将ES检索结果作为数据源
将非结构化数据转换为结构化数据的目的,可以通过对数据源的原创数据进行提取和过滤来实现。AnyMetrics 中有两个内置的采集规则(Filter),正则表达式和 Spring EL 表达式。完成数据的提取和过滤,使用Spring EL表达式对原创数据和正则表达式提取后的数据完成逻辑运算。过滤器可单独使用或组合使用。FilterChain的方式是顺序执行的
数据提取和过滤后,下一步就是将数据以指定的方式存储在目标系统中。Prometheus 采集器内置于 AnyMetrics 中。通过定义 Metrics,可以将数据推送到 Prometheus 的 PushGateway。
AnyMetrics 的采集器可以将数据推送到任何系统,例如 MySQL、ES 甚至是 WebHook
无论是采集规则配置还是采集器配置,都可以通过可变配置来完成动态配置的替换。变量数据来自正则表达式Filter,通过定义如(.*)可以得到一个名为$1的变量,有Spring EL的地方可以使用#$1来使用变量,其他地方可以使用$1使用变量,以满足从数据提取到数据的重组或者操作操作,什么配置可以支持变量或者Spring EL表达式 根据采集规则和采集器的具体实现,Spring内置的表达式配置AnyMetrics 的 EL 过滤器和 Prometheus 采集器中的值配置支持 Spring EL 表达式和变量(#$1),
AnyMetrics采用插件化设计方式,无论是数据源、采集规则还是采集器都可以扩展。甚至 AnyMetrics 中的内置插件也是以点对点的方式实现的。加载和使用什么插件完全由声明决定。配置
建筑学
技术栈
SpringBoot + Nacos + Vue + ElementUI
安装
启动前需要安装的依赖
安装 nacos(必填)
安装普罗米修斯(可选)
安装推送网关(可选)
启动
启动 AnyMeitris
1 mvn clean package
2 cd boot/target
3 java -Dnacos.address=nacos.ip:8848 -Dnacos.config.dataId=AnyMetricsConfig -Dnacos.config.group=config.app.AnyMetrics -Dauto=true -jar AnyMetrics-boot.jar
启动参数说明
通过 nacos.address 参数指定nacos地址
通过 nacos.config.dataId 参数指定配置在nacos的dataId,默认值为 AnyMetricsConfig
通过 nacos.config.group 参数指定配置在nacos的group,默认值为 DEFAULT
通过 auto 参数控制任务是否自启动,默认值为 false
启动后访问:8080/index.html
如何配置
1、选择任务类型
2.1、有界数据
选择调度间隔,以秒为单位
2.2、选择数据源
选择数据源为mysql(目前只支持mysql),并完善相关配置
3.1、无限数据
输入时间窗口,单位:秒
3.2、选择数据源
选择kafka作为数据源(目前只支持kafka),并完善相关配置
4、采集规则
过滤器支持两种类型,regular 和 el。在正则中使用括号来提取所需的变量。多个变量以 $1、$2 ... $N 的形式命名。在el中,可以使用_#$1 _变量来执行操作
5、采集器
选择prometheus(目前只支持prometheus)并完善metrics相关配置信息,type支持gauge、counter、histogram类型,labels支持$1变量,value支持Spring EL表达式变量操作
运行任务
1、开始任务
点击开始按钮开始任务
2、查看运行日志
点击日志选项卡,查询任务运行日志
3、iframe
点击iframe Tab,将外部系统嵌入到任务中,比如将grafana的dashboard链接嵌入到系统中进行展示
4、停止任务
单击停止按钮以停止任务
例子
示例一:APM 监控 - 采集 所有执行时间超过 3 秒的慢速链接并配置警报策略
1、设置kafka为数据源
从 kafka 读取跟踪日志
{
"groupId":"anymetrics_apm_slow_trace",
"kafkaAddress":"192.168.0.1:9092",
"topic":"p_bigtracer_metric_log",
"type":"kafka"
}
2、设置采集规则
通话记录是结构化数据,例如:
1617953102329,operation-admin-web,10.8.60.41,RESOURCE_MYSQL_LOG,com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList,1,1,0,0,1
因此,第一步是使用正则规则对数据进行提取和过滤,对应的正则规则为:
(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?)
提取的数据为:
{
"$4":"RESOURCE_MYSQL_LOG",
"$5":"com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList",
"$6":"1",
"$7":"1",
"$10":"1",
"$8":"0",
"$9":"0",
"$1":"1617953102329",
"$2":"operation-admin-web",
"$3":"10.8.60.41"
}
我们有 10 个变量,从 1 美元到 10 美元。由于我们监控的是超过3秒的慢速链接,我们只需要采集RT超过3秒的日志数据,所以我们需要定义一个逻辑运算表达式Filter,对应的EL表达式公式为:
(new java.lang.Double(#$10) / #$6) > 3000
其中#$10是链接的总响应时间,#$6是接口的总调用次数,先通过#$10/#$6运算得到平均RT,再通过(#$10/#$过滤掉3 6) > 3000 几秒内的慢速链接数据
根据以上两条采集规则,完整配置为:
{
"timeWindow": 40,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\n",
"type": "regular"
},
{
"expression": "(new java.lang.Double(#$10) / #$6) > 3000",
"type": "el"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_apm_slow_trace",
"labelNames": [
"application",
"type",
"endpoint"
],
"name": "anymetrics_apm_slow_trace",
"type": "gauge",
"value": "new java.lang.Double(#$10) / #$6",
"labels": [
"$2",
"$4",
"$5"
]
}
],
"type": "prometheus",
"job": "anymetrics_apm_slow_trace"
}
promethus的metrics需要定义,名字是anymetrics_apm_slow_trace,类型是gauge,lableNames使用application,type,endpoint,对应变量$2、$4、$5,因为响应时间采集RT,所以值为#$10 / #$6
其中#$10是链接的总响应时间,#$6是接口的总调用次数,通过#$10/#$6的运算得到平均RT
4、配置警报和可视化
4.1 可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_apm_slow_trace{}
关于 PromQL 可以参考
4.2 配置 Grafana 警报
在面板中选择警报选项卡以定义警报规则,例如:
每 1m 评估 1m
条件
NoData 和错误处理
通知
一个比较完整的APM监控组合如下:
通过调用链log采集不同维度的metrics,完成对链路RT、项目错误数、项目平均RT、链路RT分布等的多维度监控。
示例2:可视化注册用户总数
1、设置mysql为数据源
根据sql查询总用户数
{
"password": "root",
"jdbcurl": "jdbc:mysql://192.168.0.1:3306/user",
"type": "mysql",
"sql": "select count(1) from user",
"username": "root"
}
2、设置采集规则
根据sql查询的结果,提取count(1),用正则表达式采集规则:
{
"kind": "schedule",
"interval": 5,
"filters": [
{
"expression": "\\{\\\"count\\(1\\)\\\":(.*)\\}",
"type": "regular"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_member_count",
"name": "anymetrics_member_count",
"type": "gauge",
"value": "#$1"
}
],
"type": "prometheus",
"job": "anymetrics_member_count"
}
promethus的metrics需要定义,名字是anymetrics_member_count,类型是gauge,因为只需要采集用户总数,所以不需要定义labels和labelNames,值为#$1
4、配置可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_member_count{}
示例 3:Nginx 日志监控
Nginx请求延迟监控,Nginx状态码监控
1、设置kafka为数据源
使用 nginx access_log 日志
{
"groupId":"anymetrics_nginx",
"kafkaAddress":"192.168.0.1:9092",
"topic":"nginx_access_log",
"type":"kafka"
}
2、设置采集规则
假设nginx的log_format配置如下:
log_format main '"$http_x_forwarded_for" $remote_addr - $remote_user [$time_local] $http_host "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" $upstream_addr $request_method $upstream_status $upstream_response_time';
因此,在第一步中,使用正则Filter对数据进行提取和过滤,对应的正则为:
(.*?)\\s+(.*?)\\s+-(.*?)\\s+\\[(.*?)\\]\\s+(.*?)\\s+\\\"(.*?)\\s+(.*?)\\s+(.*?)\\s+\\\"?(\\d+)\\s+(\\d+)\\s\\\"(.*?)\\\"\\s+\\\"(.*?)\\\"\\s+(.*?)\\s+(.*?)\\s+(\\d+)\\s+(.*)",
提取的数据为:
$1:"-"
$2:192.168.198.17
$3: -
$4:13/Apr/2021:10:48:14 +0800
$5:dev.api.com
$6:POST
$7:/yxy-api-gateway/api/json/yuandouActivity/access
$8:HTTP/1.1"
$9:200
$10:87
$11:http://192.168.0.1:8100/yxy-edu-web/coursetrialTemp?id=123
$12:Mozilla/5.0 (iPhone; CPU iPhone OS 13_4_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko)Mobile/15E148 MicroMessenger/7.0.11(0x17000b21)NetType/WIFI Language/zh_CN
$13:10.8.43.18:8080
$14:POST
$15:200
$16:0.005
一共得到了16个变量,通过对比log_format就可以知道每个变量的含义
完整的采集规则配置为:
{
"timeWindow": 30,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\\s+(.*?)\\s+-(.*?)\\s+\\[(.*?)\\]\\s+(.*?)\\s+\\\"(.*?)\\s+(.*?)\\s+(.*?)\\s+\\\"?(\\d+)\\s+(\\d+)\\s\\\"(.*?)\\\"\\s+\\\"(.*?)\\\"\\s+(.*?)\\s+(.*?)\\s+(\\d+)\\s+(.*)",
"type": "regular"
}
]
}
3、设置采集器
采集每个请求的响应时间和请求的状态码,并将数据存储在promethus中
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "nginx_log_host_status",
"labelNames": [
"host",
"status"
],
"name": "nginx_log_host_status",
"type": "gauge",
"value": "1",
"labels": [
"$5",
"$9"
]
},
{
"help": "nginx_log_req_rt (seconds)",
"labelNames": [
"host",
"endpoint"
],
"name": "nginx_log_req_rt",
"type": "gauge",
"value": "new java.lang.Double(#$16)",
"labels": [
"$5",
"$7"
]
}
],
"type": "prometheus",
"job": "anymetrics_nginx_log"
}
4、配置可视化
Nginx状态码监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_host_status{}
Nginx 请求延迟监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_req_rt{}
问答
如何采集 APM 日志?
如果系统中有调用链跟踪系统,可以使用调用链日志,或者通过定义*敏*感*词*来记录目标方法。定义好日志格式后,可以直接逐行打印,也可以在内存中聚合后以固定频率打印,日志一般收录RT延迟、错误/成功次数、端点、应用等关键数据。
日志是如何采集到kafka的?
可以使用filebeat采集nginx的access_log和tomcat的应用日志到kafka
目前支持哪些数据源?
有界数据目前支持mysql、http;无界数据目前支持kafka
目前支持哪些采集器?
目前只支持prometheus,使用pushgateway推送数据到prometheus
如果我已经使用了 Skywalking 和 Zipkin 等呼叫链跟踪系统,是否需要使用 AnyMetrics?
两者之间没有冲突。调用链跟踪系统采集链路的调用关系和APM指标数据。AnyMetrics不仅可以将结构化调用链跟踪系统的指标日志作为数据源来监控系统,还可以将结构化日志作为数据源来监控系统运行,比如监控一些Exception事件,还可以可视化或监控数据库表数据。同时,AnyMetrics 支持跨平台系统,任何系统生成的日志都可以作为数据源。监控系统运行
最后附上github项目地址:
0 个评论
官方客服QQ群
在
线
客
服
"",
""
]
}
],
"type": "prometheus",
"job": "anymetrics_apm_slow_trace"
}
promethus的metrics需要定义,名字是anymetrics_apm_slow_trace,类型是gauge,lableNames使用application,type,endpoint,对应变量
文章采集调用(无界数据来源于正则表达式Filter帮您解决数据的问题!)
优采云 发布时间: 2022-02-07 06:19文章采集调用(无界数据来源于正则表达式Filter帮您解决数据的问题!)
介绍
AnyMetrics - 面向开发人员的、声明性的 Metrics 采集 和监控系统,可以对结构化和非结构化、有界和无界数据执行 采集,通过提取、过滤、逻辑运算等,将结果存储起来在流行的监控系统或存储引擎(如Prometheus、ES)中构建完整的监控系统,用grafana完成数据可视化
数据采集、提取、过滤、存储等都是由配置驱动,无需额外开发。对应AnyMetrics,分别配置数据源、采集规则、采集器。基于这些配置,AnyMetrics 将使用 pipeline 的方式自动完成从 data采集 到数据存储的所有工作
对于有界数据的任务,AnyMetrics 将以固定频率从数据源中提取数据。AnyMetrics 具有内置的 MySQL 数据源。对于具有无限数据的任务,AnyMetrics 会在一个时间窗口内从数据源中拉取数据。批量拉取数据,AnyMetrics 内置 Kafka 类型无界数据源
AnyMetrics的数据源可以是任何系统,例如可以将HTTP请求结果作为数据源,也可以将ES检索结果作为数据源
将非结构化数据转换为结构化数据的目的,可以通过对数据源的原创数据进行提取和过滤来实现。AnyMetrics 中有两个内置的采集规则(Filter),正则表达式和 Spring EL 表达式。完成数据的提取和过滤,使用Spring EL表达式对原创数据和正则表达式提取后的数据完成逻辑运算。过滤器可单独使用或组合使用。FilterChain的方式是顺序执行的
数据提取和过滤后,下一步就是将数据以指定的方式存储在目标系统中。Prometheus 采集器内置于 AnyMetrics 中。通过定义 Metrics,可以将数据推送到 Prometheus 的 PushGateway。
AnyMetrics 的采集器可以将数据推送到任何系统,例如 MySQL、ES 甚至是 WebHook
无论是采集规则配置还是采集器配置,都可以通过可变配置来完成动态配置的替换。变量数据来自正则表达式Filter,通过定义如(.*)可以得到一个名为$1的变量,有Spring EL的地方可以使用#$1来使用变量,其他地方可以使用$1使用变量,以满足从数据提取到数据的重组或者操作操作,什么配置可以支持变量或者Spring EL表达式 根据采集规则和采集器的具体实现,Spring内置的表达式配置AnyMetrics 的 EL 过滤器和 Prometheus 采集器中的值配置支持 Spring EL 表达式和变量(#$1),
AnyMetrics采用插件化设计方式,无论是数据源、采集规则还是采集器都可以扩展。甚至 AnyMetrics 中的内置插件也是以点对点的方式实现的。加载和使用什么插件完全由声明决定。配置
建筑学
技术栈
SpringBoot + Nacos + Vue + ElementUI
安装
启动前需要安装的依赖
安装 nacos(必填)
安装普罗米修斯(可选)
安装推送网关(可选)
启动
启动 AnyMeitris
1 mvn clean package
2 cd boot/target
3 java -Dnacos.address=nacos.ip:8848 -Dnacos.config.dataId=AnyMetricsConfig -Dnacos.config.group=config.app.AnyMetrics -Dauto=true -jar AnyMetrics-boot.jar
启动参数说明
通过 nacos.address 参数指定nacos地址
通过 nacos.config.dataId 参数指定配置在nacos的dataId,默认值为 AnyMetricsConfig
通过 nacos.config.group 参数指定配置在nacos的group,默认值为 DEFAULT
通过 auto 参数控制任务是否自启动,默认值为 false
启动后访问:8080/index.html
如何配置
1、选择任务类型
2.1、有界数据
选择调度间隔,以秒为单位
2.2、选择数据源
选择数据源为mysql(目前只支持mysql),并完善相关配置
3.1、无限数据
输入时间窗口,单位:秒
3.2、选择数据源
选择kafka作为数据源(目前只支持kafka),并完善相关配置
4、采集规则
过滤器支持两种类型,regular 和 el。在正则中使用括号来提取所需的变量。多个变量以 $1、$2 ... $N 的形式命名。在el中,可以使用_#$1 _变量来执行操作
5、采集器
选择prometheus(目前只支持prometheus)并完善metrics相关配置信息,type支持gauge、counter、histogram类型,labels支持$1变量,value支持Spring EL表达式变量操作
运行任务
1、开始任务
点击开始按钮开始任务
2、查看运行日志
点击日志选项卡,查询任务运行日志
3、iframe
点击iframe Tab,将外部系统嵌入到任务中,比如将grafana的dashboard链接嵌入到系统中进行展示
4、停止任务
单击停止按钮以停止任务
例子
示例一:APM 监控 - 采集 所有执行时间超过 3 秒的慢速链接并配置警报策略
1、设置kafka为数据源
从 kafka 读取跟踪日志
{
"groupId":"anymetrics_apm_slow_trace",
"kafkaAddress":"192.168.0.1:9092",
"topic":"p_bigtracer_metric_log",
"type":"kafka"
}
2、设置采集规则
通话记录是结构化数据,例如:
1617953102329,operation-admin-web,10.8.60.41,RESOURCE_MYSQL_LOG,com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList,1,1,0,0,1
因此,第一步是使用正则规则对数据进行提取和过滤,对应的正则规则为:
(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?)
提取的数据为:
{
"$4":"RESOURCE_MYSQL_LOG",
"$5":"com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList",
"$6":"1",
"$7":"1",
"$10":"1",
"$8":"0",
"$9":"0",
"$1":"1617953102329",
"$2":"operation-admin-web",
"$3":"10.8.60.41"
}
我们有 10 个变量,从 1 美元到 10 美元。由于我们监控的是超过3秒的慢速链接,我们只需要采集RT超过3秒的日志数据,所以我们需要定义一个逻辑运算表达式Filter,对应的EL表达式公式为:
(new java.lang.Double(#$10) / #$6) > 3000
其中#$10是链接的总响应时间,#$6是接口的总调用次数,先通过#$10/#$6运算得到平均RT,再通过(#$10/#$过滤掉3 6) > 3000 几秒内的慢速链接数据
根据以上两条采集规则,完整配置为:
{
"timeWindow": 40,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\n",
"type": "regular"
},
{
"expression": "(new java.lang.Double(#$10) / #$6) > 3000",
"type": "el"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_apm_slow_trace",
"labelNames": [
"application",
"type",
"endpoint"
],
"name": "anymetrics_apm_slow_trace",
"type": "gauge",
"value": "new java.lang.Double(#$10) / #$6",
"labels": [
"$2",
"$4",
"$5"
]
}
],
"type": "prometheus",
"job": "anymetrics_apm_slow_trace"
}
promethus的metrics需要定义,名字是anymetrics_apm_slow_trace,类型是gauge,lableNames使用application,type,endpoint,对应变量$2、$4、$5,因为响应时间采集RT,所以值为#$10 / #$6
其中#$10是链接的总响应时间,#$6是接口的总调用次数,通过#$10/#$6的运算得到平均RT
4、配置警报和可视化
4.1 可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_apm_slow_trace{}
关于 PromQL 可以参考
4.2 配置 Grafana 警报
在面板中选择警报选项卡以定义警报规则,例如:
每 1m 评估 1m
条件
NoData 和错误处理
通知
一个比较完整的APM监控组合如下:
通过调用链log采集不同维度的metrics,完成对链路RT、项目错误数、项目平均RT、链路RT分布等的多维度监控。
示例2:可视化注册用户总数
1、设置mysql为数据源
根据sql查询总用户数
{
"password": "root",
"jdbcurl": "jdbc:mysql://192.168.0.1:3306/user",
"type": "mysql",
"sql": "select count(1) from user",
"username": "root"
}
2、设置采集规则
根据sql查询的结果,提取count(1),用正则表达式采集规则:
{
"kind": "schedule",
"interval": 5,
"filters": [
{
"expression": "\\{\\\"count\\(1\\)\\\":(.*)\\}",
"type": "regular"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_member_count",
"name": "anymetrics_member_count",
"type": "gauge",
"value": "#$1"
}
],
"type": "prometheus",
"job": "anymetrics_member_count"
}
promethus的metrics需要定义,名字是anymetrics_member_count,类型是gauge,因为只需要采集用户总数,所以不需要定义labels和labelNames,值为#$1
4、配置可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_member_count{}
示例 3:Nginx 日志监控
Nginx请求延迟监控,Nginx状态码监控
1、设置kafka为数据源
使用 nginx access_log 日志
{
"groupId":"anymetrics_nginx",
"kafkaAddress":"192.168.0.1:9092",
"topic":"nginx_access_log",
"type":"kafka"
}
2、设置采集规则
假设nginx的log_format配置如下:
log_format main '"$http_x_forwarded_for" $remote_addr - $remote_user [$time_local] $http_host "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" $upstream_addr $request_method $upstream_status $upstream_response_time';
因此,在第一步中,使用正则Filter对数据进行提取和过滤,对应的正则为:
(.*?)\\s+(.*?)\\s+-(.*?)\\s+\\[(.*?)\\]\\s+(.*?)\\s+\\\"(.*?)\\s+(.*?)\\s+(.*?)\\s+\\\"?(\\d+)\\s+(\\d+)\\s\\\"(.*?)\\\"\\s+\\\"(.*?)\\\"\\s+(.*?)\\s+(.*?)\\s+(\\d+)\\s+(.*)",
提取的数据为:
$1:"-"
$2:192.168.198.17
$3: -
$4:13/Apr/2021:10:48:14 +0800
$5:dev.api.com
$6:POST
$7:/yxy-api-gateway/api/json/yuandouActivity/access
$8:HTTP/1.1"
$9:200
$10:87
$11:http://192.168.0.1:8100/yxy-edu-web/coursetrialTemp?id=123
$12:Mozilla/5.0 (iPhone; CPU iPhone OS 13_4_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko)Mobile/15E148 MicroMessenger/7.0.11(0x17000b21)NetType/WIFI Language/zh_CN
$13:10.8.43.18:8080
$14:POST
$15:200
$16:0.005
一共得到了16个变量,通过对比log_format就可以知道每个变量的含义
完整的采集规则配置为:
{
"timeWindow": 30,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\\s+(.*?)\\s+-(.*?)\\s+\\[(.*?)\\]\\s+(.*?)\\s+\\\"(.*?)\\s+(.*?)\\s+(.*?)\\s+\\\"?(\\d+)\\s+(\\d+)\\s\\\"(.*?)\\\"\\s+\\\"(.*?)\\\"\\s+(.*?)\\s+(.*?)\\s+(\\d+)\\s+(.*)",
"type": "regular"
}
]
}
3、设置采集器
采集每个请求的响应时间和请求的状态码,并将数据存储在promethus中
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "nginx_log_host_status",
"labelNames": [
"host",
"status"
],
"name": "nginx_log_host_status",
"type": "gauge",
"value": "1",
"labels": [
"$5",
"$9"
]
},
{
"help": "nginx_log_req_rt (seconds)",
"labelNames": [
"host",
"endpoint"
],
"name": "nginx_log_req_rt",
"type": "gauge",
"value": "new java.lang.Double(#$16)",
"labels": [
"$5",
"$7"
]
}
],
"type": "prometheus",
"job": "anymetrics_nginx_log"
}
4、配置可视化
Nginx状态码监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_host_status{}
Nginx 请求延迟监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_req_rt{}
问答
如何采集 APM 日志?
如果系统中有调用链跟踪系统,可以使用调用链日志,或者通过定义*敏*感*词*来记录目标方法。定义好日志格式后,可以直接逐行打印,也可以在内存中聚合后以固定频率打印,日志一般收录RT延迟、错误/成功次数、端点、应用等关键数据。
日志是如何采集到kafka的?
可以使用filebeat采集nginx的access_log和tomcat的应用日志到kafka
目前支持哪些数据源?
有界数据目前支持mysql、http;无界数据目前支持kafka
目前支持哪些采集器?
目前只支持prometheus,使用pushgateway推送数据到prometheus
如果我已经使用了 Skywalking 和 Zipkin 等呼叫链跟踪系统,是否需要使用 AnyMetrics?
两者之间没有冲突。调用链跟踪系统采集链路的调用关系和APM指标数据。AnyMetrics不仅可以将结构化调用链跟踪系统的指标日志作为数据源来监控系统,还可以将结构化日志作为数据源来监控系统运行,比如监控一些Exception事件,还可以可视化或监控数据库表数据。同时,AnyMetrics 支持跨平台系统,任何系统生成的日志都可以作为数据源。监控系统运行
最后附上github项目地址:
0 个评论
官方客服QQ群
在
线
客
服
其中#是链接的总响应时间,#是接口的总调用次数,通过#/#的运算得到平均RT
4、配置警报和可视化
4.1 可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_apm_slow_trace{}
关于 PromQL 可以参考
4.2 配置 Grafana 警报
在面板中选择警报选项卡以定义警报规则,例如:
每 1m 评估 1m
条件
NoData 和错误处理
通知
一个比较完整的APM监控组合如下:
通过调用链log采集不同维度的metrics,完成对链路RT、项目错误数、项目平均RT、链路RT分布等的多维度监控。
示例2:可视化注册用户总数
1、设置mysql为数据源
根据sql查询总用户数
{
"password": "root",
"jdbcurl": "jdbc:mysql://192.168.0.1:3306/user",
"type": "mysql",
"sql": "select count(1) from user",
"username": "root"
}
2、设置采集规则
根据sql查询的结果,提取count(1),用正则表达式采集规则:
{
"kind": "schedule",
"interval": 5,
"filters": [
{
"expression": "\{\\"count\(1\)\\":(.*)\}",
"type": "regular"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_member_count",
"name": "anymetrics_member_count",
"type": "gauge",
"value": "#
"}
],
"type": "prometheus",
"job": "anymetrics_member_count"
}
promethus的metrics需要定义,名字是anymetrics_member_count,类型是gauge,因为只需要采集用户总数,所以不需要定义labels和labelNames,值为#
4、配置可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_member_count{}
示例 3:Nginx 日志监控
Nginx请求延迟监控,Nginx状态码监控
1、设置kafka为数据源
使用 nginx access_log 日志
{
"groupId":"anymetrics_nginx",
"kafkaAddress":"192.168.0.1:9092",
"topic":"nginx_access_log",
"type":"kafka"
}
2、设置采集规则
假设nginx的log_format配置如下:
log_format main '"$http_x_forwarded_for" $remote_addr - $remote_user [$time_local] $http_host "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" $upstream_addr $request_method $upstream_status $upstream_response_time';
因此,在第一步中,使用正则Filter对数据进行提取和过滤,对应的正则为:
(.*?)\s+(.*?)\s+-(.*?)\s+\[(.*?)\]\s+(.*?)\s+\\"(.*?)\s+(.*?)\s+(.*?)\s+\\"?(\d+)\s+(\d+)\s\\"(.*?)\\"\s+\\"(.*?)\\"\s+(.*?)\s+(.*?)\s+(\d+)\s+(.*)",
提取的数据为:
:"-"
文章采集调用(无界数据来源于正则表达式Filter帮您解决数据的问题!)
优采云 发布时间: 2022-02-07 06:19文章采集调用(无界数据来源于正则表达式Filter帮您解决数据的问题!)
介绍
AnyMetrics - 面向开发人员的、声明性的 Metrics 采集 和监控系统,可以对结构化和非结构化、有界和无界数据执行 采集,通过提取、过滤、逻辑运算等,将结果存储起来在流行的监控系统或存储引擎(如Prometheus、ES)中构建完整的监控系统,用grafana完成数据可视化
数据采集、提取、过滤、存储等都是由配置驱动,无需额外开发。对应AnyMetrics,分别配置数据源、采集规则、采集器。基于这些配置,AnyMetrics 将使用 pipeline 的方式自动完成从 data采集 到数据存储的所有工作
对于有界数据的任务,AnyMetrics 将以固定频率从数据源中提取数据。AnyMetrics 具有内置的 MySQL 数据源。对于具有无限数据的任务,AnyMetrics 会在一个时间窗口内从数据源中拉取数据。批量拉取数据,AnyMetrics 内置 Kafka 类型无界数据源
AnyMetrics的数据源可以是任何系统,例如可以将HTTP请求结果作为数据源,也可以将ES检索结果作为数据源
将非结构化数据转换为结构化数据的目的,可以通过对数据源的原创数据进行提取和过滤来实现。AnyMetrics 中有两个内置的采集规则(Filter),正则表达式和 Spring EL 表达式。完成数据的提取和过滤,使用Spring EL表达式对原创数据和正则表达式提取后的数据完成逻辑运算。过滤器可单独使用或组合使用。FilterChain的方式是顺序执行的
数据提取和过滤后,下一步就是将数据以指定的方式存储在目标系统中。Prometheus 采集器内置于 AnyMetrics 中。通过定义 Metrics,可以将数据推送到 Prometheus 的 PushGateway。
AnyMetrics 的采集器可以将数据推送到任何系统,例如 MySQL、ES 甚至是 WebHook
无论是采集规则配置还是采集器配置,都可以通过可变配置来完成动态配置的替换。变量数据来自正则表达式Filter,通过定义如(.*)可以得到一个名为$1的变量,有Spring EL的地方可以使用#$1来使用变量,其他地方可以使用$1使用变量,以满足从数据提取到数据的重组或者操作操作,什么配置可以支持变量或者Spring EL表达式 根据采集规则和采集器的具体实现,Spring内置的表达式配置AnyMetrics 的 EL 过滤器和 Prometheus 采集器中的值配置支持 Spring EL 表达式和变量(#$1),
AnyMetrics采用插件化设计方式,无论是数据源、采集规则还是采集器都可以扩展。甚至 AnyMetrics 中的内置插件也是以点对点的方式实现的。加载和使用什么插件完全由声明决定。配置
建筑学
技术栈
SpringBoot + Nacos + Vue + ElementUI
安装
启动前需要安装的依赖
安装 nacos(必填)
安装普罗米修斯(可选)
安装推送网关(可选)
启动
启动 AnyMeitris
1 mvn clean package
2 cd boot/target
3 java -Dnacos.address=nacos.ip:8848 -Dnacos.config.dataId=AnyMetricsConfig -Dnacos.config.group=config.app.AnyMetrics -Dauto=true -jar AnyMetrics-boot.jar
启动参数说明
通过 nacos.address 参数指定nacos地址
通过 nacos.config.dataId 参数指定配置在nacos的dataId,默认值为 AnyMetricsConfig
通过 nacos.config.group 参数指定配置在nacos的group,默认值为 DEFAULT
通过 auto 参数控制任务是否自启动,默认值为 false
启动后访问:8080/index.html
如何配置
1、选择任务类型
2.1、有界数据
选择调度间隔,以秒为单位
2.2、选择数据源
选择数据源为mysql(目前只支持mysql),并完善相关配置
3.1、无限数据
输入时间窗口,单位:秒
3.2、选择数据源
选择kafka作为数据源(目前只支持kafka),并完善相关配置
4、采集规则
过滤器支持两种类型,regular 和 el。在正则中使用括号来提取所需的变量。多个变量以 $1、$2 ... $N 的形式命名。在el中,可以使用_#$1 _变量来执行操作
5、采集器
选择prometheus(目前只支持prometheus)并完善metrics相关配置信息,type支持gauge、counter、histogram类型,labels支持$1变量,value支持Spring EL表达式变量操作
运行任务
1、开始任务
点击开始按钮开始任务
2、查看运行日志
点击日志选项卡,查询任务运行日志
3、iframe
点击iframe Tab,将外部系统嵌入到任务中,比如将grafana的dashboard链接嵌入到系统中进行展示
4、停止任务
单击停止按钮以停止任务
例子
示例一:APM 监控 - 采集 所有执行时间超过 3 秒的慢速链接并配置警报策略
1、设置kafka为数据源
从 kafka 读取跟踪日志
{
"groupId":"anymetrics_apm_slow_trace",
"kafkaAddress":"192.168.0.1:9092",
"topic":"p_bigtracer_metric_log",
"type":"kafka"
}
2、设置采集规则
通话记录是结构化数据,例如:
1617953102329,operation-admin-web,10.8.60.41,RESOURCE_MYSQL_LOG,com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList,1,1,0,0,1
因此,第一步是使用正则规则对数据进行提取和过滤,对应的正则规则为:
(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?)
提取的数据为:
{
"$4":"RESOURCE_MYSQL_LOG",
"$5":"com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList",
"$6":"1",
"$7":"1",
"$10":"1",
"$8":"0",
"$9":"0",
"$1":"1617953102329",
"$2":"operation-admin-web",
"$3":"10.8.60.41"
}
我们有 10 个变量,从 1 美元到 10 美元。由于我们监控的是超过3秒的慢速链接,我们只需要采集RT超过3秒的日志数据,所以我们需要定义一个逻辑运算表达式Filter,对应的EL表达式公式为:
(new java.lang.Double(#$10) / #$6) > 3000
其中#$10是链接的总响应时间,#$6是接口的总调用次数,先通过#$10/#$6运算得到平均RT,再通过(#$10/#$过滤掉3 6) > 3000 几秒内的慢速链接数据
根据以上两条采集规则,完整配置为:
{
"timeWindow": 40,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\n",
"type": "regular"
},
{
"expression": "(new java.lang.Double(#$10) / #$6) > 3000",
"type": "el"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_apm_slow_trace",
"labelNames": [
"application",
"type",
"endpoint"
],
"name": "anymetrics_apm_slow_trace",
"type": "gauge",
"value": "new java.lang.Double(#$10) / #$6",
"labels": [
"$2",
"$4",
"$5"
]
}
],
"type": "prometheus",
"job": "anymetrics_apm_slow_trace"
}
promethus的metrics需要定义,名字是anymetrics_apm_slow_trace,类型是gauge,lableNames使用application,type,endpoint,对应变量$2、$4、$5,因为响应时间采集RT,所以值为#$10 / #$6
其中#$10是链接的总响应时间,#$6是接口的总调用次数,通过#$10/#$6的运算得到平均RT
4、配置警报和可视化
4.1 可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_apm_slow_trace{}
关于 PromQL 可以参考
4.2 配置 Grafana 警报
在面板中选择警报选项卡以定义警报规则,例如:
每 1m 评估 1m
条件
NoData 和错误处理
通知
一个比较完整的APM监控组合如下:
通过调用链log采集不同维度的metrics,完成对链路RT、项目错误数、项目平均RT、链路RT分布等的多维度监控。
示例2:可视化注册用户总数
1、设置mysql为数据源
根据sql查询总用户数
{
"password": "root",
"jdbcurl": "jdbc:mysql://192.168.0.1:3306/user",
"type": "mysql",
"sql": "select count(1) from user",
"username": "root"
}
2、设置采集规则
根据sql查询的结果,提取count(1),用正则表达式采集规则:
{
"kind": "schedule",
"interval": 5,
"filters": [
{
"expression": "\\{\\\"count\\(1\\)\\\":(.*)\\}",
"type": "regular"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_member_count",
"name": "anymetrics_member_count",
"type": "gauge",
"value": "#$1"
}
],
"type": "prometheus",
"job": "anymetrics_member_count"
}
promethus的metrics需要定义,名字是anymetrics_member_count,类型是gauge,因为只需要采集用户总数,所以不需要定义labels和labelNames,值为#$1
4、配置可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_member_count{}
示例 3:Nginx 日志监控
Nginx请求延迟监控,Nginx状态码监控
1、设置kafka为数据源
使用 nginx access_log 日志
{
"groupId":"anymetrics_nginx",
"kafkaAddress":"192.168.0.1:9092",
"topic":"nginx_access_log",
"type":"kafka"
}
2、设置采集规则
假设nginx的log_format配置如下:
log_format main '"$http_x_forwarded_for" $remote_addr - $remote_user [$time_local] $http_host "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" $upstream_addr $request_method $upstream_status $upstream_response_time';
因此,在第一步中,使用正则Filter对数据进行提取和过滤,对应的正则为:
(.*?)\\s+(.*?)\\s+-(.*?)\\s+\\[(.*?)\\]\\s+(.*?)\\s+\\\"(.*?)\\s+(.*?)\\s+(.*?)\\s+\\\"?(\\d+)\\s+(\\d+)\\s\\\"(.*?)\\\"\\s+\\\"(.*?)\\\"\\s+(.*?)\\s+(.*?)\\s+(\\d+)\\s+(.*)",
提取的数据为:
$1:"-"
$2:192.168.198.17
$3: -
$4:13/Apr/2021:10:48:14 +0800
$5:dev.api.com
$6:POST
$7:/yxy-api-gateway/api/json/yuandouActivity/access
$8:HTTP/1.1"
$9:200
$10:87
$11:http://192.168.0.1:8100/yxy-edu-web/coursetrialTemp?id=123
$12:Mozilla/5.0 (iPhone; CPU iPhone OS 13_4_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko)Mobile/15E148 MicroMessenger/7.0.11(0x17000b21)NetType/WIFI Language/zh_CN
$13:10.8.43.18:8080
$14:POST
$15:200
$16:0.005
一共得到了16个变量,通过对比log_format就可以知道每个变量的含义
完整的采集规则配置为:
{
"timeWindow": 30,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\\s+(.*?)\\s+-(.*?)\\s+\\[(.*?)\\]\\s+(.*?)\\s+\\\"(.*?)\\s+(.*?)\\s+(.*?)\\s+\\\"?(\\d+)\\s+(\\d+)\\s\\\"(.*?)\\\"\\s+\\\"(.*?)\\\"\\s+(.*?)\\s+(.*?)\\s+(\\d+)\\s+(.*)",
"type": "regular"
}
]
}
3、设置采集器
采集每个请求的响应时间和请求的状态码,并将数据存储在promethus中
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "nginx_log_host_status",
"labelNames": [
"host",
"status"
],
"name": "nginx_log_host_status",
"type": "gauge",
"value": "1",
"labels": [
"$5",
"$9"
]
},
{
"help": "nginx_log_req_rt (seconds)",
"labelNames": [
"host",
"endpoint"
],
"name": "nginx_log_req_rt",
"type": "gauge",
"value": "new java.lang.Double(#$16)",
"labels": [
"$5",
"$7"
]
}
],
"type": "prometheus",
"job": "anymetrics_nginx_log"
}
4、配置可视化
Nginx状态码监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_host_status{}
Nginx 请求延迟监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_req_rt{}
问答
如何采集 APM 日志?
如果系统中有调用链跟踪系统,可以使用调用链日志,或者通过定义*敏*感*词*来记录目标方法。定义好日志格式后,可以直接逐行打印,也可以在内存中聚合后以固定频率打印,日志一般收录RT延迟、错误/成功次数、端点、应用等关键数据。
日志是如何采集到kafka的?
可以使用filebeat采集nginx的access_log和tomcat的应用日志到kafka
目前支持哪些数据源?
有界数据目前支持mysql、http;无界数据目前支持kafka
目前支持哪些采集器?
目前只支持prometheus,使用pushgateway推送数据到prometheus
如果我已经使用了 Skywalking 和 Zipkin 等呼叫链跟踪系统,是否需要使用 AnyMetrics?
两者之间没有冲突。调用链跟踪系统采集链路的调用关系和APM指标数据。AnyMetrics不仅可以将结构化调用链跟踪系统的指标日志作为数据源来监控系统,还可以将结构化日志作为数据源来监控系统运行,比如监控一些Exception事件,还可以可视化或监控数据库表数据。同时,AnyMetrics 支持跨平台系统,任何系统生成的日志都可以作为数据源。监控系统运行
最后附上github项目地址:
0 个评论
官方客服QQ群
在
线
客
服
: -
:13/Apr/2021:10:48:14 +0800
:dev.api.com
:POST
:/yxy-api-gateway/api/json/yuandouActivity/access
:HTTP/1.1"
:200
:87
:http://192.168.0.1:8100/yxy-edu-web/coursetrialTemp?id=123
:Mozilla/5.0 (iPhone; CPU iPhone OS 13_4_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko)Mobile/15E148 MicroMessenger/7.0.11(0x17000b21)NetType/WIFI Language/zh_CN
:10.8.43.18:8080
:POST
:200
:0.005
一共得到了16个变量,通过对比log_format就可以知道每个变量的含义
完整的采集规则配置为:
{
"timeWindow": 30,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\s+(.*?)\s+-(.*?)\s+\[(.*?)\]\s+(.*?)\s+\\"(.*?)\s+(.*?)\s+(.*?)\s+\\"?(\d+)\s+(\d+)\s\\"(.*?)\\"\s+\\"(.*?)\\"\s+(.*?)\s+(.*?)\s+(\d+)\s+(.*)",
"type": "regular"
}
]
}
3、设置采集器
采集每个请求的响应时间和请求的状态码,并将数据存储在promethus中
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "nginx_log_host_status",
"labelNames": [
"host",
"status"
],
"name": "nginx_log_host_status",
"type": "gauge",
"value": "1",
"labels": [
"",
""
]
},
{
"help": "nginx_log_req_rt (seconds)",
"labelNames": [
"host",
"endpoint"
],
"name": "nginx_log_req_rt",
"type": "gauge",
"value": "new java.lang.Double(#)",
"labels": [
"",
""
]
}
],
"type": "prometheus",
"job": "anymetrics_nginx_log"
}
4、配置可视化
Nginx状态码监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_host_status{}
Nginx 请求延迟监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_req_rt{}
问答
如何采集 APM 日志?
如果系统中有调用链跟踪系统,可以使用调用链日志,或者通过定义*敏*感*词*来记录目标方法。定义好日志格式后,可以直接逐行打印,也可以在内存中聚合后以固定频率打印,日志一般收录RT延迟、错误/成功次数、端点、应用等关键数据。
日志是如何采集到kafka的?
可以使用filebeat采集nginx的access_log和tomcat的应用日志到kafka
目前支持哪些数据源?
有界数据目前支持mysql、http;无界数据目前支持kafka
目前支持哪些采集器?
目前只支持prometheus,使用pushgateway推送数据到prometheus
如果我已经使用了 Skywalking 和 Zipkin 等呼叫链跟踪系统,是否需要使用 AnyMetrics?
两者之间没有冲突。调用链跟踪系统采集链路的调用关系和APM指标数据。AnyMetrics不仅可以将结构化调用链跟踪系统的指标日志作为数据源来监控系统,还可以将结构化日志作为数据源来监控系统运行,比如监控一些Exception事件,还可以可视化或监控数据库表数据。同时,AnyMetrics 支持跨平台系统,任何系统生成的日志都可以作为数据源。监控系统运行
最后附上github项目地址: