文章采集组合工具( 通常文本Web内容转换为数据分为以下三个以下基本步骤)
优采云 发布时间: 2022-02-04 02:18文章采集组合工具(
通常文本Web内容转换为数据分为以下三个以下基本步骤)
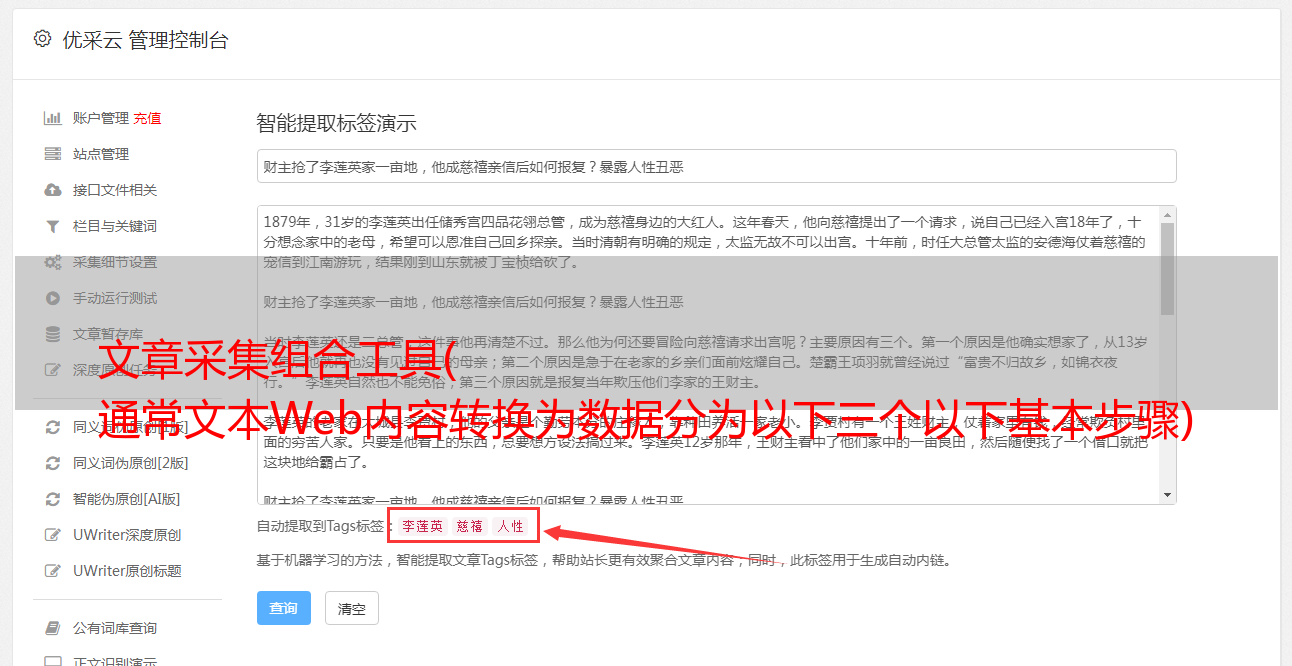
数据分析是指用适当的统计分析方法对采集到的大量数据进行分析,提取有用信息并形成结论,对数据进行详细研究和概括的过程。数据分析让我们的决策更科学!
但是,现在很多数据分析都有一个通病:有很多低质量的数据,最终导致数据分析结果偏低,正如美国前首席数据科学家 DJ Patil 所说:“说得也不过分:80任何数据项目中的工作百分比 他们正在清理 采集 的数据。” 如果不能采集优质的数据资源,那么高级的分析算法就没用了。
作为成都本地的Daas(数据和服务),我们为您提供干净、结构化和有组织的网络数据,使您的数据分析尽可能准确。但同时,我们也想把网络数据采集的一些知识传递给您,避免您在数据采集的过程中产生低质量的数据。
爬虫的方法采集
我们中的绝大多数人每天都在使用网络——获取新闻、购物、社交以及您能想象到的任何类型的活动。但是,当出于分析或研究目的从 Web 获取数据时,需要以更技术性的方式查看 Web 内容 - 将其拆分为构成它的构建块,然后将它们重新组合成结构化的机器可读数据集。通常将文本网页内容转换为数据分为以下三个基本步骤:
爬虫
网络爬虫是自动访问网页的脚本或机器人,其作用是从网页中抓取原创数据——最终用户在屏幕上看到的各种元素(字符、图片)。它的工作方式就像一个机器人,在网页上带有 ctrl+a(全选)、ctrl+c(复制内容)、ctrl+v(粘贴内容)按钮(当然它实际上没那么简单)。
通常,爬虫不会停留在网页上,而是会根据某些预定逻辑在停止之前爬取一系列 URL。例如,它可能会跟踪它找到的每个链接,然后抓取该 网站。当然,在这个过程中,你需要优先考虑你抓取的 网站 的数量,以及你可以为任务投入的资源数量(存储、处理、带宽等)。
解析
解析意味着从数据集或文本块中提取相关信息组件,以便以后可以轻松访问它们并用于其他操作。要将网页转换为对研究或分析实际有用的数据,我们需要以一种使数据易于搜索、排序和基于定义的参数集提供服务的方式对其进行解析。
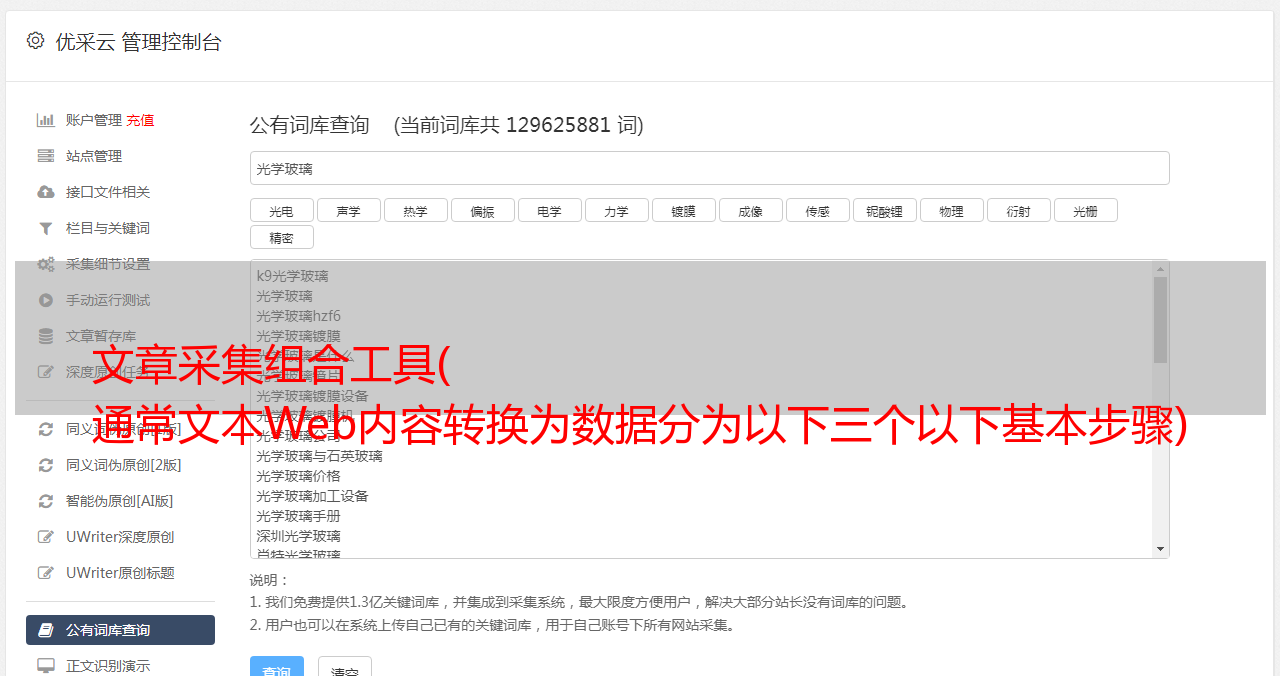
存储和检索
最后,在获得所需的数据并分解成有用的组件后,有一种可扩展的方法将所有提取和解析的数据存储在数据库或集群中,然后创建一个数据库或集群,让用户能够及时找到相关的数据集方式或提取的特征。
现在我们已经了解了爬虫采集 方法,是时候开始思考可用于获取所需数据的各种工具和技术了。数据爬虫采集的工具大致如下;
DIY(定制)
第一个是编写自己的网络爬虫,抓取你需要的任何数据,并尽可能频繁地运行它(这需要你的公司有懂爬虫技术的人)。
这种方法的主要优点是它的高度灵活性和可定制性:您可以准确定义要获取的数据、频率以及您希望如何解析自己数据库中的数据。
这使您可以根据计划的确切范围定制 Web采集 模式,适用于爬取一组非常具体的 网站(范围相对较小)。
然而,自定义爬取并非没有缺点,尤其是在涉及更复杂的项目时。假设你想了解更广泛的海量趋势网站,DIY 爬虫变得更加复杂——需要更多的计算资源和开发时间投入。
用于临时分析的爬虫
另一种常见的技术是购买商业刮刀,它消除了 DIY 方法的一些复杂性,但是,它们仍然最适合特定项目 - 即在特定时间间隔刮取特定 网站。
如果你想建立一个更*敏*感*词*的操作,重点不是自定义解析,而是对开放网络的全面覆盖,由于频繁的数据刷新率和易于访问大型数据集,刮板不太适合,以下问题将遇到:
商业爬虫为临时项目提供更好的技术支持,提供从特定 网站s 获取和解析数据的高度复杂的方法。然而,在为万维网构建综合数据采集解决方案时,它们的可扩展性和可行性较差;那是您需要更强大的“数据抓取服务”的时候。
DaaS 服务提供商提供的 Web 服务
第三种,您无需进行数据爬取和分析,由专业数据服务(DaaS)提供商全权负责。在此模型中,您可以获得由 DaaS 提供商提取的干净、结构化和有组织的数据,使您能够跳过构建或购买自己的提取基础设施的整个过程,并专注于您正在开发、研究或产品的分析。
但是,对于大型运营,Web 数据即服务在规模和易于开发方面提供了几个独特的优势:
这些优势使 Web 数据和服务成为媒体监控、财务分析、网络安全、文本分析以及需要快速访问频繁更新的数据源的最佳解决方案。
除了提供更多结构化数据之外,我们还为企业和组织提供更多替代数据以应用预测分析,让您做出更明智的投资决策。

