wordpress文章采集软件(Web网站CDN端口信息IP地址com )
优采云 发布时间: 2022-01-28 10:10wordpress文章采集软件(Web网站CDN端口信息IP地址com
)
Tag: Web网站CDN端口信息IP地址Side Station Server com
【网络安全】二.Web渗透信息采集域名、端口、服务、指纹、侧站、CDN及敏感信息
最近开始学习网络安全和系统安全,接触了很多新名词、新方法、新工具。作为一个初学者,我觉得安全领域涉及的知识非常广泛和复杂,但同时也非常有趣。所以希望通过这100多篇关于网络安全的文章文章,与大家分享Web渗透的相关工作、知识体系、学习路径和探索过程。站立。不知道攻击,又怎么会防御,我们一起来看看,好好珍惜,希望大家多多推荐和支持作者公众号。
2020年8月18日开放的那张AI安全之家将聚焦Python和安全技术,主要分享Web渗透、系统安全、人工智能、大数据分析、图像识别、恶意代码检测、CVE复现、威胁情报分析等。 文章。我真的很想把我这十年的所学和所做的分享给大家,和大家一起进步。
这个文章重构了作者的CSDN系列,也参考了哔哩哔哩、谢公子、阿干哥的文章。真心推荐白帽谢公子阿干哥的文章,写的真好。(文章见文末参考资料)
免责声明:作者虽然是安全新手,但会保证每一个文章都会用心编写。希望这些基本的文章对你有所帮助,在安全的道路上共同前行。同时,我坚决反对利用教学手段进行恶意攻击。所有的错误行为都将受到严惩。绿网需要我们共同维护,建议大家了解技术背后的原理,更好的安全防护。
文章目录:
一.web渗透第一步
网站 是安装在具有操作系统、应用程序和服务器的计算机上的应用程序。例如 WAMP 包括:
网站HTML站点访问的基本流程如下图所示:客户端输入访问URL,DNS服务器将域名解析成IP地址,然后IP地址访问服务器内容(服务器、数据库、应用程序),最后将内容反馈到客户端的浏览器。
该数据库包括要调用的数据,并存储在具有真实 IP 地址的 Web 服务器上,每个人都可以访问和 ping。每次请求页面或运行程序时,Web 应用程序都会在服务器上执行,而不是在客户端机器上执行。

那么,如何破解 网站?
入侵安装在计算机上的应用程序称为Web应用程序渗透测试,入侵计算机和带有操作系统的应用程序称为服务器端攻击,入侵人称为社会工程攻击。在我们潜入Web之前,与其获取目标并开始使用Webdirscan、SQLMAP、Caidao、Cobalt Strike等工具,不如先获取网站的全面(指纹)信息。我们获得的信息越多,就越容易找到底层漏洞或注入点。
采集信息有两种方式:主动和被动。
通常采集的信息包括:
这篇文章会讲解web渗透的第一步——信息采集。正好弥补了我们安全初学者的入门,同时可以增强学习安全的兴趣,希望大家喜欢。文笔不足,还请海涵。
二.域名信息采集1.域名查询
域名系统
域名系统 (DNS) 是 Internet 的一项服务。它充当一个分布式数据库,将域名和 IP 地址相互映射,使人们更容易访问 Internet。简单来说,就是一个将域名翻译成IP地址的系统。
域名由一串以点分隔的名称组成,是互联网上的计算机或计算机组的名称,用于在数据传输过程中识别计算机(有时也指地理位置)。浏览网站的过程如下图所示,从DNS服务器获取指定域名对应的IP地址。
域名系统
例如作为域名,对应IP地址198.35.26.96。DNS就像一个自动电话目录,我们可以直接拨打198.35.26.96的名字而不是电话号码(IP地址)。我们直接调用网站的名字后,DNS会把198.35.26.96这样的名字转换成机器容易识别地址的IP。又如域名,是域名对应的子域名,edu(教育网)和www(万维网)是对应的主机名。
2.Whois 查询
Whois 是一种传输协议,用于查询域名的 IP 和所有者。简单来说,Whois就是一个用于查询一个域名是否已经注册的数据库,以及注册的域名信息(如域名所有者、域名注册商、注册商邮箱等)。
不同域名后缀的whois信息需要从不同的whois数据库中查询,如.com的whois数据库和.edu的区别。每个域名或IP的Whois信息由相应的管理机构保存。例如,以.com结尾的域名的Whois信息由.com的运营商威瑞信管理,由CNNIC(中国互联网信息中心)管理。
Whois协议的基本内容是:首先与服务器的TCP 43端口建立连接,发送查询关键字并添加回车换行,然后从服务器接收查询结果。

Whois查询可用于获取域名注册人的邮箱等信息。一般对于中小网站域名注册人来说,就是网站管理员。多域注册人的个人信息。
whois查询方法:
(1) 网页界面查询
常用信息采集网站包括:
(2) 通过 Whois 命令查询
Kali Linux 自带的 Whois 查询工具可以通过 Whois 命令查询域名信息。
(3) Python 编写 Whois 代码
import urllib.request
req_whois = urllib.request.urlopen('http://whois.chinaz.com/doucube.com')
print(req_whois.read().decode())
导入whois
数据 = whois.whois("")
打印(数据)
例子:
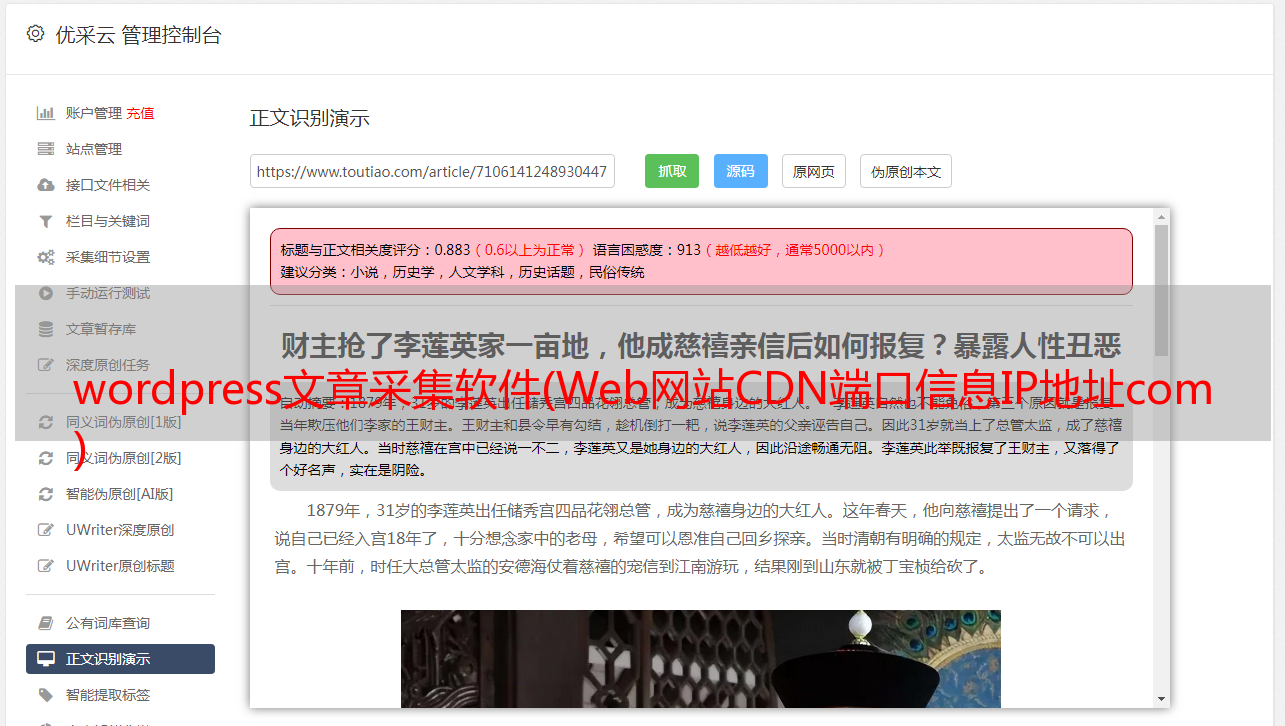
以下是东山网站()使用站长之家Whois的相关信息。可以看到网站的标题是“秀张学习世界”,网站的服务器是阿里云,2021年到期。联系邮箱、DNS和域名服务器也可以询问。一些网站可能会泄露私人电话号码、电子邮件地址和地址,并将接受进一步的社会工作。
然后作者使用Robtex DNS查询网站的相关信息,显示如下,添加IP地址内容(60.xxx.xxx.36),然后通过 网站 可以定位物理地址。
Netcraft 站点报告显示目标 网站 信息如下,包括 网站 构建框架和操作系统。
3.备案信息查询
ICP备案是指互联网内容提供商(Internet Content Providers)。《互联网信息服务*敏*感*词*》规定网站需备案,未经许可不得提供互联网信息服务。
IPC备案查询方式包括:
比如作者和哔哩哔哩的备案信息网站如下图所示。你在这里找到什么了吗?

三.网站信息采集1.cms指纹
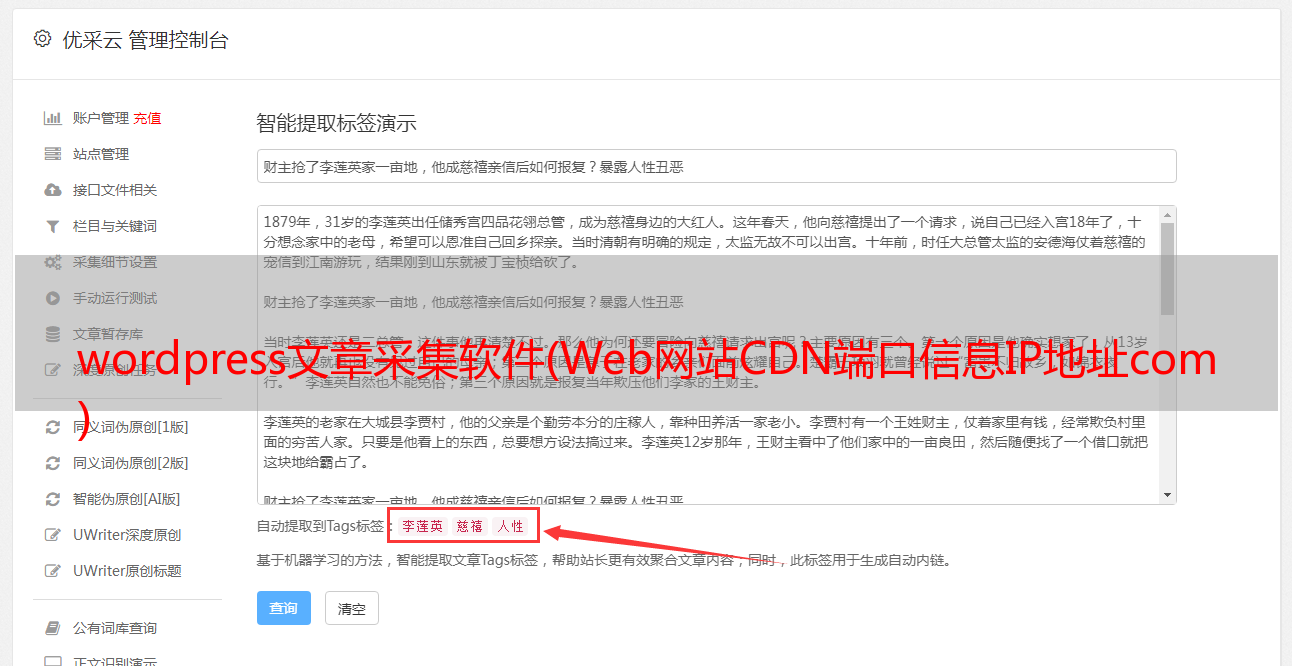
在渗透测试中,对目标服务器进行指纹识别是非常有必要的,因为只有识别出对应的web容器或者cms(内容管理系统),才能找到相关的漏洞,然后进行相应的渗透操作。cms又称全站系统。常见的cms有:WordPress、Dedecms (织梦)、Discuz、PhpWeb、PhpWind、Dvbbs、Phpcms、ECShop、、SiteWeaver、Aspcms 、帝国、Z-Blog 等。
cms也称为站点范围系统或文章系统,用于网站内容管理。用户只需下载对应的cms软件包进行部署构建,直接使用cms即可。但是,各种cms都有自己独特的结构命名约定和具体的文件内容,可以用来获取cms站点专用软件cms和版本。
常用识别工具:
(1) 在线工具
(2) 本地工具
例子:
以某站为例,通过网站识别指纹,发现是Discuz搭建的。信息包括:
接下来,将 Github 上的大鱼下载到本地,进行cms扫描。
2.cms漏洞查询
对于查询到的cms,可以使用暗云漏洞库网站查询并制定cms的漏洞。
展示如下图,包括详细的利用过程和防御措施。

3.敏感目录信息
检测目标Web目录结构和敏感隐藏文件非常重要。在检测过程中,很可能会检测到后台页面、上传页面、数据库文件,甚至是网站源代码文件。补充谢公子的内容,扫描网站目录结构,看目录是否可以遍历,或者敏感文件是否泄露,包括:
常见的检测工具包括:
文件 robots.txt
同时,提到网站敏感目录时,不得不提到robots.txt文件。robots.txt 文件是专门为搜索引擎机器人编写的纯文本文件。我们可以在 网站 中指定我们不想被该文件中的机器人访问的目录。这样我们的部分或全部 网站 内容将不会被搜索引擎 收录 搜索,或者让搜索引擎仅 收录 指定内容。
因此,我们可以通过robots.txt来阻止Google的机器人访问我们网站上的重要文件,Google Hack的威胁是不存在的。假设robots.txt文件的内容如下,其中“Disallow”参数后面是禁止robot收录部分的路径。例如,我们希望机器人禁止 收录网站 目录中的“数据”。”文件夹,只需在 Disallow 参数后添加 /data/ 即可。如果要添加其他目录,只需继续以这种格式添加即可。您可以通过在编写文件后将文件上传到 网站 的根目录来使 网站 远离 Google Hack。
User-agent:
Disallow: /data/
Disallow: /db/
Disallow: /admin/
Disallow: /manager/
Allow:/images/
但是,虽然robots文件的目的是防止搜索蜘蛛爬取你要保护的页面,但是如果我们知道robots文件的内容,就可以知道目标网站不允许访问哪些文件夹,从旁注这些文件夹非常重要。
御剑
御剑系列的Web工具一直都是比较方便的工具。这把御剑也是一个很好用的网站后台扫描工具,有图形化的页面,而且好用,所以也受到了大部分人的喜爱。它的作者可能是《孤单的剑客》。
迪布
dirb 是一个基于字典的网络目录扫描工具,可以递归地获取更多目录。它还支持代理和 http 身份验证来限制访问 网站。
迪尔巴斯特
Kali Linux 提供的目录扫描工具 DirBuster 支持所有的 web 目录扫描方式。它同时支持网络爬虫扫描、基于字典的暴力扫描和纯暴力扫描。该工具用 Java 语言编写,提供命令行(Headless)和图形界面(GUI)模式。用户不仅可以指定纯暴力扫描的字符规则,还可以设置URL混淆构建的网页的路径。同时,用户还可以自定义各种网页解析方式,提高URL解析效率。

4.WordPress 测试
WordPress 是一个用 PHP 语言开发的博客平台。用户可以在支持 PHP 和 MySQL 数据库的服务器上构建自己的网站,或者使用 WordPress 作为内容管理系统cms。对于 WordPress 测试,可以使用 WpScan 工具对其进行安全测试。
例如,要识别官方的网站框架信息,可以调用whatwep命令或在线网站获取其cms信息。
如果发现目标 网站 是 WordPress 构建,请使用 WPScan 检测它。
四.端口信息采集1.端口介绍
如果将 IP 地址比作房屋,那么端口就是进出房屋的门。一个真实的房子只有几扇门,但一个IP地址的端口可以有多达65536(21个6)门。端口由端口号标记,端口号只是0到65536(216 - 1)。
计算机的常用端口号包括:
计算机上的每个端口都代表一个服务。使用 netstat -ano | netstat -anbo 在 Windows 命令行上显示打开的端口。
CMD需要管理员权限才能打开,输入netstat -anbo查看打开的端口。其中,443端口是HTTPS建立的连接,80端口是网站HTTP建立的连接。
2.端口信息采集
工具可用于采集目标及其端口状态。工作原理是利用TCP或UDP等协议向目标端口发送指定标志位等数据包,等待目标返回数据包,判断端口状态。后续作者,准备通过Python编写相关代码。
这个文章主要是通过工具采集的端口信息,包括:
例子:
检查本地端口的开放状态,命令为:
使用masscan检测端口开放信息,命令为:
工具的使用往往会在目标网站上留下痕迹,接下来提供在线网站探测的方法。
例子:
使用站长之家检测到作者网站的80端口是开放的,443端口是关闭的(最早支持多端口扫描,目前只支持单端口扫描,有读者的就更好了可以自己写程序)。

接下来,使用ThreatScan在线网站扫描作者的网站信息。
ThreatScan 是一种扫描仪,主要用于渗透测试的第一阶段:信息采集。这里强烈推荐DYBOY大神的博客。地址是: 。
作者只开放了80端口访问网页,21端口进行FTP访问。
3.Side Station 和 C 段扫描
侧站指的是同一服务器上的其他网站,很多时候,一些网站可能没那么容易被黑。然后,查看这个网站所在的服务器上是否还有其他的网站。如果还有其他网站,可以先把其他网站的webshell拿下来,然后再升级权限获取服务器权限,最后就可以拿下网站了!
对于红蓝对抗和网保,C段扫描更有意义。对于单独的 网站 渗透测试,C 段扫描意义不大。Segment C是指同一内网段中的其他服务器。每个 IP 有四个段 ABCD。比如192.168.0.1,A段是192,B段是168,C段是0,D段是1,C段嗅探就是拿下同一C段的服务器中的一台,即D段1-255服务器中的一台,然后使用工具嗅探将服务器取下来。侧站、C段在线查询地址:
侧站扫描可以扫描其他链接到该IP地址的网站,有利于Web穿透,侧站可能存在漏洞,如下图所示。
4.端口攻击
不同的端口有不同的攻击方式,因为每个端口都是录音服务器或者目标系统的门,只要打开门,就可以进入目标系统。例如远程连接服务端口的攻击方法如下,由于23端口的Telnet远程连接以明文形式传输信息,可以通过爆破、嗅探、弱密码等方式进行攻击。
这里给大家推荐一下:当我们扫描目标网站的端口号时,可以在搜索引擎中找到对应的攻击方式进行测试,或者在乌云漏洞库()或者CVE库中搜索。例如:
注意:CVE漏洞的复用是网络攻击的常用手段。还需要第一时间提醒厂商打补丁,用户更新一些软件的版本也是需要的。
5.防御措施
对于端口攻击,只要端口是开放的并且可以连接的,就可以使用相应的方法来测试攻击。这里提供的防御包括:
五.敏感信息采集
对于一些安全性较好的目标,渗透测试无法直接通过技术层面进行。在这种情况下,互联网上暴露的相关信息可以被搜索引擎定位。例如:数据库文件、SQL注入、服务配置信息,甚至通过Git泄露站点源代码、Redis等非授权访问、Robots.txt等敏感信息,从而达到渗透的目的。
在某些情况下,采集的信息对于以后的测试可能很重要。如果直接通过采集敏感信息获得目标系统的数据库访问权限,那么渗透测试任务就完成了一半以上。因此,在技术条件下进行测试之前,应采集更多信息,尤其是敏感信息。
1.Google 黑客语法
Google Hack是指利用谷歌、百度等搜索引擎搜索一些特定的网站主机漏洞(通常是服务器上的脚本漏洞),以快速找到易受攻击的主机或特定主机的漏洞. 常用方法包括:
谷歌提供了强大的搜索功能来获得精确的结果。如果无法访问,也可以通过百度获取相关内容,但结果远不如谷歌准确,还会返回很多不相关的广告和视频。一个例子如下:
谷歌黑客数据库是:. 例如,要查询数据 Access 数据库,请使用 filetype:mdb "standard jet" (password | username | user | pass)。

