搜索引擎优化知识完全手册(【干货】一下了一下日常开发过程中的调优经验)
优采云 发布时间: 2022-01-26 13:01搜索引擎优化知识完全手册(【干货】一下了一下日常开发过程中的调优经验)
大家好,这里是程序员cxuan,欢迎阅读我最新一期的文章,这个文章是MySQL调优的总结版,我在日常开发过程中添加了一些调优经验,希望可以会帮助你们。下面开始正文。
一般来说,传统的互联网公司很少会遇到 SQL 优化问题。原因是数据量小,大部分厂商的数据库性能都可以满足日常业务需求,所以不需要SQL优化。数据库本身的性能跟不上流量的激增。这时候就需要从SQL本身的角度进行优化,也就是我们在本篇文章中讨论的内容。
SQL优化步骤
面对需要优化的SQL,我们有哪些排查思路?
通过 show status 命令查看 SQL 执行次数
首先,我们可以使用 show status 命令查看服务器状态信息。show status 命令显示每个服务器变量 variable_name 和 value。状态变量是只读的。如果使用 SQL 命令,可以使用 like 或 where 条件来限制结果。like 可以对变量名进行标准模式匹配。
我没有截取图片的截图。下面有很多变数。读者可以自己试一试。您还可以在操作系统上使用 mysqladmin extended-status 命令来获取这些消息。
但是在我执行 mysqladmin extended-status 之后,我得到了这个错误。
这应该是我没有输入密码的原因。使用mysqladmin -P3306 -uroot -p -h127.0.0.1 -r -i 1 extended-status 后,问题解决。
这里需要注意的是可以添加到show status命令中的统计结果的级别。这个级别有两个级别。
如果不指定统计结果级别,则默认使用会话级别。
对于show status查询的统计结果,有两类参数需要注意:一类以Com_开头,一类以Innodb_开头。
以下是以 Com_ 开头的参数。参数很多,我没有全部删减。
Com_xxx 表示每条 xxx 语句的执行次数。我们通常关心的是select、insert、update和delete语句的执行次数,即
Innodb_开头的参数主要是
通过对以上参数执行结果的统计,我们可以大致了解当前数据库主要是更新(包括插入、删除)还是查询。
除此之外,还有一些其他的参数用来了解数据库的基本情况。
下面的博客总结了几乎所有show status的参数,可以作为参考手册。
找到执行效率较低的 SQL
定位执行效率慢的SQL语句一般有两种方式
MySQL提供了慢查询日志功能,可以将查询SQL语句时间大于多少秒写入慢查询日志。在日常维护中,可以利用慢查询日志的记录信息,快速准确的判断问题所在。当使用 --log-slow-queries 选项启动时,mysqld 会写入一个日志文件,其中收录所有执行时间超过 long_query_time 秒的 SQL 语句,并通过查看此日志文件来定位效率低下的 SQL。
比如我们可以在f中加入如下代码,然后退出并重启MySQL。
log-slow-queries = /tmp/mysql-slow.log
long_query_time = 2
通常我们将最长查询时间设置为2秒,也就是说查询时间超过2秒就记录下来,通常2秒就够了,但是对于很多WEB应用来说,2秒还是比较长的。
也可以通过以下命令开启:
我们先检查一下MySQL慢查询日志是否开启
show variables like "%slow%";
开启慢查询日志
set global slow_query_log='ON';
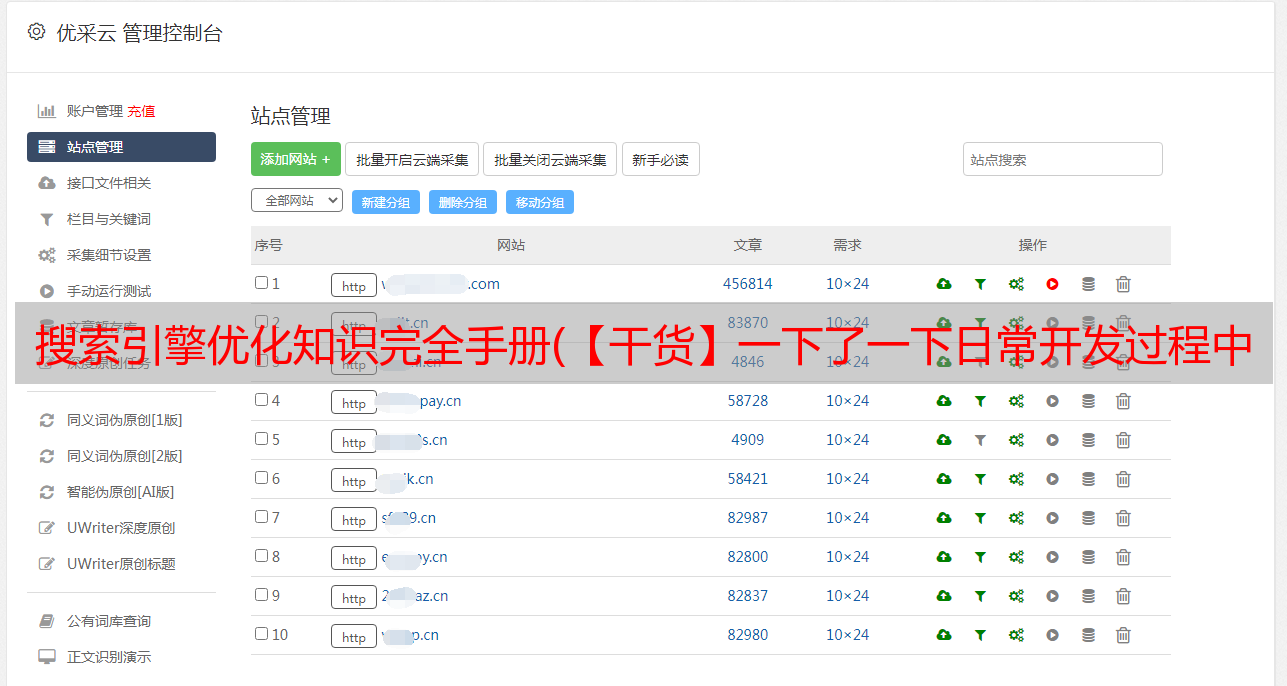
然后再次检查是否开启了慢查询
如图,我们开启了慢查询日志。
查询完成后会记录慢查询日志,所以当应用响应执行效率出现问题时,慢查询日志无法定位问题。这时候应该使用 show processlist 命令查看当前 MySQL 线程。包括线程状态、是否锁表等,可以实时查看SQL执行情况。同样,可以使用 mysqladmin processlist 语句获取此信息。
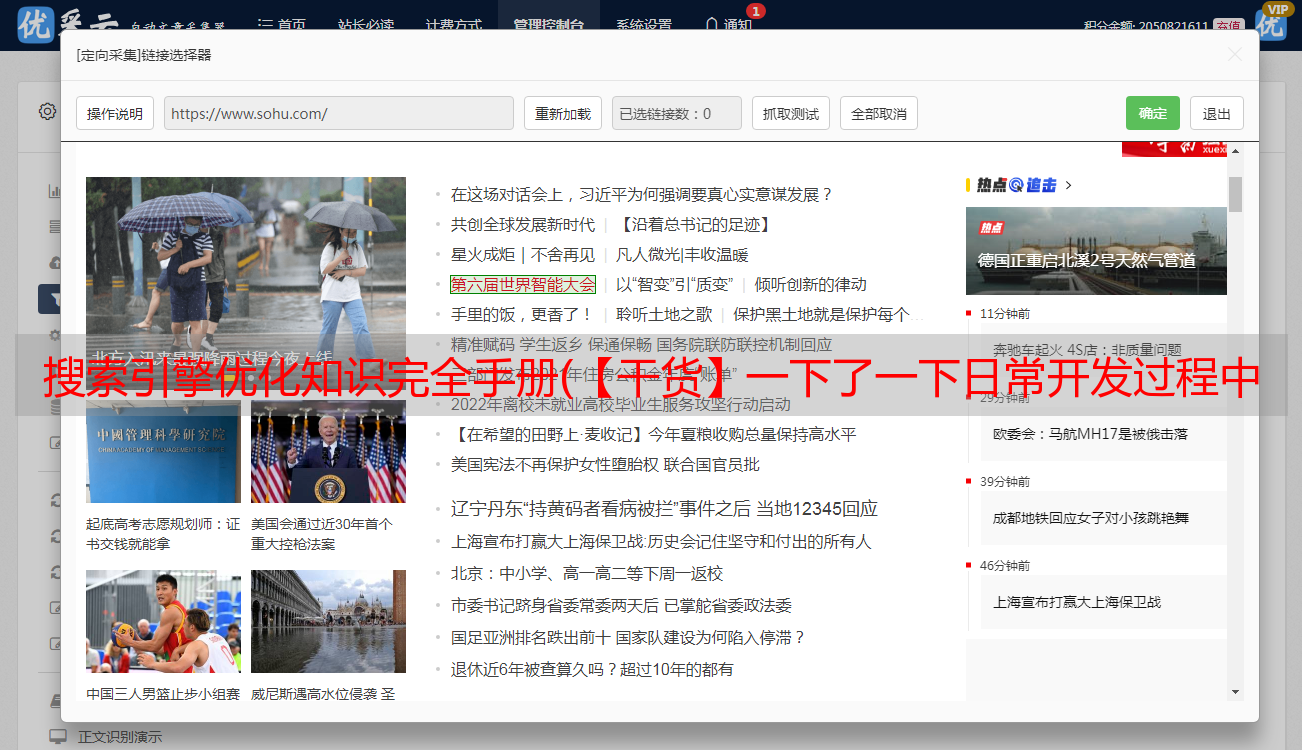
让我们解释一下每个字段对应的概念。
状态栏非常重要。关于这个专栏的内容很多。读者可以参考这篇文章文章
这涉及到诸如线程状态和是否锁定表等选项。可以实时查看SQL的执行情况,同时优化部分锁表。
通过EXPLAIN命令分析SQL的执行计划
通过以上步骤查询到效率低下的 SQL 语句后,可以使用 EXPLAIN 或 DESC 命令获取 MySQL 执行 SELECT 语句的信息,包括表是如何连接的,以及执行 SELECT 语句过程中的连接顺序.
例如,我们使用下面的 SQL 语句来分析执行计划
explain select * from test1;
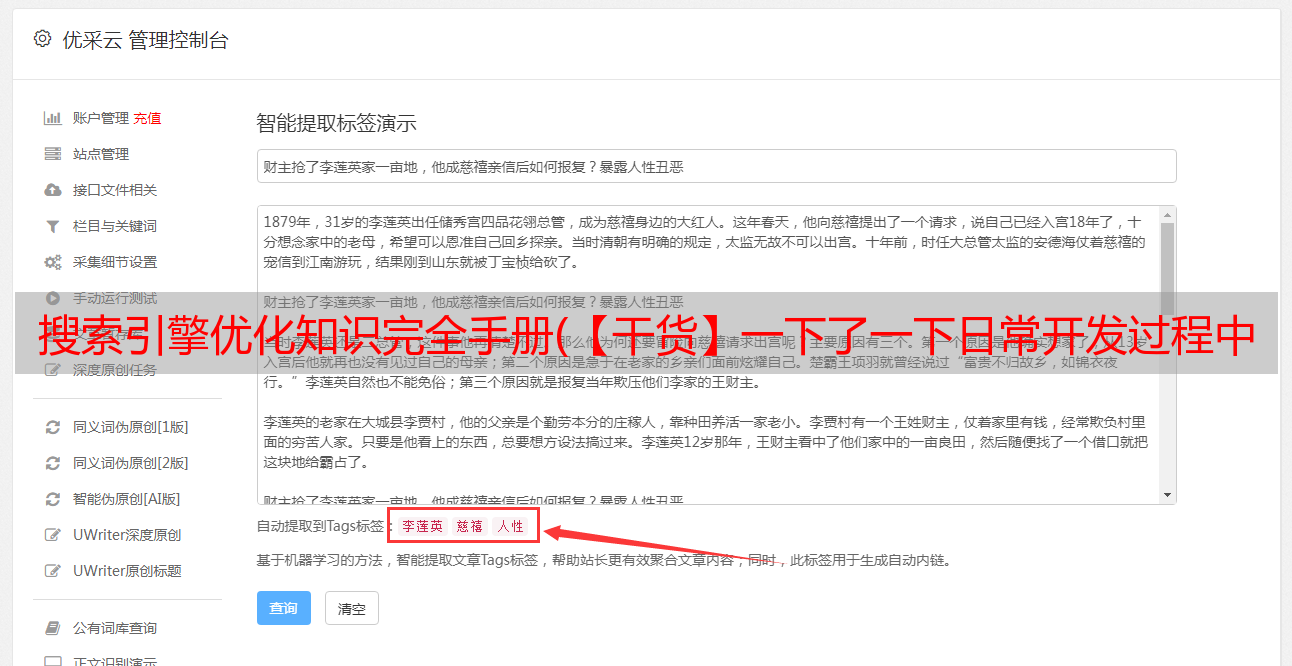
上表内容如下
PRIMARY ,查询中最外层的 SELECT (例如,如果两个表是 UNION 或者外表操作与子查询是 PRIMARY,内操作是 UNION),比如下面的子查询。
UNION,在UNION操作中,查询中的内层SELECT(当内层SELECT语句对外层SELECT语句没有依赖时)。
SUBQUERY:子查询中的第一个SELECT(如果有多个子查询),比如我们上面的查询,第一个子查询是sr(sys_role)表,所以它的select_type就是SUBQUERY。
以上是对type内容的大致说明。关于类型,我们在SQL调优中经常使用explain来分析其类型,进而改进查询方法。离系统越近,查询效率越高,离所有越近,查询效率越低。
通过以上分析,我们可以大致判断出SQL效率低下的原因。提高 SQL 查询效率的一个非常有效的方法是使用索引。接下来,我将解释如何使用索引来提高查询效率。
指数
索引是数据库优化中最常用和最重要的方法。大多数SQL性能问题可以通过使用不同的索引来解决,也是面试中经常被问到的一种优化方法。围绕索引,面试官可以让你造火箭,所以总结一下,索引是非常非常重的!想!不仅要使用,还需要了解它的来历!原因!
索引介绍
索引的目的是快速找到某一列中的数据。在相关数据列上使用索引可以大大提高查询操作的性能。如果没有索引,MySQL 必须从第一条记录读取整个表,直到找到相关行。表越大,查询数据所需的时间就越多。如果表中查询的列有索引,MySQL可以快速到一个地方搜索数据文件,而不必查看所有数据,这样会节省很多时间。
索引分类
我们先来了解一下索引的类别。
从逻辑上讲,MySQL分为以下几类:
索引使用
索引可以在建表的时候创建,也可以单独创建。让我们单独创建它。我们在 cxuan004 上创建前缀索引
我们用explain来分析,可以看到cxuan004使用了索引
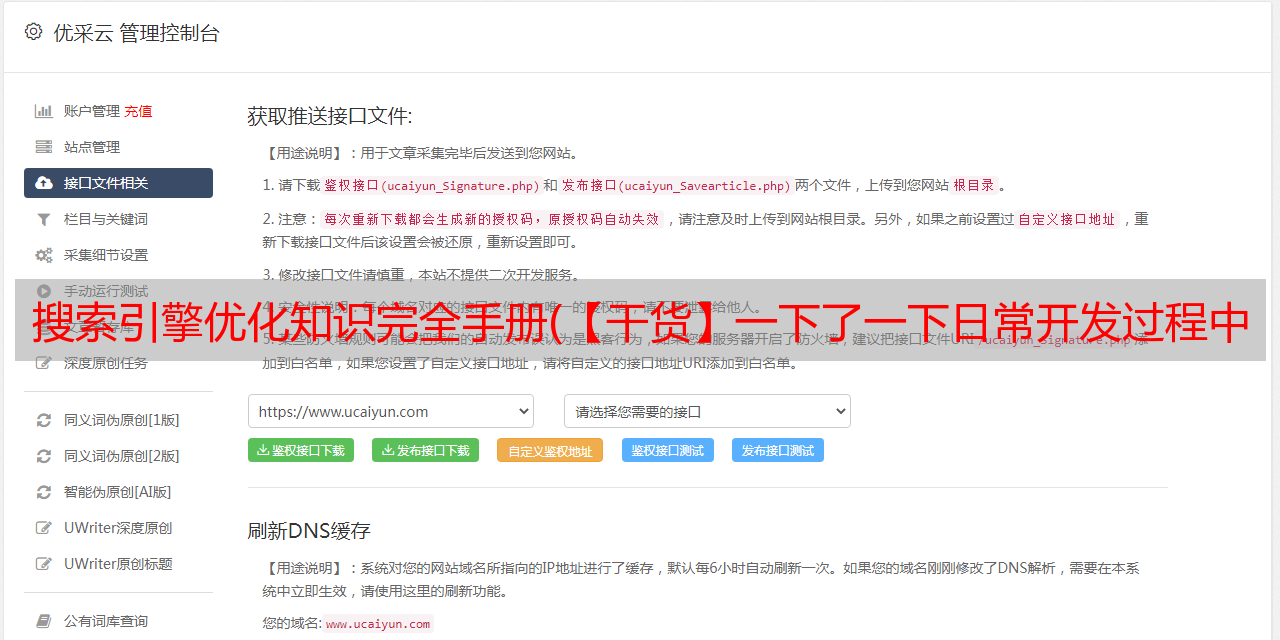
如果不想使用索引,可以删除索引,索引删除语法为
索引使用规则
我们在cxuan005上创建一个基于id和hash的复合索引如下
create index id_hash_index on cxuan005(id,hash);
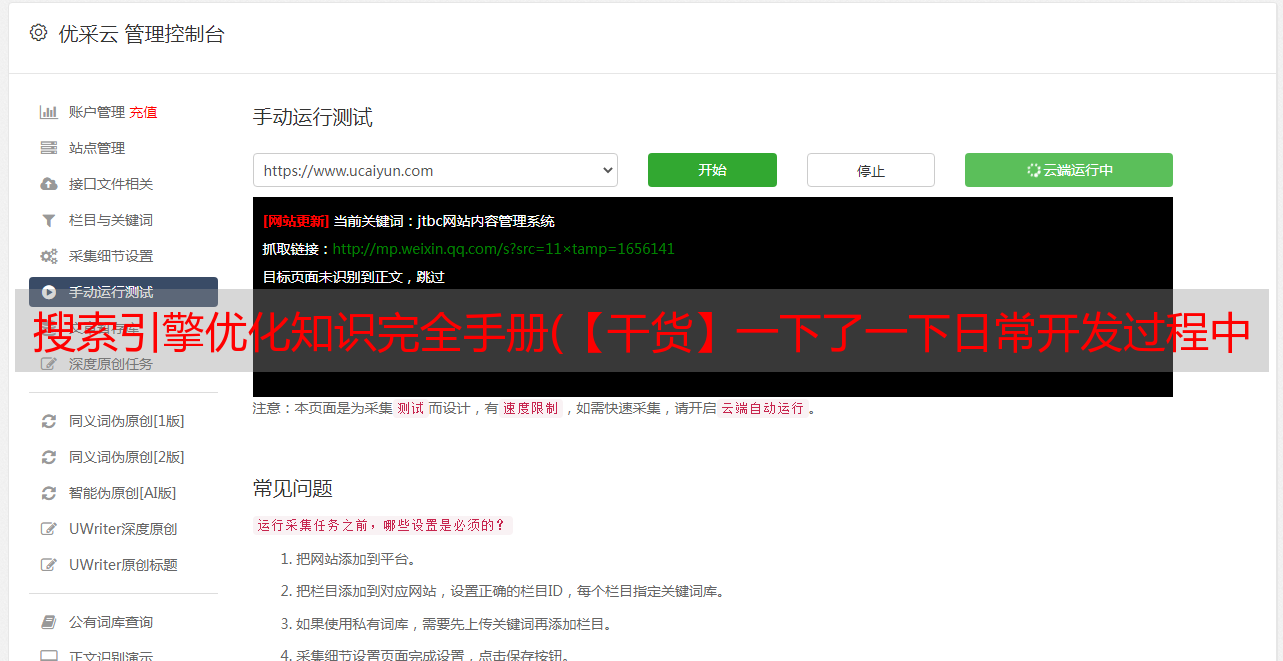
然后根据id分析执行计划
explain select * from cxuan005 where id = '333';
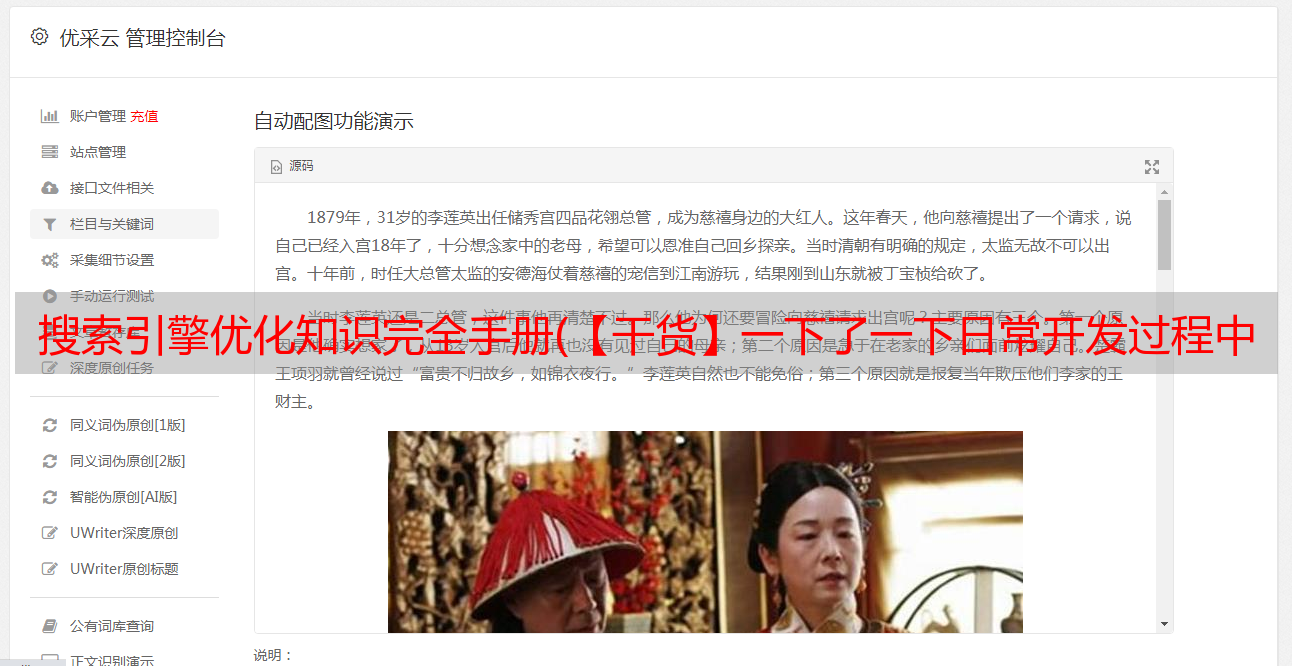
可以发现,即使where条件中没有使用复合索引(Id,hash),仍然可以使用索引,这就是索引的前缀特性。但是如果只通过hash查询,就不会用到索引。
explain select * from cxuan005 where hash='8fd1f12575f6b39ee7c6d704eb54b353';
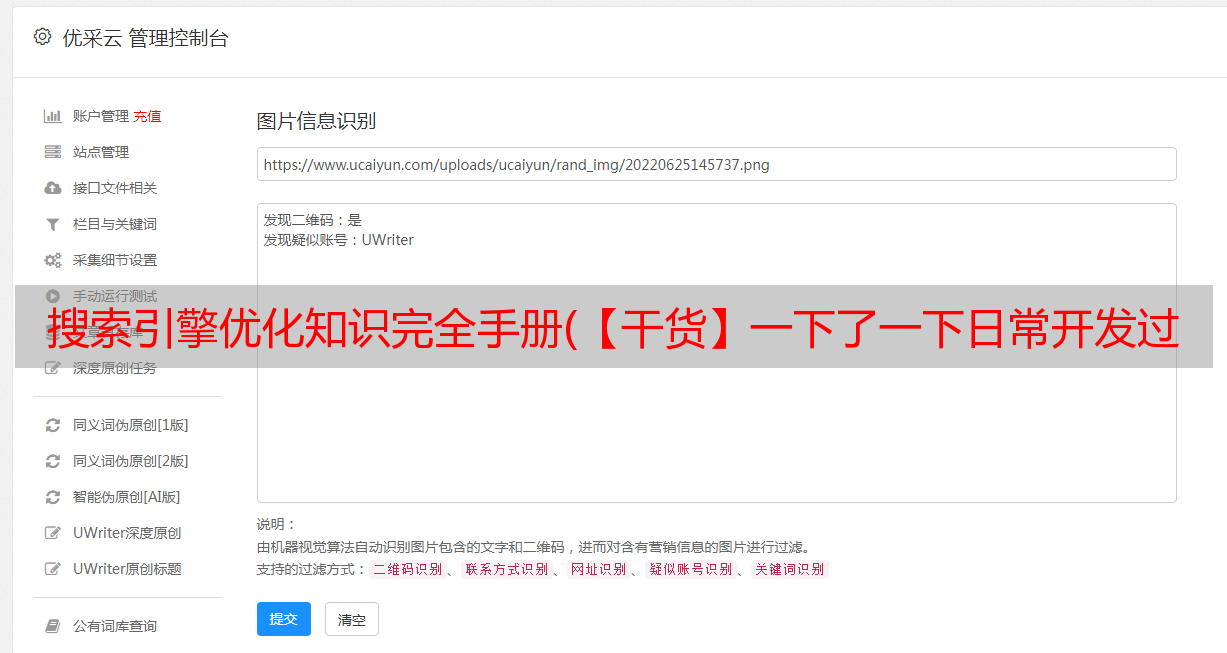
如果 where 条件使用 like 查询,并且 % 不是第一个字符,则可以使用索引。
对于复合索引,只能使用 id 进行like 查询,因为无论怎么查询,hash 列都不会经过索引。
explain select * from cxuan005 where id like '%1';
如您所见,如果第一个字符是 %,则不使用索引。
explain select * from cxuan005 where id like '1%';
如果使用 % 符号,则会触发索引。
如果列名是索引,则对列名的 NULL 查询将触发索引。
explain select * from cxuan005 where id is null;
也有索引存在但 MySQL 不使用它的情况。
还有很多设置了索引但索引不生效的场景。这就需要小伙伴们在工作中不断总结和改进。但是,我上面总结的索引失败的场景可以涵盖大部分索引失败的场景。
查看索引使用情况
MySQL索引在使用过程中,有一个Handler_read_key值,表示索引值读取一行的次数。如果 Handler_read_key 的值比较低,说明增加索引获得的性能提升不是很理想,索引的使用频率可能不高。
另一个值是 Handler_read_rnd_next。较高的值意味着查询运行效率不高,应建立索引进行救援。该值的含义是读取数据文件下一行的请求数。如果正在进行大量的表扫描并且Handler_read_rnd_next的值很高,则表示表索引不正确或写入的查询没有使用索引。
MySQL 分析表、检查表和优化表
对于大多数开发者来说,他们更倾向于解决简单 SQL 的优化,而复杂 SQL 的优化则留给了公司的 DBA。
下面从普通程序员的角度来和大家聊聊几个简单的优化方法。
MySQL分析表
分析表用于分析和存储表的关键字分布,分析结果可以使系统获得准确的统计信息,从而SQL生成正确的执行计划。如果习惯了觉得实际执行计划不符合预期,可以执行分析表来解决问题。分析表的语法如下
analyze table cxuan005;
分析结果涉及的字段属性如下
表:表示表的名称;
op:表示要执行的操作,analyze表示分析操作,check表示检查搜索,optimize表示优化操作;
msg_type:表示信息的类型,显示的值通常是status、warning、error和information中的一种;
Msg_text:显示信息。
定期分析表格可以提高性能,应该成为您日常工作的一部分。因为通过更新其索引信息来分析表,所以可以提高数据库性能。
MySQL 清单
数据库经常会遇到错误,例如将数据写入磁盘时出错,或者索引没有同步更新,或者数据库在没有关闭 MySQL 的情况下停止。在这些情况下,数据可能是错误的:表的密钥文件不正确:' '。尝试修复它。此时,我们可以使用Check Table语句来检查表及其对应的索引。
check table cxuan005;
清单的主要目的是检查一个或多个表是否有错误。Check Table 适用于 MyISAM 和 InnoDB 表。Check Table 还可以检查视图是否有错误。
MySQL 优化表
MySQL 优化表适用于删除大量表数据,或者修改大量命令,包括 VARCHAR、BLOB 或 TEXT。MySQL优化表可以合并大量空间碎片,消除删除或更新带来的空间浪费。它的命令如下
optimize table cxuan005;
我的存储引擎是InnoDB引擎,但是从图中可以看出,InnoDB不支持使用optimize,推荐使用recreate+analyze进行优化。优化命令仅适用于 MyISAM 和 BDB 表。
常见的 SQL 优化
前面我们介绍了使用索引来优化MySQL,那么我们应该如何优化SQL的各种语法和语法呢?接下来从SQL命令的角度讲一波SQL优化。
导入的优化
对于MyISAM类型的表,可以通过以下方式导入大量数据
ALTER TABLE tblname DISABLE KEYS;
loading the data
ALTER TABLE tblname ENABLE KEYS;
这两个命令用于打开或关闭 MyISAM 表上非唯一索引的更新。在将大量数据导入非空MyISAM表时,通过设置这两条命令,可以提高导入效率。对于将大量数据导入一个空的MyISAM表,默认是先导入数据再创建索引,所以不需要设置。
但是对于 InnoDB 搜索引擎的表,这并不能提高导入效率。我们有以下方法来提高导入效率:
由于 InnoDB 类型的表是按主键顺序存储的,所以按照主键顺序排列导入的数据可以有效提高导入数据的效率。如果 InnoDB 表没有主键,系统会默认创建一个内部列作为主键,所以如果可以为表创建主键,就可以利用这个优势提高导入效率数据。导入数据前执行SET UNIQUE_CHECKS = 0关闭唯一性检查,导入后执行SETUNIQUE_CHECKS = 1恢复唯一性检查,可以提高导入效率。如果应用使用自动提交方式,建议在导入前执行SET AUTOCOMMIT = 0,关闭自动提交,导入后执行SET AUTOCOMMIT = 1,开启自动提交,这也可以提高导入的效率。插入优化
插入语句时,可以考虑以下几种方式进行优化
insert into test values(1,2),(1,3),(1,4)
优化分组依据
在使用分组排序的场景下,如果先进行Group By再进行Order By,可以指定order by null来禁止排序,因为order by null可以避免filesort,这往往比较耗时。如下
explain select id,sum(moneys) from sales2 group by id order by null;
订单优化
在执行计划中,经常会看到文件排序出现在Extra列中。Filesort 是一种文件排序。这种排序方法比较慢。我们认为这是一种不好的排序,需要优化。
优化的方法是使用索引。
我们在 cxuan005 上创建一个索引。
create index idx on cxuan005(id);
然后我们使用查询字段进行查询并按相同的顺序排序。
explain select id from cxuan005 where id > '111' order by id;
如您所见,在此查询中,使用了 Using 索引。这表明我们正在使用索引。
如果索引创建的顺序和order by不一致,会使用Using filesort。
explain select id from cxuan005 where id > '111' order by info;
MySQL 支持两种排序方式,filesort 和 index。使用索引意味着 MySQL 会扫描索引本身来完成排序。索引是有效的,文件排序是低效的。
只有满足以下条件时,order by才会使用索引
优化嵌套查询
嵌套查询是我们经常使用的一种查询方式。这种查询方式可以使用SELECT语句创建单个查询结果,然后在另一个查询语句中将该结果作为嵌套语句的查询范围。使用时,子查询可以将复杂的查询拆分成独立的部分,逻辑上更容易理解,也更容易维护和重用代码。
但是,在某些情况下,子查询的效率并不高,一般使用join来代替子查询。
使用嵌套查询的SQL语句进行解释分析如下
explain select c05.id from cxuan005 c05 where id not in (select id from cxuan003);
从explain的结果可以看出,主表的查询是index,子查询是index_subquery,两者的效率都不是很高。我们使用join来优化分析计划如下。
explain select c05.id from cxuan005 c05 left join cxuan003 c03 on c05.id = c03.id;
从explain分析结果可以看出,主表查询和子查询分别是index和ref,ref的执行效率比较高。一般类型效率从高到低依次为 System-->const-->eq_ref-->ref --> fulltext-->ref_or_null-->index_merge-->unique_subquery-->index_subquery-->range-- >索引-->全部。
计数优化
我们都使用计数太多。一般用于统计某列的结果集中的行数。当 MySQL 确认括号中的表达式不能为空时,实际上是在计算行数。
其实count还有另外一种统计方法:统计列值的个数。统计列值个数时,默认不统计NULL值。
我们犯的一个常见错误是在括号中指定一列,但想计算结果集中的行数。如果想知道结果集中的行数,最好使用count(*)。
限制分页优化
通常我们的系统会进行分页,一般情况下我们会使用limit加offset来实现。同时会添加order by语句进行排序。如果使用索引,效率一般不会有问题。如果不使用索引,MySQL 可能会进行大量的文件排序操作。
通常我们可能会遇到限制1000、50、丢弃1000条记录只取50条记录这样的情况,这个成本非常高,如果所有页面都以相同的频率访问,那么这样的查询需要访问一半的表平均数据。
要优化这种查询,要么限制分页数,要么优化大偏移量的性能。
在 SQL 中 IN 不应该收录太多的值
MySQL对IN做了相应的优化。MySQL 会将所有常量存储在一个数组中。如果有更多的值,消耗也会增加,例如
select name from dual where num in(4,5,6)
对于这样的 SQL 语句,如果可以使用 between,就不要再使用 in。
当只需要一个数据时
如果只需要一条数据,建议使用limit 1,这会使执行计划中的类型为const。
如果没有使用索引,尽量减少排序并使用union all而不是union
union 和 union all 的主要区别在于前者需要合并结果集,然后进行唯一的过滤操作,这会涉及到排序,增加大量的 CPU 操作,增加资源消耗和延迟。当然,union all 的前提是两个结果集没有重复数据。
where条件优化查询时,尽量指定查询的字段名
我们日常使用select查询的时候,尽量使用select字段名的方法,避免直接**select**,增加很多不必要的消耗(cpu、io、内存、网络带宽);查询效率比较低。

