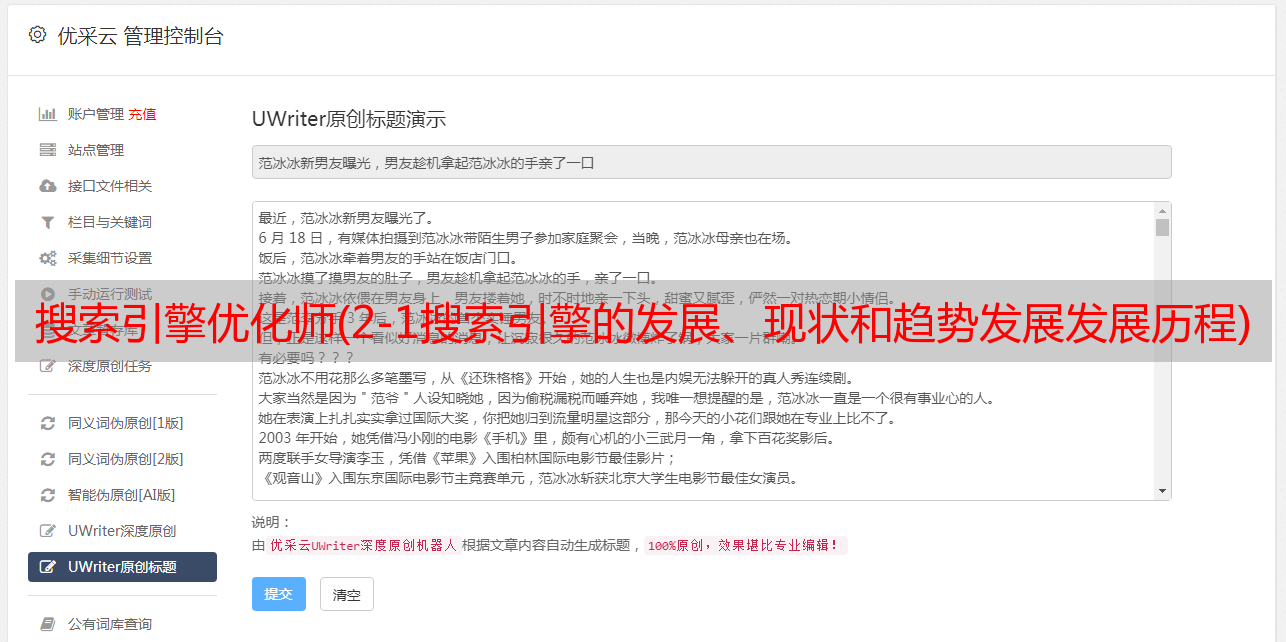
搜索引擎优化师(2-1搜索引擎的发展、现状和趋势发展发展历程)
优采云 发布时间: 2022-01-23 00:16搜索引擎优化师(2-1搜索引擎的发展、现状和趋势发展发展历程)
2-1 搜索引擎的发展、现状及趋势
发展路径:
第一代:品类时代,1994年4月,美国斯坦福大学的两名博士生、美籍华人杨洁渊和大卫·菲洛共同创立了雅虎!
第二代:文本检索时代,搜索引擎查询信息的方式是将用户输入的查询信息提交给服务器,服务器通过查询返回一些高度相关的信息给用户,如阿尔塔维斯塔;
第三代:综合分析时代,外链的形式和我们今天的网站基本一致。在那个时候,外链代表了一种推荐。每个 网站 的推荐链接数,以判断 网站 的受欢迎程度和重要性。然后搜索引擎结合网页内容的重要性和相似性来提高用户搜索信息的质量。这个模型的第一个用户是google,而且非常成功;
来源:谷歌和百度现在是一种搜索引擎。1990年,加拿大麦吉尔大学计算机学院师生开发了Archie。当时,在万维网出现之前,人们使用 FTP 来共享和交流资源。Archie 可以定期采集和分析 FTP 服务器上的文件名信息,并提供对每个 FTP 主机中文件的搜索。用户必须输入准确的文件名进行搜索,Archie 告诉用户哪个 FTP 服务器可以下载该文件。Archie采集的信息资源虽然不是网页(HTML文件),但其工作方式与搜索引擎相同:自动采集信息资源、建立索引、提供检索服务,因此被认为是搜索引擎的鼻祖;
2018年8月,谷歌全球市场份额为92.12%,位居榜首。百度排名第四,市场份额1.17%;
2018年8月,百度国内市场占有率为77.88%,位居榜首。360搜索第二,市场占有率8.18%;
第四代:以用户为中心的时代,当输入同一个查询请求关键词时,用户背后可能会有不同的查询需求。如果输入的是“apple”,你想找一个 iPhone 还是一个水果?即使是同一个用户搜索同一个关键词,由于时间和场合不同,返回的结果也不同。所有的主流搜索引擎都致力于解决同一个问题:如何从用户输入的一个短关键词中获取来判断用户真正的查询请求。移动互联网搜索的必然使命是提供精准的个人搜索;
未来想象:
未来的搜索引擎应该能够回答任何问题。使用搜索引擎时,用户不必考虑先搜索什么,然后再搜索什么。用户不必学习如何搜索,但应该像向好朋友提问一样。搜索应该更像是一种对话,更容易更自然,而不是固定的搜索方式。
结合人工智能(AI),人工智能可以处理复杂的任务,分析一系列用户习惯、用户画像、用户行为,并根据地点、时间、个人爱好、需求、瓶颈、以确保搜索结果匹配的相关性迅速增加。比如你想买房,它会根据你的经济状况、周边学校要求、娱乐需求、工作喜好等因素,带你到理想的房子,让你不用四处张望.
第五代:生命生态搜索时代,即万物互联的互联网+时代,搜索空间更广阔,搜索无处不在,比如*敏*感*词*小孩、老人,或者寻找迷路的人孩子,包括GPS定位精确到厘米,比如你去一个陌生的地方,找厕所,找警察,甚至有东西可能找你,比如煮饭的时候,电饭煲会打电话你等;
百度是全球最大的中文搜索引擎,于2000年1月在北京中关村成立。公司名称来自宋代“中立找他千百度”,而“熊掌”图标的创意则来自“猎手上路”的刺激,与李彦宏的“解析搜索技术”,从而构成了百度的搜索概念,也最终成为了百度的图标形象。百度于2001年10月22日正式发布百度搜索引擎,最初员工不足10人,2015年员工人数近5万人,现已成为中国搜索市场的领头羊;
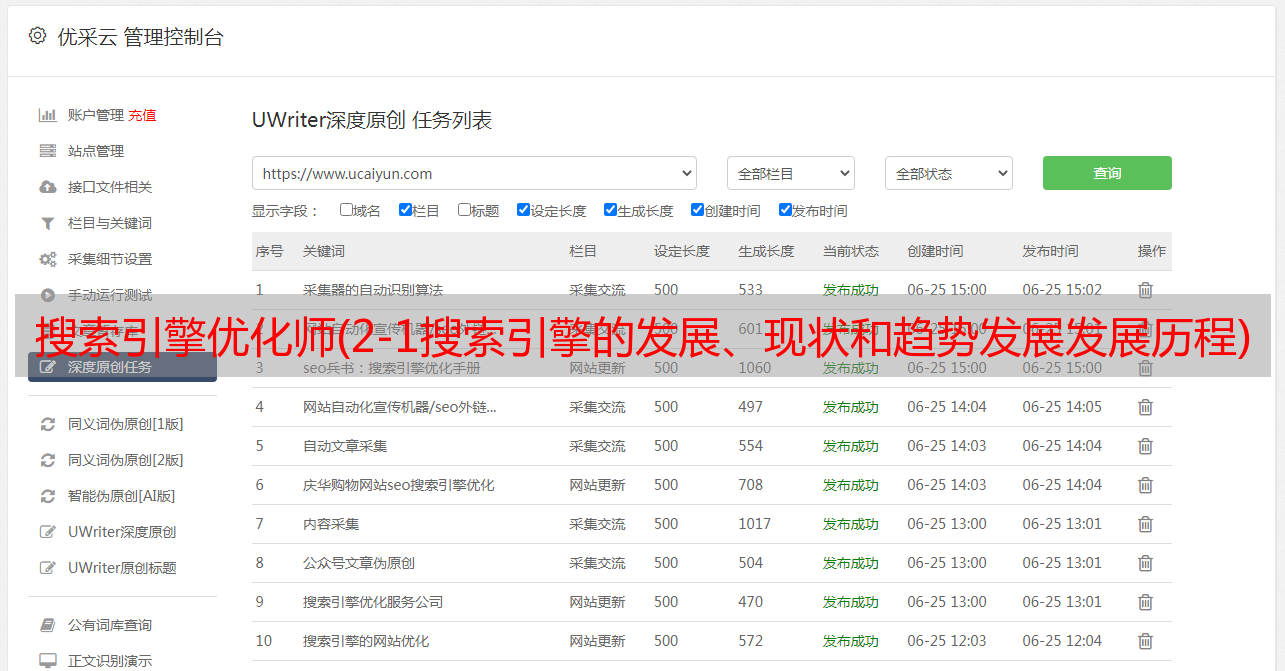
2-2 搜索引擎排名的原理和流程
搜索引擎从用户搜索到最终搜索结果展示所经历的步骤是(以百度为例):
爬,百度不知道你的网站,怎么让你排名?所以要让百度知道你,首先要通过爬取这一步;
过滤,过滤掉低质量的页面内容;
索引,只存储符合条件的页面;
处理,对搜索词进行处理,如中文专用分词处理,去除停用词,判断是否需要启动综合搜索,判断是否有拼写错误或错别字。
排名,向用户展示优质页面;
2-2-1 Spider的排名原理
蜘蛛:
l 搜索引擎发送的用于发现和抓取互联网上新网页的程序称为蜘蛛。它从一个已知的数据库开始,像普通用户的浏览器一样访问这些网页,并沿着网页中的链接访问更多的网页,这个过程称为爬取;l 蜘蛛对站点的遍历和爬取策略分为深度优先和广度优先两种。
根据爬取的目标和范围,可以分为
批量爬虫:明确爬取目标和范围,达到就停止;
增量爬虫:为了响应网页不断更新的状态,爬虫需要及时响应,一般商业引擎一般都是这种类型;
垂直爬虫:只针对特定领域的爬虫,根据主题进行过滤;
2-2-2 把握排名原则
爬取过程中百度官方蜘蛛攻略
1、爬取友好性,同一站点在一段时间内的爬取频率和爬取流量不同,即错开正常用户访问高峰并不断调整,避免被抓到影响过大1、@网站的正常用户访问行为。
2、常用的fetch返回码,如503、404、403、301等;
3、对各种url重定向的识别,如http 30x、meta刷新重定向和js重定向,Canonical标签也可以认为是变相的重定向;
4、抢优先分配,如深度优先遍历策略、广度优先遍历策略、pr优先策略、反链策略、大站点优先策略等;
5、重复url过滤,包括url规范化识别,例如一个url收录大量无效参数但实际上是同一个页面;
6、暗网数据的获取,搜索引擎暂时无法抓取的数据,比如存在网络数据库,或者由于网络环境,网站本身不符合规范,被爬取的孤岛等问题,如百度的“阿拉丁”程序;
7、爬虫防作弊,爬虫过程中经常会遇到所谓的爬虫黑洞或面临大量低质量页面,这就需要在爬虫系统中设计一套完整的爬虫防作弊系统。. 如分析url特征、分析页面大小和内容、分析爬取规模对应的站点规模等;
蜘蛛感兴趣的页面有 3 类:
1.从未抓取过新页面。
2.已爬取但内容已更改的页面。
3.已抓取但现已删除的页面。
什么蜘蛛不能/不喜欢爬行:
1.被机器人屏蔽的页面;
2.flash 中的图片、视频和内容;
3.js、iframe框架、表格嵌套;
4.蜘蛛被服务器拦截;
5.岛屿页面(没有任何导入链接);
6.登录后才能获取的内容;
2-2-3 排序原理过滤
四种近似的重复页面类型:
l1.完全重复页面:内容和布局格式没有区别;
l2.重复页面:内容相同,但布局格式不同;
l3.布局重复页面:部分重要内容相同,布局格式相同;
l4.部分重复页面重要内容相同,但布局格式不同;
低质量的内容页面:
Ø1.多个URL地址指向同一个网页和镜像站点,如带www和不带www解析为一个网站;
Ø2.网页内容重复或几乎重复,如采集的内容,文字错误或垃圾邮件;
Ø 没有丰富的内容,如纯图片页面或页面内容搜索引擎无法识别;
过滤 - 如何处理重复文档:
ü1.将删除低质量内容
ü2.高质量的重复文档优先分组展示(高重复表示欢迎)
2-2-4 排名原则索引
l1.用户在查询过程中得到的结果并不及时,而是排列在搜索引擎的缓存区。在处理用户查询请求时,根据词库对请求进行切分,将词库划分为词。对于每一个关键词,都会预先计算出其对应的URL排名,并保存在索引数据库中。这就是倒排索引,即以文档的关键词为索引,以文档为索引目标(与普通书籍类似,索引为关键词,书籍的页码为指数目标);
l 如果页面被分割成单词p={p1, p2, p3, ..., pn},会在索引库中体现在右图上(仅供理解,并非真实)
l 索引更新策略:通过完整的rebuild策略、re-merge策略、原位更新策略、混合策略等持续更新索引;
处理:
l1.分析用户的搜索意图,看它是导航性的、信息性的还是基于事物的,从而提供准确的搜索结果,假设用户在搜索时可能无法想到合适的搜索词,或者关键词输入错误,则需要帮助用户明确搜索意图(相关搜索、查询更正)。
l2.提取关键词,代码去噪只留下文本,去除公共区域等非文本关键词,去除“de”和“zai”等停用词,然后通过分词系统 将这篇文章分成一个分词列表并存入数据库,并与其URL一一对应;
l3.内容检索,通过布尔模型、向量空间模型、概率模型、语言模型、机器学习排名等检索模型计算网页和查询的相关性;
l4.链接分析,通过分析计算出的分数来评估网页的重要性。
补充知识:
1.重要信息分析,利用网页代码(如H标签、强标签)、关键词密度、内链锚文本等分析本网页最重要的词组;Ø网页重要性分析,通过指向该网页的外部链接的锚文本传递的权重值确定该网页的权重值,并结合“重要信息分析”建立每一个关键词的内容关键词设置此网页的 p。可用的排名因素。
2-2-6 排序原则查询/排序
查询服务:
l1.根据查询方法用关键词进行分词。首先将用户搜索到的关键词分成一个序列关键词,暂时用q表示,然后将用户搜索到的关键词q分成q={q1,q2 , q3 , ..., qn}。然后根据用户的查询方式,比如所有的词是连在一起的,还是中间有空格等等,根据q中关键词的不同词性,将每个词中的所需的查询词在查询结果的显示上确定。占有的重要性。
l2.搜索结果排序。我们有搜索词集q,q中每个关键词对应的URL排序——索引库,也根据用户的查询方式和部分计算出每个关键词在查询结果中的展示的语音如果重要,那么只需要一点综合排序算法,搜索结果就出来了。
l3.向用户展示上述搜索结果和文档摘要;
通过常见现象猜测百度算法:
1. 搜索时,经常发现百度显示在用户的搜索词周围。有时如果单词较长,或者稍后翻几页,您会看到一些结果,因为目标页面本身并未完全收录搜索。词,百度页面中的红色词只是搜索词的一部分。可以理解为,在搜索词没有完全收录的情况下,百度会优先考虑分词结果中被百度认为比较重要的词吗?Ø 有时搜索词在页面上出现多次,但在百度搜索结果页面中只显示了一部分,而且通常是连续的。百度会优先显示它认为对搜索词最重要的页面部分,这可以理解吗??
2-3 百度蜘蛛3.0
百度蜘蛛3.0对seo的影响:
l1.爬取和建库比较快,所以优化周期要缩短,包括更新、微调、改版等。之前改版需要3个月,现在可能1个月调整。
l2.死链接及时处理。优化时,应及时发现死链接(包括错误页面、被黑页面、无内容页面等)并提交百度站长工具及时删除,防止死链接右下角。
l3.关注优质原创内容,优先保护和排名,主动更新和提交优质原创内容。
l4.链接的主动提交有以下四种方式,可以根据自己的情况选择;
2016年6月,百度官方宣布Spider从2.0升级为3.0。本次升级是将当前离线的、全规模的基于计算的系统转变为全规模的实时、增量计算系统。实时调度系统,万亿级数据实时读写,可收录90%的网页,速度提升80%!
这说明搜索更注重时效性。比如主动提交数据的平均爬取时间比爬虫发现时间早4个小时,而且提交的收录也很快,所以页面更新加快了,好的工作不一定马上就好。但是,一旦发现性能不佳,更新会更及时。毕竟要向用户展示优质的内容,所以网站千万不能掉以轻心,因为一旦出现问题,就很难恢复;
2-4 常用搜索引擎的高级命令
l双引号(英文):搜索词完全匹配,如搜索[ "software" ],结果必须收录software;
l 减号:不包括减号后面的词,前后不带空格,如【软件-常州】;
lInurl:用于搜索查询词出现在url中的页面,如[inurl:dingjianseo];
intitle:搜索页面的标题收录关键词,如[intitle:搜索引擎];
allinurl:页面url收录多组关键词,如[allinurl:dingjianseo zuoseoyh];
allintitle:页面标题收录多组关键词,如[allintitle:你好常州];
文件类型:搜索特定的文件格式。例如,[filetype:pdf seo]是一个收录seo的pdf文件;
Site/Domain:搜索域名的大概收录和外部链接,如site:;

