网站文章一键采集(本文采集指定节点和“如何导出采集内容”的介绍)
优采云 发布时间: 2022-01-22 10:16网站文章一键采集(本文采集指定节点和“如何导出采集内容”的介绍)
前言:本文为《常用文章与分页的采集方法》第三篇。《如何导出采集内容》详细介绍。为了与前文保持一致,本文将继续沿用前文章节标记。
继续第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图29),
图 29 - 采集 指定节点
采集 per page:这个是设置每页需要的采集个数,采集的间隔可以根据网站是否有反刷新来设置功能。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一种是“Monitoring采集模式(检测当前或所有节点是否有新内容)”,选择后系统只会采集指定节点中更新的内容;第二个是“重新下载所有内容”,选择后系统会采集指定节点中的所有内容;第三个是“下载torrent网站的未下载内容”,选择后系统只会采集指定节点中的未下载内容,包括之前未下载和更新的内容。
设置完成并确认后,点击“开始采集网页”或“查看Torrent URL”。此时,如果点击“查看*敏*感*词*URL”,会看到列表为空,这是因为新创建的采集节点从来都不是采集,如图(图3< @0) 显示,
图 30 - 查看节点的*敏*感*词* URL
点击“开始采集网页”后,系统会启动采集节点中设置的URL,并出现相关提示,如图(图31),
图31-采集过程中提示信息
采集结束后,再次点击“查看Torrent URL”或点击页面右上角的“查看已下载”,可以看到已经采集的URL信息,如(图3< @2) 显示,
图 32 - 查看节点的*敏*感*词* URL
采集成功后,可以根据实际需要点击页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图33),
图 33 - 采集 内容导出
“默认导出列”:设置采集中的内容将被导入到的列
“批处理采集选项”:如果采集规则中已经指定了列ID,则可以使用该功能。如果指定的列 ID 为 0,系统会将 采集 的内容导入到“默认导出列”选择的列中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批导入”:设置每批导入的项目数,不宜过大。
“附加选项”:这里有多种选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望内容为采集直接生成HTML,选择“完成后自动生成导入”内容HTML”;如果希望系统在采集列表页时自动识别标题名称,可以选择“使用列表索引的标题”,一般不推荐。
“随机推荐”:填写一个代表文档数量的数字。推荐的文档在填写的文档数量中随机出现。如果填写“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的文件导入到选中的栏目中,如图(图34),
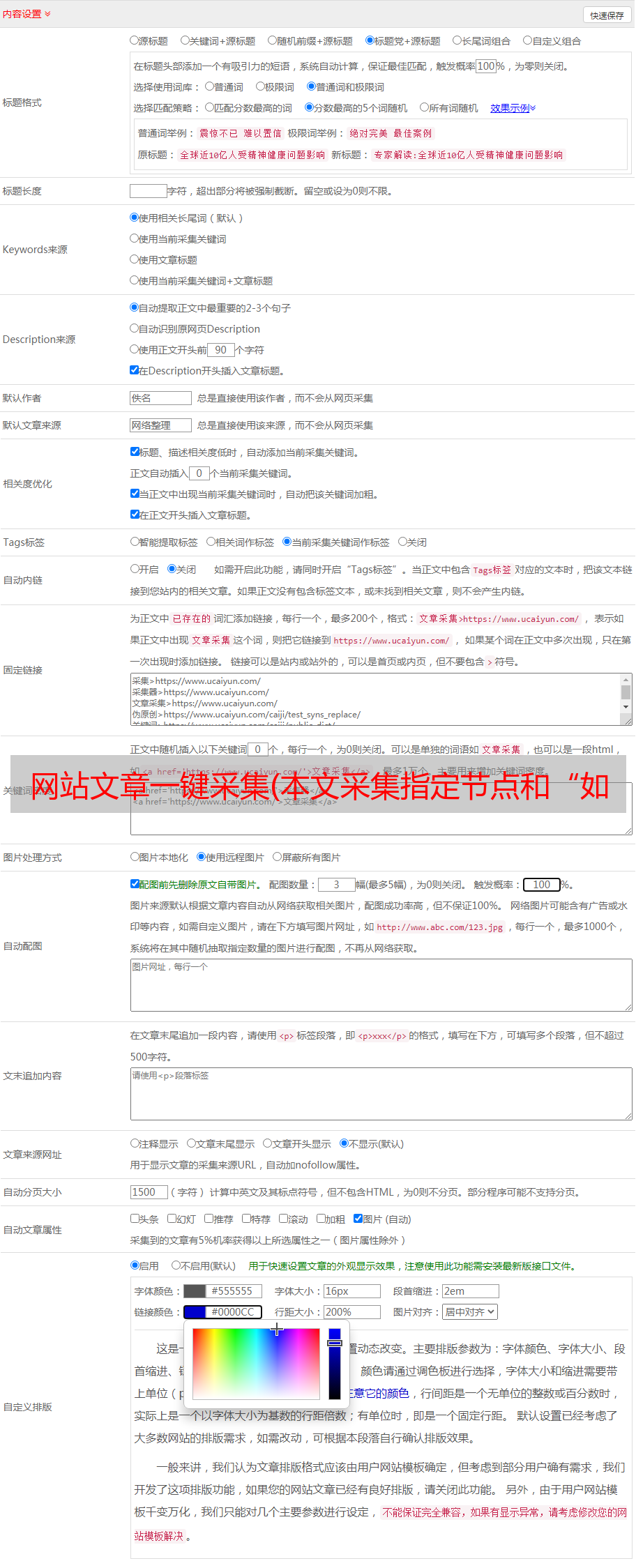
图 34 - 采集 设置后的内容导出页面
同时系统会提示导出过程,如图35),
图 35-采集内容导出提示信息
导出采集的内容后,提示“完成所有栏目列表的更新”,点击“浏览栏目”,可以进入网站的相关页面查看文章@的列表> 采集 去的地方。及其具体内容。也可以在后台管理界面主菜单点击“Core”,然后点击“普通文章”进入“文档列表”页面,查看文章采集的列表@> 到 ,如图(图36),
图 36 - 文档列表
在文档列表中,点击“用最简单的网络学习IP和ARP协议”的预览按钮,打开文章内容页面,找到页面的换页部分,如图(图37) ,
图 37 - 分页
可以看出,收录分页文章的内容已经成功采集到达。
总之,本文详细介绍了如何采集普通的文章分页类型页面,并简要介绍了过滤规则。对于采集比较复杂的普通文章类型页面和过滤规则的使用,以后会介绍文章。
本文的 采集 规则:
{dede:listconfig}
{dede:noteinfo notename="采集Test(二)" channelid="1" macthtype="string"

