云端 自动 采集(一个监控SAAS平台,只需要简单配置,释放数据价值 )
优采云 发布时间: 2022-01-21 17:11云端 自动 采集(一个监控SAAS平台,只需要简单配置,释放数据价值
)
DataFlux是上海住云自主研发的一套统一的大数据分析平台,通过对任意来源、任意类型、任意规模的实时数据进行监测、分析和处理,释放数据价值。
DataFlux 包括五个功能模块:
- 数据包 采集器
- Dataway 数据网关
- DataFlux Studio 实时数据洞察平台
- DataFlux Admin Console 管理后台
- DataFlux.f(x) 实时数据处理开发平台
为企业提供全场景数据洞察分析能力,具有实时性、灵活性、易扩展性、易部署性。
ntpq命令可以用来处理各个时间之间的同步和转换,非常强大。今天给大家分享一个监控SAAS平台,通过简单的配置即可实现站点和业务监控——使用DataFlux采集NTPQ性能指标并分析展示。
安装 DataKit
PS:以Linux系统为例
第一步:执行安装命令
DataKit 安装命令:
DK_FTDATAWAY=[你的 DataWay 网关地址] bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
在安装命令中添加DataWay网关地址,然后将安装命令复制到主机执行。
例如:如果DataWay网关的IP地址为1.2.3.4,端口为9528(9528为默认端口),则网关地址为
DK_FTDATAWAY=http://1.2.3.4:9528/v1/write/metrics bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
安装完成后DataKit会默认自动运行,并会在终端提示DataKit状态管理命令
NTPQ 监控指标采集
采集 ntpq 索引报告给 DataFlux
前提
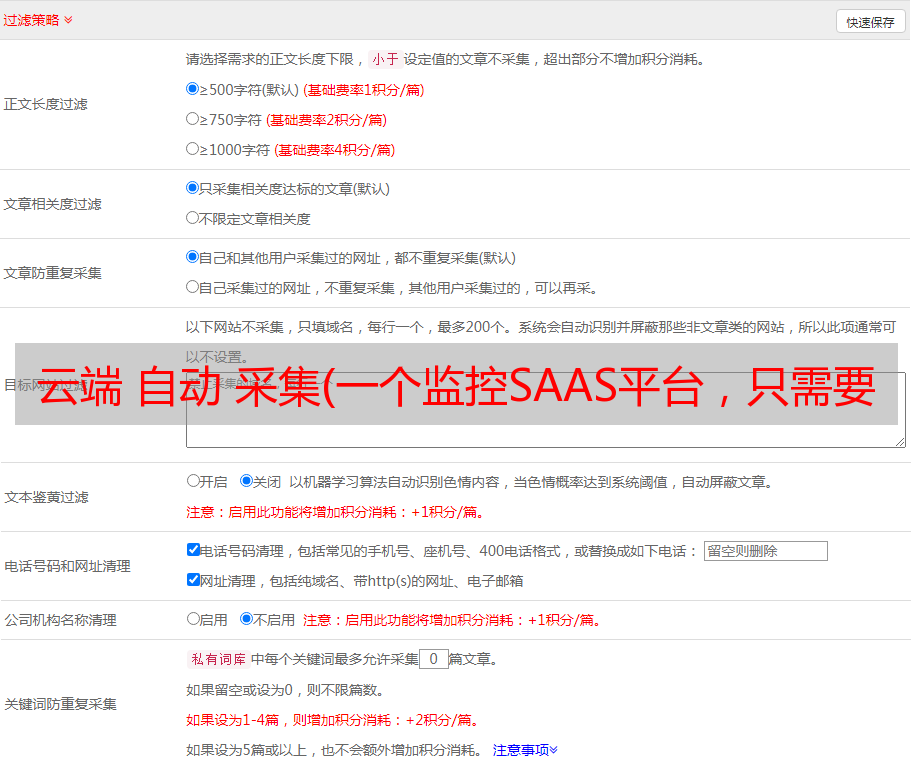
配置
打开DataKit采集源码配置文件夹(默认路径是DataKit安装目录的conf.d文件夹),找到ntpq文件夹,打开里面的ntpq.conf。
设置:
[[inputs.jolokia2_agent]]
name_prefix = "kafka_"
urls = ["http://localhost:8080/jolokia"]
[[inputs.jolokia2_agent.metric]]
name = "controller"
mbean = "kafka.controller:name=*,type=*"
field_prefix = "
."[[inputs.jolokia2_agent.metric]]
name = "replica_manager"
mbean = "kafka.server:name=*,type=ReplicaManager"
field_prefix = "
."[[inputs.jolokia2_agent.metric]]
name = "purgatory"
mbean = "kafka.server:delayedOperation=*,name=*,type=DelayedOperationPurgatory"
field_prefix = "
."field_name = "
云端 自动 采集(一个监控SAAS平台,只需要简单配置,释放数据价值 )
优采云 发布时间: 2022-01-21 17:11云端 自动 采集(一个监控SAAS平台,只需要简单配置,释放数据价值
)
DataFlux是上海住云自主研发的一套统一的大数据分析平台,通过对任意来源、任意类型、任意规模的实时数据进行监测、分析和处理,释放数据价值。
DataFlux 包括五个功能模块:
- 数据包 采集器
- Dataway 数据网关
- DataFlux Studio 实时数据洞察平台
- DataFlux Admin Console 管理后台
- DataFlux.f(x) 实时数据处理开发平台
为企业提供全场景数据洞察分析能力,具有实时性、灵活性、易扩展性、易部署性。
ntpq命令可以用来处理各个时间之间的同步和转换,非常强大。今天给大家分享一个监控SAAS平台,通过简单的配置即可实现站点和业务监控——使用DataFlux采集NTPQ性能指标并分析展示。
安装 DataKit
PS:以Linux系统为例
第一步:执行安装命令
DataKit 安装命令:
DK_FTDATAWAY=[你的 DataWay 网关地址] bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
在安装命令中添加DataWay网关地址,然后将安装命令复制到主机执行。
例如:如果DataWay网关的IP地址为1.2.3.4,端口为9528(9528为默认端口),则网关地址为
DK_FTDATAWAY=http://1.2.3.4:9528/v1/write/metrics bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
安装完成后DataKit会默认自动运行,并会在终端提示DataKit状态管理命令
NTPQ 监控指标采集
采集 ntpq 索引报告给 DataFlux
前提
配置
打开DataKit采集源码配置文件夹(默认路径是DataKit安装目录的conf.d文件夹),找到ntpq文件夹,打开里面的ntpq.conf。
设置:
[[inputs.jolokia2_agent]]
name_prefix = "kafka_"
urls = ["http://localhost:8080/jolokia"]
[[inputs.jolokia2_agent.metric]]
name = "controller"
mbean = "kafka.controller:name=*,type=*"
field_prefix = "$1."
[[inputs.jolokia2_agent.metric]]
name = "replica_manager"
mbean = "kafka.server:name=*,type=ReplicaManager"
field_prefix = "$1."
[[inputs.jolokia2_agent.metric]]
name = "purgatory"
mbean = "kafka.server:delayedOperation=*,name=*,type=DelayedOperationPurgatory"
field_prefix = "$1."
field_name = "$2"
[[inputs.jolokia2_agent.metric]]
name = "client"
mbean = "kafka.server:client-id=*,type=*"
tag_keys = ["client-id", "type"]
[[inputs.jolokia2_agent.metric]]
name = "request"
mbean = "kafka.network:name=*,request=*,type=RequestMetrics"
field_prefix = "$1."
tag_keys = ["request"]
[[inputs.jolokia2_agent.metric]]
name = "topics"
mbean = "kafka.server:name=*,type=BrokerTopicMetrics"
field_prefix = "$1."
[[inputs.jolokia2_agent.metric]]
name = "topic"
mbean = "kafka.server:name=*,topic=*,type=BrokerTopicMetrics"
field_prefix = "$1."
tag_keys = ["topic"]
[[inputs.jolokia2_agent.metric]]
name = "partition"
mbean = "kafka.log:name=*,partition=*,topic=*,type=Log"
field_name = "$1"
tag_keys = ["topic", "partition"]
[[inputs.jolokia2_agent.metric]]
name = "partition"
mbean = "kafka.cluster:name=UnderReplicated,partition=*,topic=*,type=Partition"
field_name = "UnderReplicatedPartitions"
tag_keys = ["topic", "partition"]
配置好后重启DataKit生效
采集指标
验证数据报告
完成数据采集操作后,我们需要验证数据采集是否成功并上报给DataWay,以便日后可以正常分析和展示数据。
操作步骤:登录DataFlux-数据管理-指标浏览-验证数据采集是否成功
DataFlux 的数据洞察力
根据获得的指标进行数据洞察设计,如:
NTPQ 性能监控视图
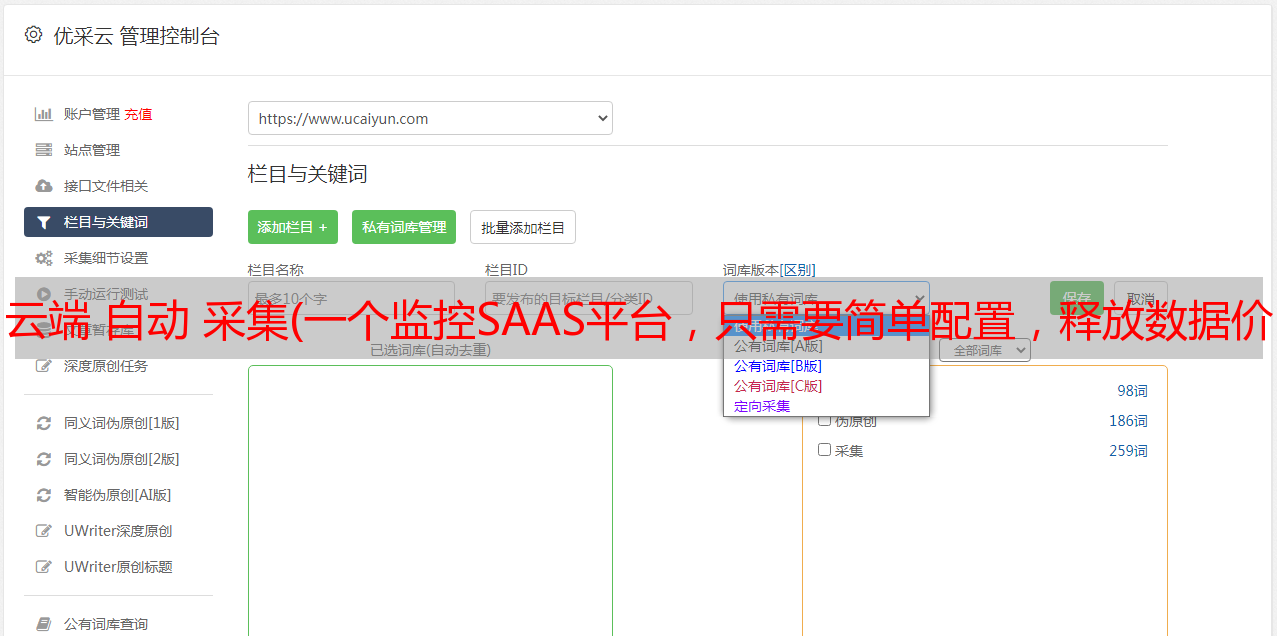
基于自研DataKit数据(采集器),DataFlux现在可以对接200多种数据协议,包括:云数据采集、应用数据采集、日志数据采集,时序数据上报和常用数据库的数据聚合,帮助企业实现最便捷的IT统一监控。
0 个评论
官方客服QQ群


在
线
客
服
[[inputs.jolokia2_agent.metric]]
name = "client"
mbean = "kafka.server:client-id=*,type=*"
tag_keys = ["client-id", "type"]
[[inputs.jolokia2_agent.metric]]
name = "request"
mbean = "kafka.network:name=*,request=*,type=RequestMetrics"
field_prefix = "
."tag_keys = ["request"]
[[inputs.jolokia2_agent.metric]]
name = "topics"
mbean = "kafka.server:name=*,type=BrokerTopicMetrics"
field_prefix = "
."[[inputs.jolokia2_agent.metric]]
name = "topic"
mbean = "kafka.server:name=*,topic=*,type=BrokerTopicMetrics"
field_prefix = "
."tag_keys = ["topic"]
[[inputs.jolokia2_agent.metric]]
name = "partition"
mbean = "kafka.log:name=*,partition=*,topic=*,type=Log"
field_name = "
"tag_keys = ["topic", "partition"]
[[inputs.jolokia2_agent.metric]]
name = "partition"
mbean = "kafka.cluster:name=UnderReplicated,partition=*,topic=*,type=Partition"
field_name = "UnderReplicatedPartitions"
tag_keys = ["topic", "partition"]
配置好后重启DataKit生效
采集指标
验证数据报告
完成数据采集操作后,我们需要验证数据采集是否成功并上报给DataWay,以便日后可以正常分析和展示数据。
操作步骤:登录DataFlux-数据管理-指标浏览-验证数据采集是否成功
DataFlux 的数据洞察力
根据获得的指标进行数据洞察设计,如:
NTPQ 性能监控视图
基于自研DataKit数据(采集器),DataFlux现在可以对接200多种数据协议,包括:云数据采集、应用数据采集、日志数据采集,时序数据上报和常用数据库的数据聚合,帮助企业实现最便捷的IT统一监控。