js 爬虫抓取网页数据(web自动化终极爬虫:百度音乐(静态网页)分析步骤)
优采云 发布时间: 2022-01-19 17:12js 爬虫抓取网页数据(web自动化终极爬虫:百度音乐(静态网页)分析步骤)
介绍:
最近写了几个简单的爬虫,踩了几个深坑。在这里总结一下,给大家写爬虫时的一些思路。该爬虫的内容包括:静态页面的爬取。动态页面的抓取。网络自动化的终极爬虫。
分析:
数据获取(主要通过爬虫)
数据存储(python excel存储)
数据采集实践:百度音乐(静态网页)
分析步骤
1.打开百度音乐:
2.打开浏览器调试模式F12,选择Network+all模式
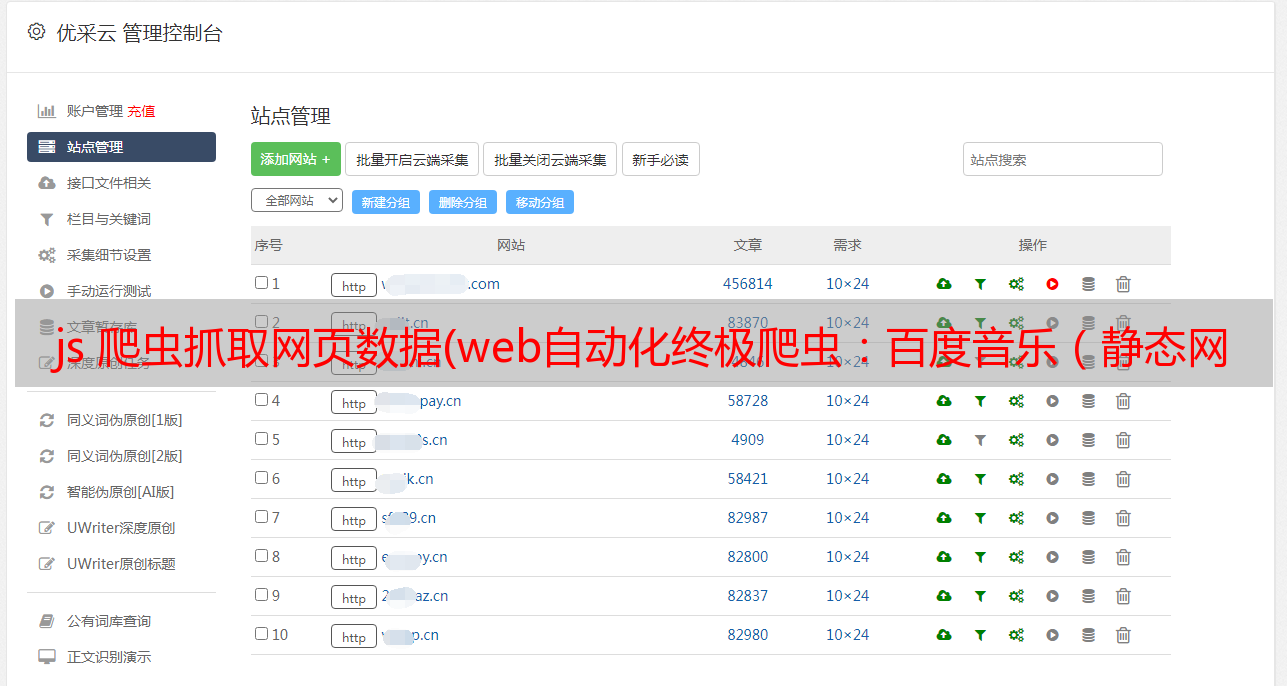
3.在搜索框搜索歌曲(beat it),查看控制台
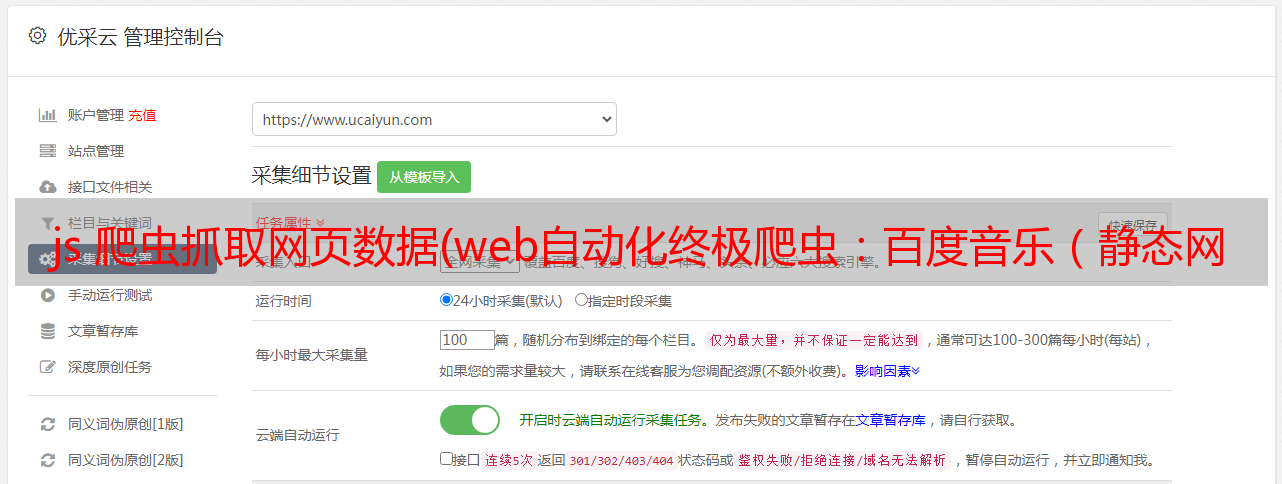
4、通过以上分析:获取有效信息:
5、通过有效信息设计爬虫,获取数据
代码
1.View提供了访问参数url并返回结果的方法
def view(url):
'''
:param url: 待爬取的url链接
:return:
'''
# 从url中获取host
protocol, s1 = urllib.splittype(url)
host, s2 = urllib.splithost(s1)
# 伪装浏览器,避免被kill
headers = {
'Host': host,
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
}
# 代理
proxies = {
"http": "dev-proxy.oa.com:8080",
"https": "dev-proxy.oa.com:8080",
}
# 利用requests封装的get方法请求url,并添加请求头和代理,获取并返回请求结果。并进行异常处理
try:
res = requests.get(url, headers=headers, proxies=proxies)
res.encoding = 'utf-8'
if res.status_code == 200:
# 请求成功
# 获取网页内容,并返回
content = res.text
return content
else:
return None
except requests.RequestException as e:
# 异常处理
print(e)
return None
2 .search_baidu_song 提供参数song_name的歌曲搜索并获取搜索结果
def search_baidu_song(song_name):
'''
获取百度音乐搜索歌曲结果
:param song_name: 待搜索歌曲名
:return: 搜索结果
'''
def analyse():
'''
静态网页分析,利用BeautifulSoup,轻松获取想要的数据。需要对html有了解。
:return:
'''
# 初始化BeautifulSoup对象,并指定解析器为 lxml。还有其他的解析器:html.parser、html5lib等
# 详细教程可访问:http://cuiqingcai.com/1319.html《Python爬虫利器二之Beautiful Soup的用法》
html = BeautifulSoup(content, "lxml")
# beautifulsoupzui常用方法之一: find_all( name , attrs , recursive , text , **kwargs )
# find_all() 方法搜索当前tag的所有tag子节点, 并判断是否符合过滤器的条件
# tag标签名为'div'的并且标签类名为class_参数(可为 str、 list、 tuple),
search_result_divs = html.find_all('div', class_=['song-item clearfix ', 'song-item clearfix yyr-song'])
for div in search_result_divs:
# find() 方法搜索当前tag的所有tag子节点, 并返回符合过滤器的条件的第一个结点对象
song_name_str = div.find('span', class_='song-title')
singer = div.find('span', class_='singer')
album = div.find('span', class_='album-title')
# 此部分需要对html页面进行分析,一层层剥开有用数据并提取出来
if song_name_str:
# 获取结点对象内容,并清洗
song_name_str = song_name.text.strip()
else:
song_name_str = ''
if singer:
singer = singer.text.strip()
else:
singer = ''
if album:
album = album.find('a')
if album:
# 获取标签属性值
# 方法二:属性值 = album['属性名']
album = album.attrs.get('title')
if album and album != '':
album = album.strip()
else:
album = ''
else:
album = ''
# print song_name + " | " + singer + " | " + album
songInfoList.append(SongInfo(song_name_str, singer, album))
songInfoList = []
url = urls.get('baidu_song')
url1 = url.format(song_name=song_name, start_idx=0)
content = self.view(url1)
if not content:
return []
analyse(content)
url2 = url.format(song_name=song_name, start_idx=20)
content = self.view(url2)
analyse(content)
return songInfoList[0:30]
这样我们就得到了百度网歌搜索结果的数据。然后就是保存数据了,这个我们最后会讲。
网易云音乐(动态网页)
当我们通过上述静态网页获取方式获取网易云音乐的数据时,可能会遇到这样一个问题:网页的源代码没有可用的数据,只有网页的骨架。数据根本找不到,但是打开开发者工具查看DOM树,就可以找到想要的数据了。这时候我们遇到一个动态网页,数据是动态加载的。无法获取网页数据。
目前有两种解决方案:
通过查看访问动态数据界面获取数据。获取网页源代码,通过网络自动化工具获取数据。
(目前网易云已经不能单纯通过访问url获取数据了,我们可以使用web自动化工具selenium和PhantomJS获取网页源代码) 方案一实现(通过查看动态数据接口获取数据):开启网易云音乐:打开浏览器调试模式F12,选择网络+全部模式
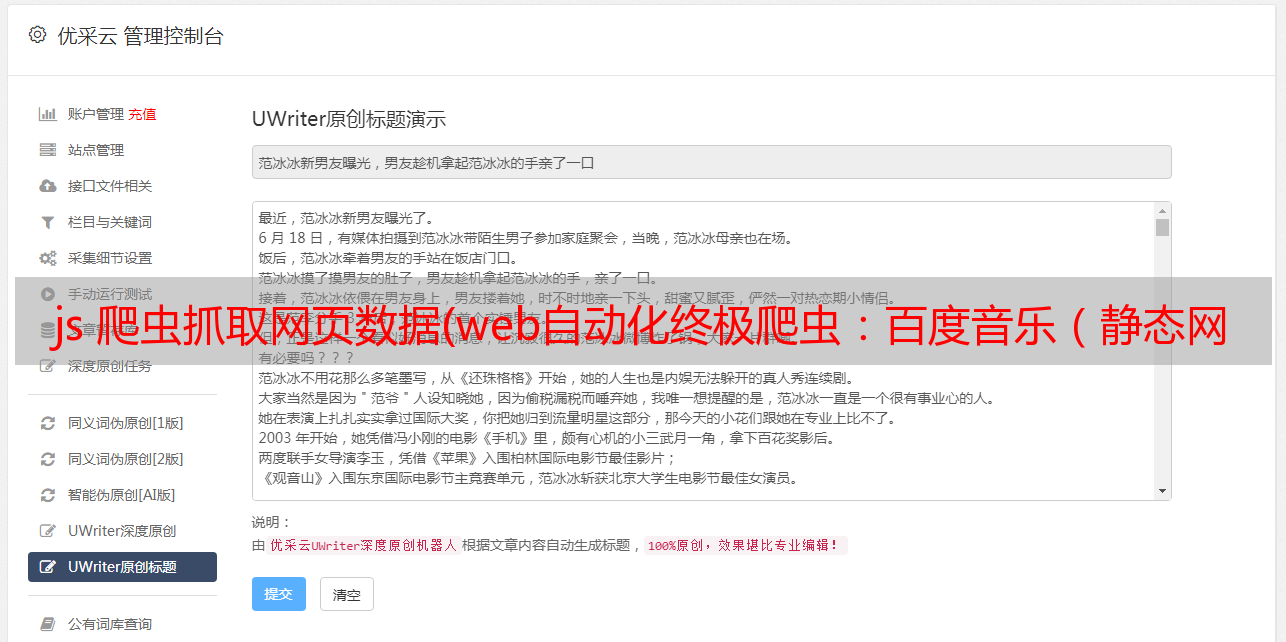
在搜索框中搜索歌曲(击败它),检查控制台
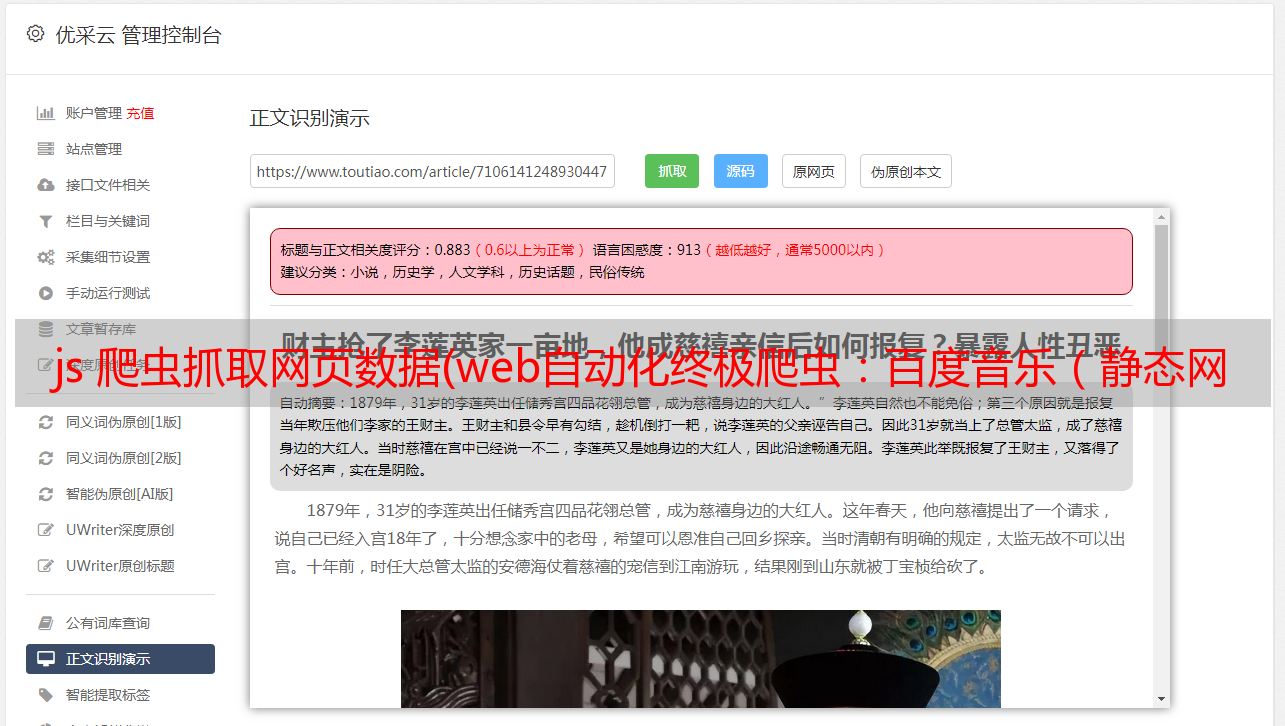
过滤到XHR的请求,发现请求名是一样的。这时候,我们看这些名字,看到Request URL中查找关键字搜索的请求。这个请求是一个 POST 请求。这应该是获取搜索数据的接口,通过查看响应或者预览来查看请求返回结果。正是我们想要的。
我们先不要太高兴,我们还没有弄清楚表单数据是如何组成的。params + encSecKey 究竟是如何生成的。我看过网上关于爬网易评论“如何爬网易云音乐?”的评论数。》,得知网易对api进行了加密。因为个人道教太浅了,看不懂这里加密参数的顺序和内容。所以这个方案放弃了。实在不甘心,只好改方案二。
选项 2 实现:
既然第一个方案暂时行不通,也不能影响我们的工作进度,我们继续换一种思路走。我认为使用 web 自动化测试工具 selenium 可以模拟手动操作浏览器。用这种方式导出网页数据应该没问题,我想马上就做。
安装selenium的环境配置
建议自动使用python包管理工具:pip install -y selenium
其他方法请参考:selenium + python自动化测试环境搭建
2.安装PhantomJS
PhantomJS 是一个基于 webkit 的 JavaScript API。它使用 QtWebKit 作为其核心浏览器功能,并使用 webkit 来编译、解释和执行 JavaScript 代码。您可以在基于 webkit 的浏览器中做的任何事情,它都能做到。它不仅是一个不可见的浏览器,提供诸如 CSS 选择器、对 Web 标准的支持、DOM 操作、JSON、HTML5、Canvas、SVG 等,它还提供处理文件 I/O 的操作,让您可以读写文件到操作系统等。PhantomJS的用途很广泛,比如网络监控、网页截图、免浏览器网页测试、页面访问自动化等等。
下载 PhantomJS
目前官方支持三种操作系统,包括windows\Mac OS\Linux这三大主流的环境。你可以根据你的运行环境选择要下载的包
1.安装 PhantomJS
下载后解压文件,将phantomjs.exe放到pythond目录下(C:\Python27\phantomjs.exe)。这样后续加载就不需要指定目录了。也可以放在特定的目录下,使用时可以指定phantomjs.exe的路径。双击打开phantomjs.exe,验证安装成功。如果出现下图,则安装成功。
2.实现的代码步骤:
def dynamic_view(url):
'''
使用自动化工具获取网页数据
:param url: 待获取网页url
:return: 页面数据
'''
# 初始化浏览器driver
driver = webdriver.PhantomJS()
# 浏览器driver访问url
driver.get(url)
# 坑:不同frame间的转换(网易云在数据展示中会将数据动态添加到'g_iframe'这个框架中,如果不切换,会报"元素不存在"错误。)
driver.switch_to.frame("g_iframe")
# 隐式等待5秒,可以自己调节
driver.implicitly_wait(5)
# 设置10秒页面超时返回,类似于requests.get()的timeout选项,driver.get()没有timeout选项
driver.set_page_load_timeout(10)
# 获取网页资源(获取到的是网页所有数据)
html = driver.page_source
# 坑:退出浏览器driver,必须手动退出driver。
driver.quit()
# 返回网页资源
return html
def search_163_song(song_name):
pass
也用于通过 BeautifulSoup 对网页资源进行对象化,通过过滤对象获取数据。没想到网易云音乐的数据也可以通过这种方式获取。对于大多数 网站 来说,能够做到这一点就足够了。
选择 PhantomJS 是因为它不需要可视页面,而且它节省了内存使用。但也有问题,请继续往下看。看起来快完成了。
3. 发现
解决方案:使用 Web 自动化获取数据。通过请求动态数据接口获取数据方案实现:
计划一:
使用网页自动化工具获取数据:配置同网易云配置,模仿用户操作浏览器打开网页,用户登录,进入搜索页面,获取页面数据
def spotify_view(url):
'''
使用自动化工具获取网页数据
:param url: 待获取网页url
:return: 页面数据
'''
spotify_name = 'manaxiaomeimei'
spotify_pass = 'dajiagongyong'
spotify_login = 'https://accounts.spotify.com/en/login'
# 初始化浏览器driver
driver = webdriver.PhantomJS()
# 模拟用户登录()
# 浏览器driver访问登录url
driver.get(spotify_login)
# 休息一下等待网页加载。(还有另一种方式:driver.implicitly_wait(3))
time.sleep(3)
# 获取页面元素对象方法(本次使用如下):
# find_element_by_id : 通过标签id获取元素对象 可在页面中获取到唯一一个元素,因为在html规范中。一个DOM树中标签id不能重复
# find_element_by_class_name : 通过标签类名获取元素对象,可能会重复(有坑)
# find_element_by_xpath : 通过标签xpath获取元素对象,类同id,可获取唯一一个元素。
# 获取页面元素对象--用户名
username = driver.find_element_by_id('login-username')
# username.clear()
# 坑:获取页面元素对象--密码
# 在通过类名获取标签元素中,遇到了无法定位复合样式,这时候可采用仅选取最后一个使用的样式作为参数,即可(稳定性不好不建议使用。尽量使用by_id)
# password = driver.find_element_by_class_name('form-control input-with-feedback ng-dirty ng-valid-parse ng-touched ng-empty ng-invalid ng-invalid-required')
password = driver.find_element_by_class_name('ng-invalid-required')
# password.clear()
# 获取页面元素对象--登录按钮
login_button = driver.find_element_by_xpath('/html/body/div[2]/div/form/div[3]/div[2]/button')
# 通过WebDriver API调用模拟键盘的输入用户名
username.send_keys(spotify_name)
# 通过WebDriver API调用模拟键盘的输入密码
password.send_keys(spotify_pass)
# 通过WebDriver API调用模拟鼠标的点击操作,进行登录
login_button.click()
# 休息一下等待网页加载
driver.implicitly_wait(3)
# 搜索打开歌曲url
driver.get(url)
time.sleep(5)
# 搜索获取网页代码
html = driver.page_source
return html
打完跑步后,一切都很好。突然代码报错(如下图)。查了资料后,代码也做了修改。
网络产品
将 clear() 添加到输入元素以清除原创字符。更换浏览器
方案实施:
计划一:
获取到对象后,为对象添加clear方法(username.clear()、password.clear())
实施成果
方案 1 失败。原因不清楚,大部分webdriver不兼容PhantomJS。
场景二:
换个浏览器,这次选择使用chrome浏览器来自动化操作。
安装 chrome 自动化控制插件。
我认为这将是获取数据的方式。烧鹅,还是没拿到,报错(如下图)
此时:是时候查看请求并找出令牌是什么了。并尝试将令牌添加到请求标头。
查看 cookie
但是我们登录后cookies列表中并没有这样的cookie!
据预测,该 cookie 应在网络播放器加载时播种。验证它:
从上表可以看出。加载播放器时会播种此令牌。
至此,问题解决了一大半。

