自动采集(京东搜索为例如何管理规则的线索?如下)
优采云 发布时间: 2022-01-16 15:23自动采集(京东搜索为例如何管理规则的线索?如下)
一、操作步骤
如果网页上有搜索框,但是搜索结果页面没有独立的URL,想要采集搜索结果,直接套用规则是不可能采集的。您必须首先执行连续操作(输入 + 单击)才能实现此目的。自动输入 关键词 并在 采集 数据之前搜索。下面以京东搜索为例演示自动搜索采集,操作步骤如下:
二、案例规则+操作步骤
注意:在这种情况下,京东搜索有独立的URL。对于具有独立URL的页面,最简单的方法是构造每个关键词的搜索URL,然后将线索URL导入到规则中,可以批量关键词@采集,而不是设置连续动作,可以参考“如何构造URL”和“如何管理规则线索”。
第一步:定义一级规则
1.1 打开Jisouke网络爬虫,输入网址回车,加载网页后点击“定义规则”按钮,会看到一个浮动窗口,叫做工作台,在上面定义规则;
注意:这里的截图和文字说明是Jisoke网络爬虫版本。如果你安装的是火狐插件版,那么就没有“定义规则”按钮,但是你应该运行MS Moujiu
1.2 在工作台中输入一级规则的主题名称,然后点击“检查重复项”,会提示“此名称可以使用”或“此名称已被占用,可编辑:是” , 你可以使用这个主题名称,否则请重命名。
1.3 这一层的规则主要是设置连续动作,所以排序框可以随意抓取一条信息,用来判断是否为爬虫执行采集。双击网页上的信息,输入标签名称,勾选确认,然后勾选关键内容,输入第一个标注的排序框名称,完成标注映射。
温馨提示:为了准确定位网页信息,点击定义规则会冻结整个网页,不能跳转到网页链接。再次单击定义规则,返回正常网页模式。
第 2 步:定义连续动作
单击工作台的“Continuous Action”选项卡,然后单击“新建”按钮以创建新的操作。每个动作的设置方法都是一样的。基本操作如下:
2.1,输入目标主题名称
这里的目标主题名称是填写二级主题名称,点击“谁在使用”查看目标主题名称是否可用,如果已经被占用,只需更改主题名称
2.2、创建第一个动作:回车
创建一个新动作并选择动作类型作为输入。
2.2.1、填写定位表达式
首先点击输入框,定位到输入框的节点,然后点击“Auto Generate XPath”按钮,可以选择“Preference id”或者“Preference class”,就可以得到输入框的xpath表达式,然后点击“搜索”按钮,检查xpath能否唯一定位输入框,如果没有问题,将xpath复制到定位表达式框。
注意:定位表达式中的xpath是锁定action对象的整个有效操作范围,具体是指鼠标可以点击或输入成功的网页模块,不要定位底部的text()节点。
2.2.2,输入关键词
输入关键词填写你要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词用双分号;;分开每个关键词,免费版只支持关键词5以内,旗舰版可以使用连发弹匣功能,支持关键词10000以内
2.2.3、输入动作名称
告诉自己这一步是做什么用的,以便以后修改。
2.3、创建第二个动作:点击
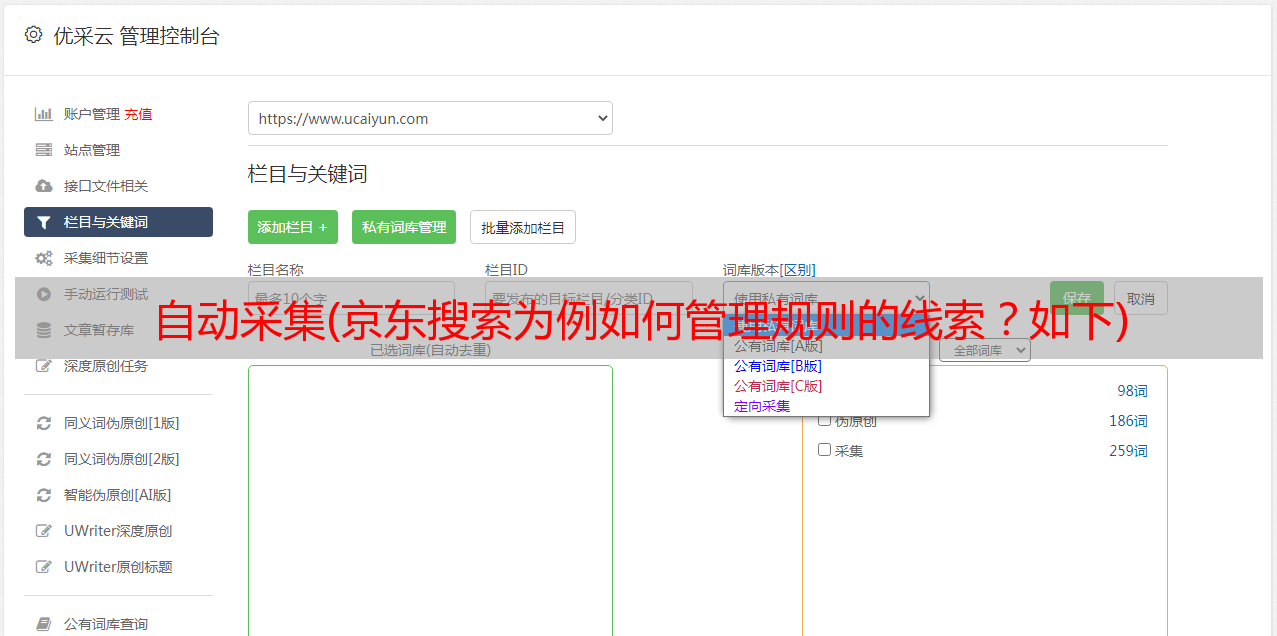
参考2.2的操作,创建第二个action,选择类型为click,定位到搜索按钮,然后自动生成一个xpath,检查是否锁定到唯一节点。如果没有问题,只需填写定位表达式即可。
2.4、保存规则
点击“保存规则”按钮保存完成的一级规则
第三步:定义二级规则
3.1,新规则
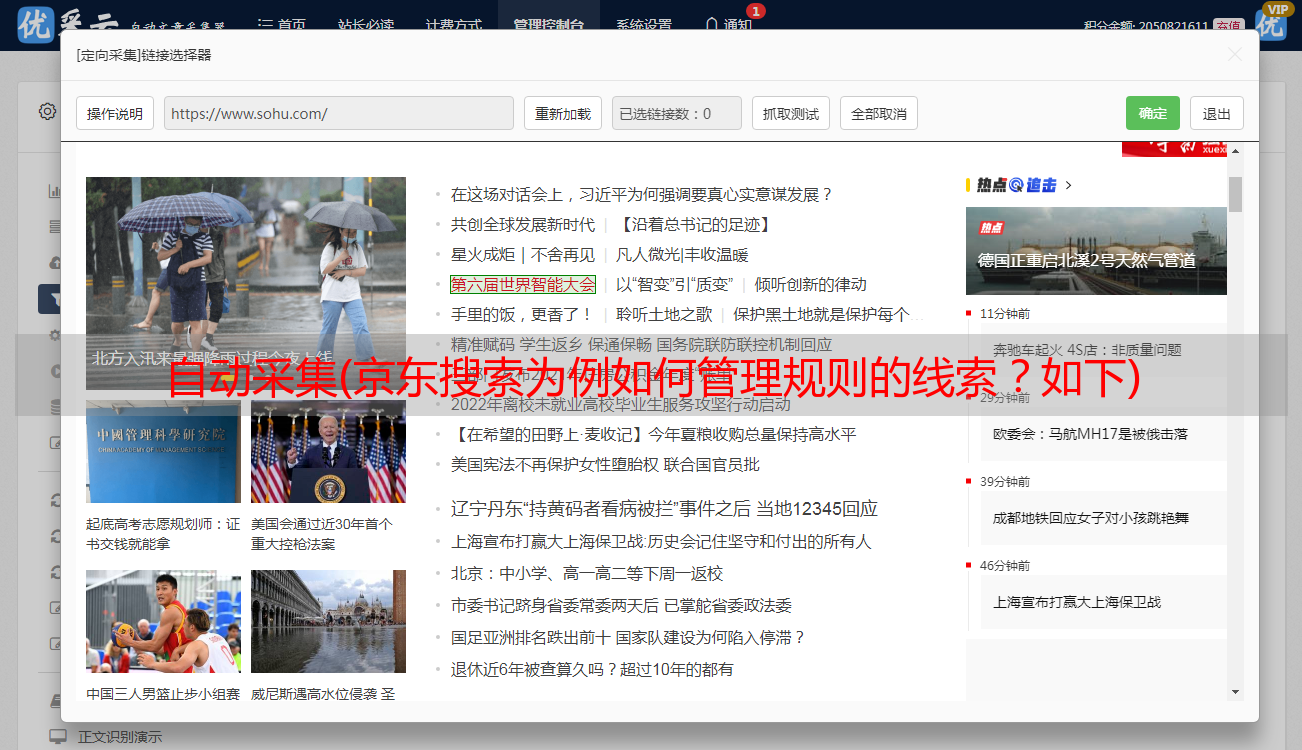
创建二级规则,点击“定义规则”返回普通网页模式,输入关键词搜索结果,再次点击“定义规则”切换到规则制定模式,点击左上角“规则”菜单->“新建”,输入主题名称,其中主题名称为一级规则连续动作填写的目标主题名称。
3.2、标记你要的信息采集
3.2.1、在网页上标记你想要的信息采集,这里是标记产品名称和价格,因为标记只对文本信息有效,链接是属性节点@href,因此不能用采集标记链接,而是做内容映射,具体操作如下。
3.2.2、用鼠标选中排序框的名称,然后点击鼠标右键,选择“添加”->“收录”创建抓取内容的“链接”,点击产品名称来定位,点击A标签属性下,可以找到对应的@href节点,右击该节点,选择Content Map to “Link”。
3.2.3、设置“Key Content”选项,以便爬虫判断采集规则是否合适。在排序框中,选择网页上一定要找到的标签,勾选“关键内容”。这里选择“名称”作为“关键内容”。
3.2.4、如果你只在前面标记一个产品,你也可以获得一个产品信息。如果你想采集一整页的每一个产品,你可以做一个样例 Copy,如果你不明白,请参考基础教程“采集列出数据”
3.3、设置翻页路线
在爬虫路由中设置翻页,这里是标记线索,不明白的可以参考基础教程《设置翻页采集》
3.4、保存规则
单击“测试”以检查信息的完整性。如果不完整,重新标注可以覆盖之前的内容。确认没有问题后,点击“保存规则”。
第 4 步:获取数据
4.1、连续动作是连续执行的,所以只要运行一级主题,二级主题就不需要运行。打开DS计数器,搜索一级主题名称,点击“单次搜索”或“采集”,可以看到浏览器窗口会自动输入关键词进行搜索,然后是二级主题将被称为自动 采集 搜索结果。
4.2,一级主题没有采集到有意义的信息,所以我们只看二级主题的文件夹就可以看到采集的搜索结果数据,搜索结果4.@关键词默认记录在xml文件的actionvalue字段中,以便一一匹配。

