文章句子采集软件(就是很难一篇文章讲解过垃圾网站的情况,如何配置发布端)
优采云 发布时间: 2022-01-06 02:17文章句子采集软件(就是很难一篇文章讲解过垃圾网站的情况,如何配置发布端)
上一篇文章解释了垃圾网站的情况,其中提到了一种特殊的垃圾网站,就是使用采集插件实现的内容网站 自动填充。
作者之前没有做过采集,近期打算搭建一个资源共享站点。由于资源和材料比较多,我自己做了,所以花了300块钱请人做了一个采集,研究一下以后不难发现,所以分享给大家今天。
一、了解插件采集
要想用好采集工具,首先要知道有哪些采集工具。如果你的网站是用各种开源系统搭建的(开源系统可以看我之前的文章),一般都会有对应的采集插件,也有一些著名的采集 软件。
在采集上,作者不专业。今天只分享作者使用的优采云采集软件。它不作为插件存在,而是作为一个独立的软件存在。在windows系统下运行。
要使用优采云采集,您需要知道如何配置发布者以及如何配置采集对象。所谓发布端就是你自己的网站,所谓采集对象就是你要提供的具体采集对象的页面内容。
二、如何配置发布者
既然是有钱人做的,这部分也正是作者无法解释清楚的,因为发布模块设置了访问密码。
既然作者花钱请人制作,就有理由相信模组的*敏*感*词*也在努力保护自己的劳动成果。但同时,作者还发现了一个网站发布模块,可以下载各种开源系统。
同时,这个网站中还有很多采集函数编写的学习类。有兴趣的朋友可以深入挖掘。如果你不想深入挖掘,你可以看看有没有你使用的。网站系统的发布模块。
三、如何配置采集终端
不得不说作者也是懒惰的,没有自己认真研究采集。我只是在别人写的规则的基础上研究了它。
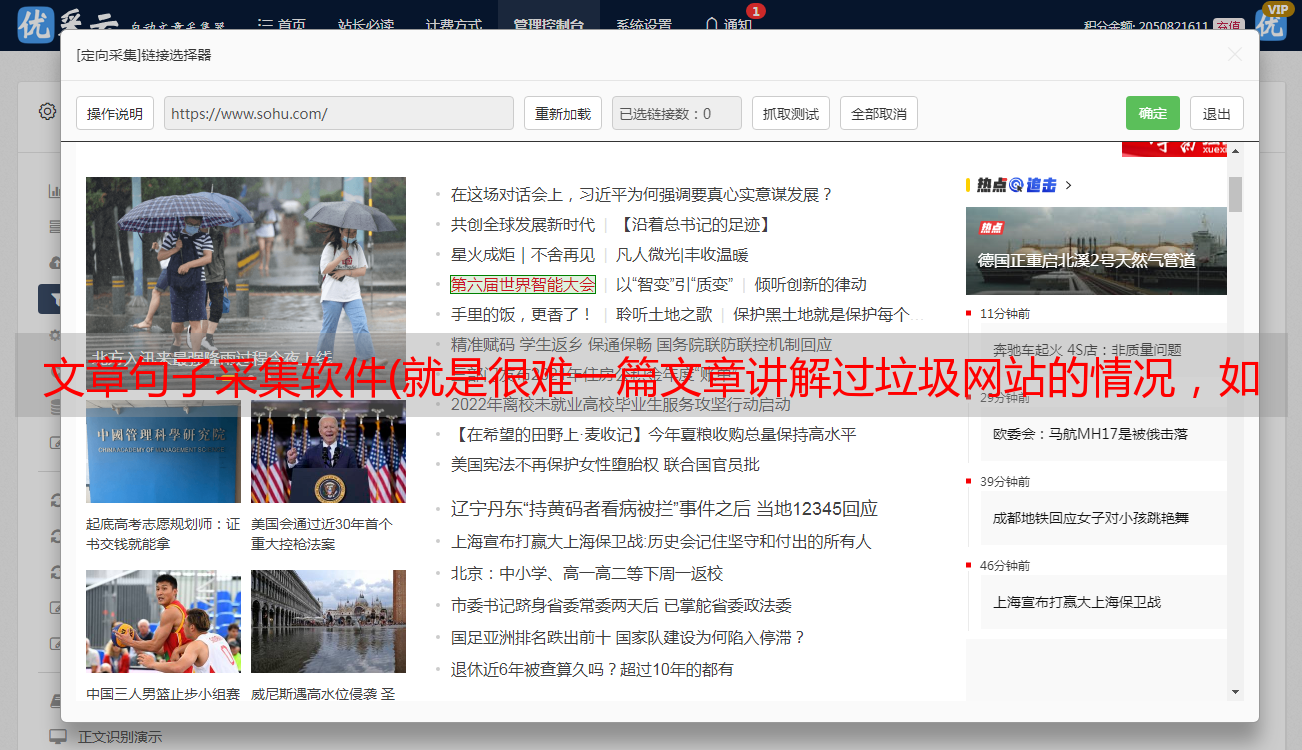
从上面的截图可以看出,这是采集配置的第一个地方。左边的“一级列表页面”表示我认为采集的页面只有一级列表。下一篇是干货!
1、 提取规则中的代码哪里来的?
· 通过浏览器打开起始网址(即我们想要采集内容的页面)
· 在打开的页面按F12(windows电脑)调出网页调试
· 选择小箭头(mac和windows系统不一样,自己找)
· 选择页面上的内容区域
仔细对比一下这里的代码是否和提取规则中的代码完全一样?没错,抽取规则就是以此内容为切入点。同时,提取此缩略图作为您自己的网站 发布的缩略图。
注意:[parameter]标签是需要提取的信息,(*)标签代表被忽略的信息。
2、在哪里可以找到设置区域?
还是用刚才的方法,这次我们用小箭头选择整个列表页:
我们比较一下
而另一个其实是翻页标签。你应该知道这个列表有很多分页。采集 系统需要识别翻页的位置:
此外,还有一些配置需要完成,但基本操作方法类似。如下所示:
3、内容采集规则
请注意,上面的标签列表因人而异。只有标题和内容是通用的。这里主要讲一下title和content的提取:
首先我们要进入采集对象的文章内容页面,然后使用和之前一样的方法获取源码部分。一般标题默认会在head标签中(如果你不知道head标签是什么,可以阅读我之前的文章前端集成介绍):
所以填写固定标签:“title”:“[参数]”!如下所示:
意思是读取title:标签后面的参数。请注意,这里选择的是常规提取,即从特定的内容中提取我们需要的参数。采集。请注意,截图下方有数据处理。这是什么意思?
正如你在截图中看到的,毕竟是来自别人的网站采集内容。难免别人会带一些自己的网站标志,自然要使用别人的内容。如果不想别人的网站标志,则需要使用数据处理功能自动替换我们要替换的部分内容。
可以看到里面有很多高级替换功能。如果你想移除它,就拿移除规则,你可以自己研究其他规则。
注:数据处理可以同时添加多个规则,可以同时处理多个替换功能。
下面介绍采集的内容。在内容区域,我们选择截取前后。这是什么意思?通过定义head和tail,采集的head和tail之间的所有内容:
上面第一个框中截取的代码是开头,第二个框中截取的代码是结尾。因为代码是折叠的,所以你可能看不到详细的代码,但是你不需要它。让我们从上面的浏览器转到绿色。而蓝色区域可以看出文章的整个内容区域其实已经被截取了。
填写开始字符串和结束字符串。那么在数据替换中,为了避免采集到达的信息以代码的形式被采集给自己网站,我们需要做一些数据处理得到采集 把内容变成了尽可能简单的文字!其中,HTML标签排除的应用可以排除一些我们不想采集的内容:
其他采集对象需要根据实际发布的项目为采集,一般规则类似!终于可以测试采集并发布了,会玩小电脑的小白可以自己摸一摸!(反正小编之前没碰过采集,有模型可以参考,不会瞬间知道!)
四、结论
小编之前没玩过采集。第一次接触,感觉真的很方便,于是不自觉的分享了起来!作为教程有一些不足,就是让大家有个基本的了解。如果想系统学习,可以找一些采集的资料来学习!最后一点,本文中演示的采集对象仅用于演示,织梦理解。

