文章cms采集(如何找列表索引分页标签,宾哥唯一的图7)
优采云 发布时间: 2022-01-02 09:21文章cms采集(如何找列表索引分页标签,宾哥唯一的图7)
发现不是唯一的,每个列表项都有这个代码,只能选择上层容器,
搜索发现只有这个,而这个是我们的列表
所以,在选择列表范围时,应该如图7所示,
图 7
细心的朋友会问。我没有告诉你如何找到列表索引选项卡。 Bing看了一眼搜狐。由JS控制来减少或增加页面。于是Bing颤抖着Clever,我刚点了两次下一页,发现页面在减少。这样,我就放心了。根据批量生成的方法,我设置了一个范围。不过我建议大家,第一次采集以后采集的时候可以这样做,直接关闭列表索引分页,也就是选择不设置,就这样看到这里,点击步骤,
图 8
在图8中,我们可以看到有我们想要采集的消息。由于斌哥的笔记本屏幕小,更多的内容我们无法截图,大家就看吧。获取文章的每一个链接,这里不是寻找唯一性,而是寻找每个文章容器中的URL信息。这时候就要回到采集的文章列表页面的源码,如图9
图 9
红线标注的是他的链接信息,但是我们发现下面还有一个,不然选择的时候,这个文章会出现两次采集,所以选择上面的那个另一边,有全文的那个,因为看全文会发现这个文章的唯一性,我们要选择http:~~~ .shtml,所以,比在引号里面好,如图10
图 10
那么,我们的文章列表就整理好了采集的规则是,如图11,然后下一步,检查是否可以抓取到文章的URL .
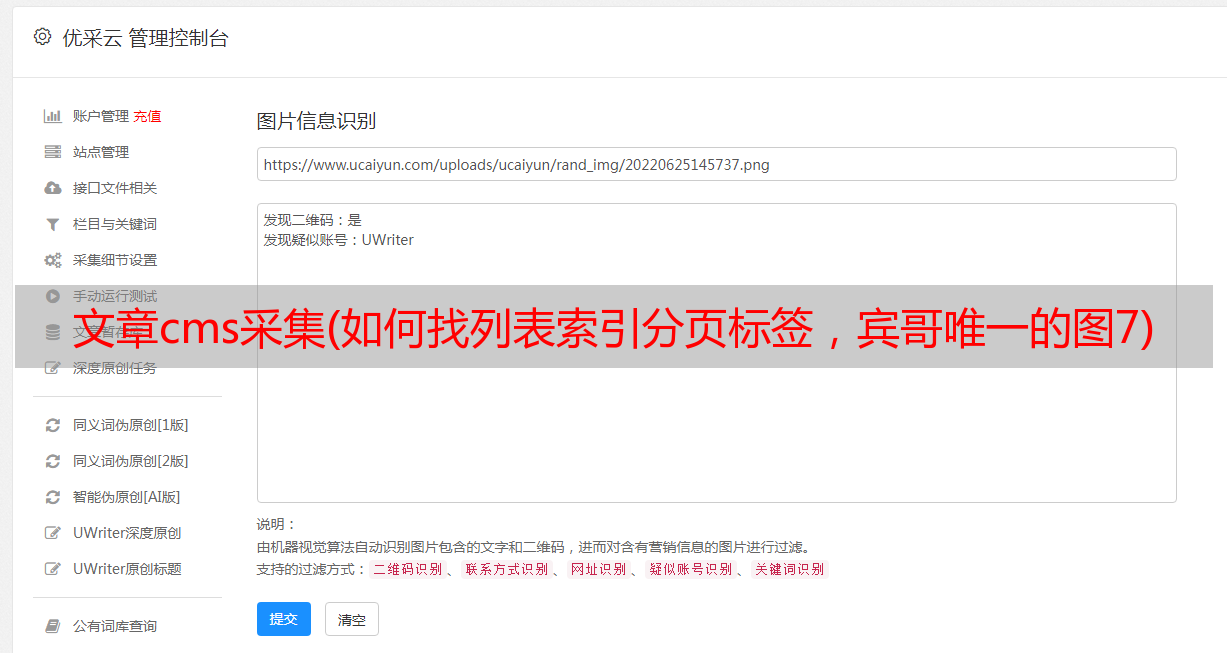
图 11
下一步之后,我们可以看图12,除了标题和内容,还有时间作者等,可选选项,大家可以根据自己的需要选择,还有左下角,也是我们上一步的测试结果,
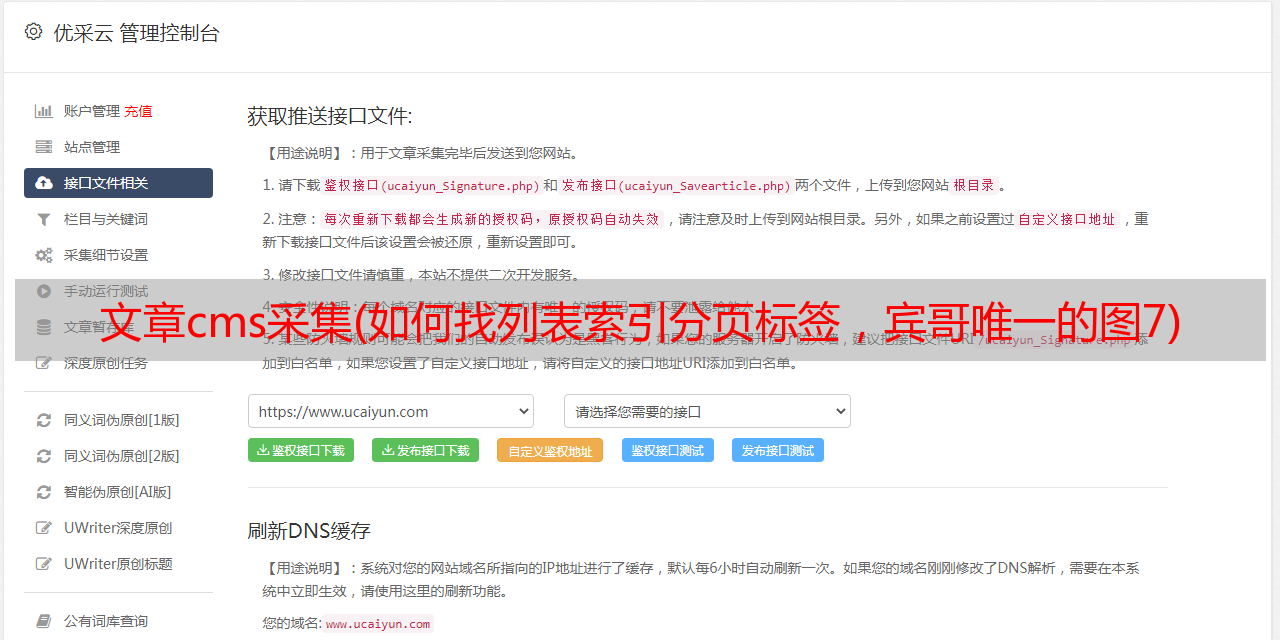
图 12
随便打开一篇文章网站文章,打开这篇文章文章,还是查源码,设置规则,我们要采集他的标题和内容,
在源码中搜索文章标签,发现有两条信息。第一个肯定是标题信息。可以忽略,也可以在这里设置规则,但是不推荐,因为有一些网站这里的文字是一样的。这样,检索到的文章标题是一样的,
当我设置规则时 图 13
图 13
点击下一步后会发现我们已经捕获到了这个文章的信息,如图14
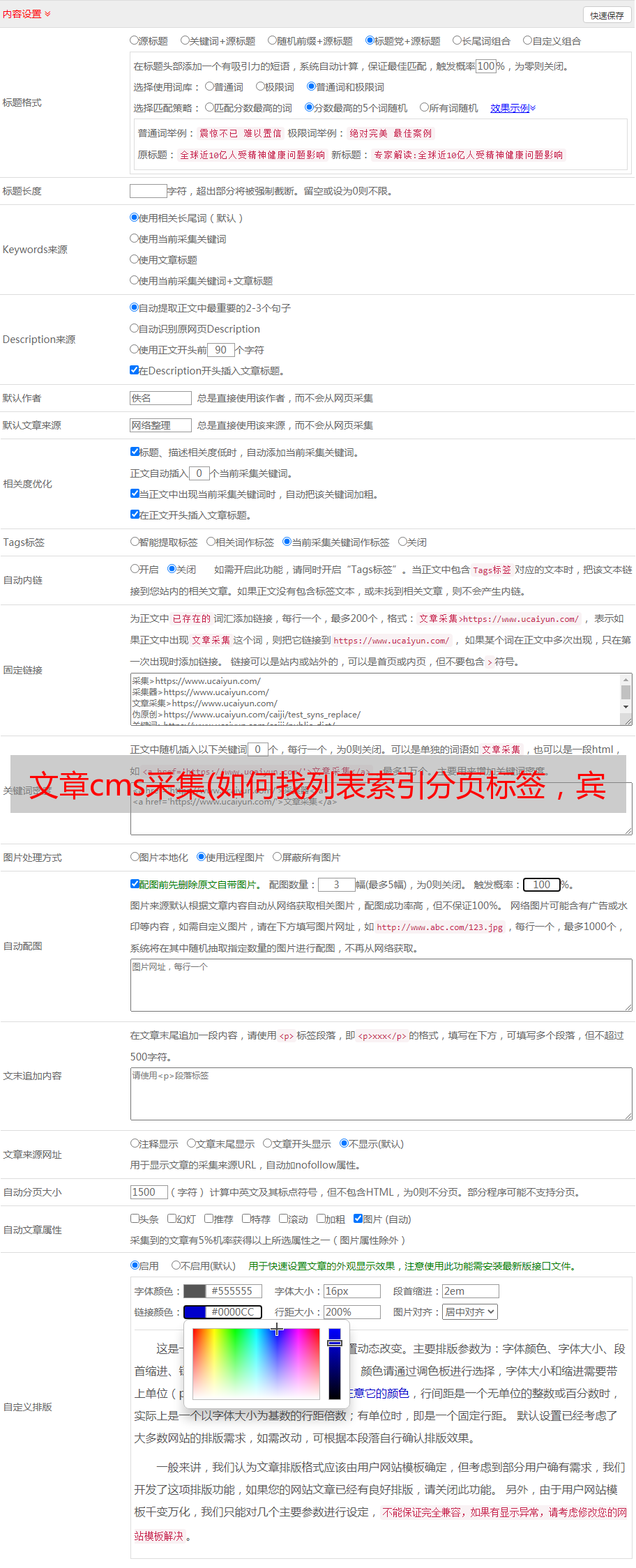
图 14
然后向下滚动浏览器,发现下面,有上一步和下一步,我们点击下一步,就到了设置规则的最后一步,如图14
图 14
说明,在图14中,除了上半部分根据自己的需要进行设置外,还有一个比较重要的,就是标签过滤。你可以参考我的。如果需要采集其他人的FLASH文件,取消Object即可。在采集选项中,建议选择保存图片。其他的根据你的需要设置。还有存储选项。建议选择审核,我们保证测试。值得注意的是,如果不审计直接进入存储,必须选择“立即写入主库,直接生成内容页面”,因为此项会自动生成一个静态页面。如果不选择此选项,将无法打开采集即将到来的文章。
采集方法介绍
规则设置好了,我必须采集新闻,如何采集,其实这是一键操作
图 15
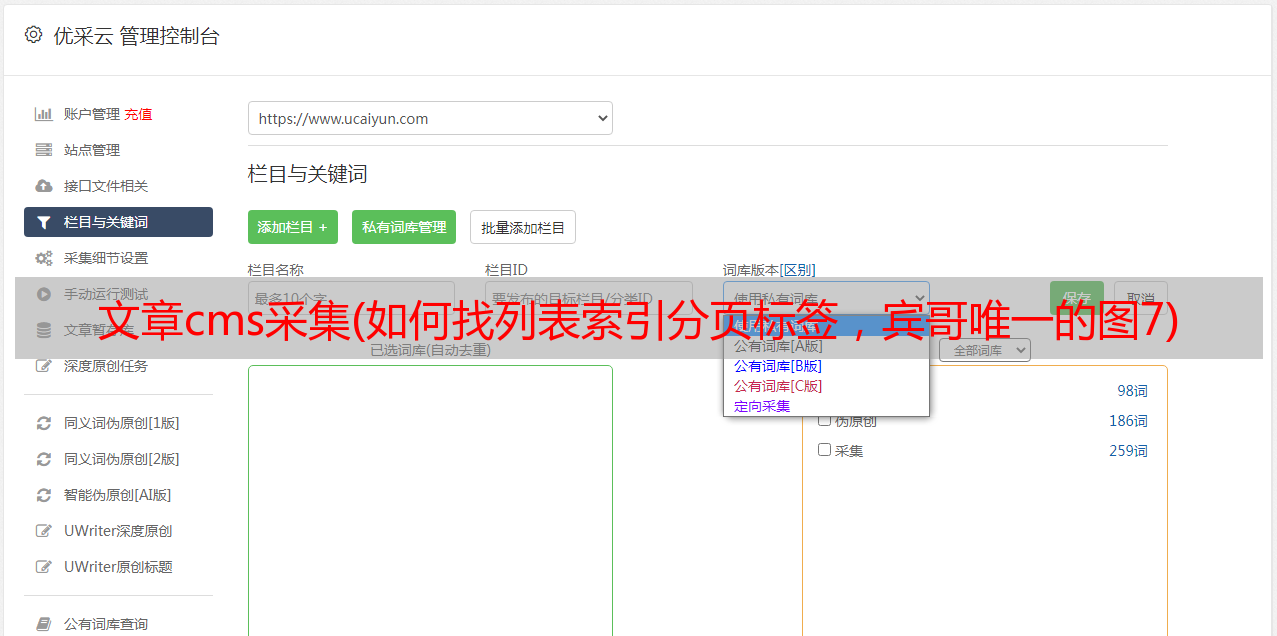
图 15
只需点击 采集,就可以了。细心的朋友会再次看到一个克隆。其实这是一个方便的和网站列设置一样的风格。比如我可以采集搜狐的国内时事,他们用的是同一个模板,所以我只需要改名,修改采集的列URL和页面URL规则,就这样。
大家都学会了吗?在搜狐修改版本之前,请尽快尝试设置~~~
这个文章是冰哥写的。如需采集,请关注出处。白天不要让 Bing 去上班。加班加点完成本教程的辛苦下班~~

