全托管文章智能采集系统(爱爬虫的人,我肯定要演他!(一))
优采云 发布时间: 2022-01-01 14:21全托管文章智能采集系统(爱爬虫的人,我肯定要演他!(一))
前言
因公司业务需要,需要获取客户提供的官方微信微信账号历史文章并每日更新。很明显,300多个微信公众号不能每天人工查,问题提交给IT团队。对于喜欢爬行动物的人,我肯定会玩他。之前在搜狗做微信爬虫,后来一直在做java web。这个项目重新点燃了我对爬行动物的热爱。第一次用纯云架构做爬虫,用了20多天,终于尘埃落定。接下来我将通过一系列文章来分享这个项目的经验,并提供源码给大家指正!
一.系统介绍
本系统基于Java开发。只需配置微信公众号或微信公众号,即可定时或即时抓取微信公众号上的文章(包括阅读、点赞、阅读)。
二、系统架构
技术架构
春运、反弹、Mibatis-Plus、Nacos、RocketMq、nginx
保存
Mysql、MongoDB、Redis、Solr
缓存
使用体验
组织
小提琴家
三、系统的优缺点
系统优势
1. 微信公众号配置好后,可以通过Fiddler和Websocket的JS注入功能自动抓取; 2. 系统是高可用的分布式架构; 3.Rocket Mq Message 队列解耦可以解决网络抖动导致的采集失败。 3、消费不成功,日志会记录到mysql中,保证文章的完整性; 4.可以添加任意数量的微信账号,提高采集效率,抵抗反爬限制; 5.Redis缓存每个微信账号24小时内采集到的记录,防止headers; 6.Nacos作为配置中心,可以通过热配置实时调整采集的频率; 7. 将采集数据存储在 Solr 集群中以提高检索速度; 8. 将抓包返回的记录存放在MongoDB存档中,用于查看错误日志。
系统缺点:
1. 通过真实设备采集消息。如果需要采集大量微信公众号,需要有多个微信公众号作为支撑(当日帐号达到上限,可通过微信官方平台界面获取消息); 2. 不是微信公众号,一发消息就可以抓到。 采集时间由系统设置,消息有一定的滞后性(如果微信公众号不多,可以通过增加采集的频率来优化微信公众号)。
四.模块介绍
因为管理系统和API调用函数会在后面添加,所以提前封装了一些函数。
公开-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:
spring-boot-starter-data-Redis的二次打包,公开打包的Redis工具类和Redisson工具类。
rockemq-ws-starter
Rocket Mq 模块:定位
Rocket MQ-spring-boot-starter二次封装提供消费重试和故障记录功能。
db-ws-starter
Mysql数据源模块:封装mysql数据源,支持多种数据源,通过自定义注解实现数据源的动态切换。
sql-wx-spider
Mysql数据库模块:提供操作mysql数据库的所有功能。
pc-wx-spider
PC端采集模块:收录微信公众号历史信息PC端采集的相关功能。
java-wx-spider
Java提取模块:收录从Java程序中提取文章内容的相关函数。
mobile-wx-spider
模拟器采集模块:包括通过模拟器或手机采集进行信息交互量相关的功能。
动词(动词的缩写)一般流程图
六、运行截图
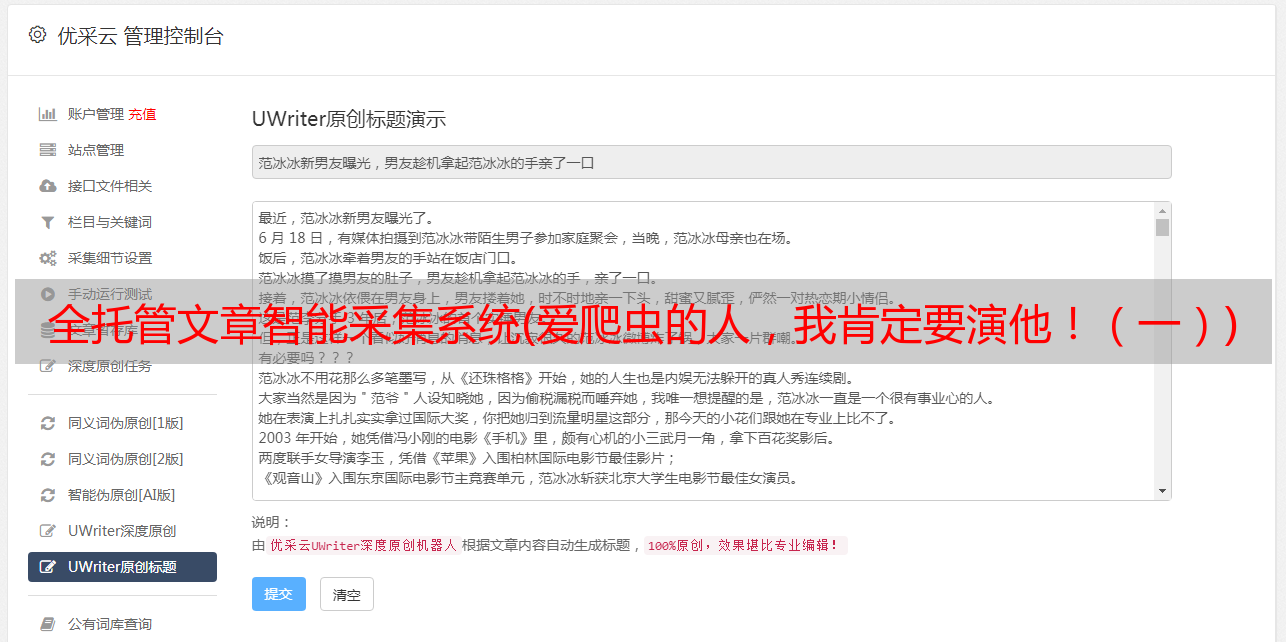
个人电脑和手机
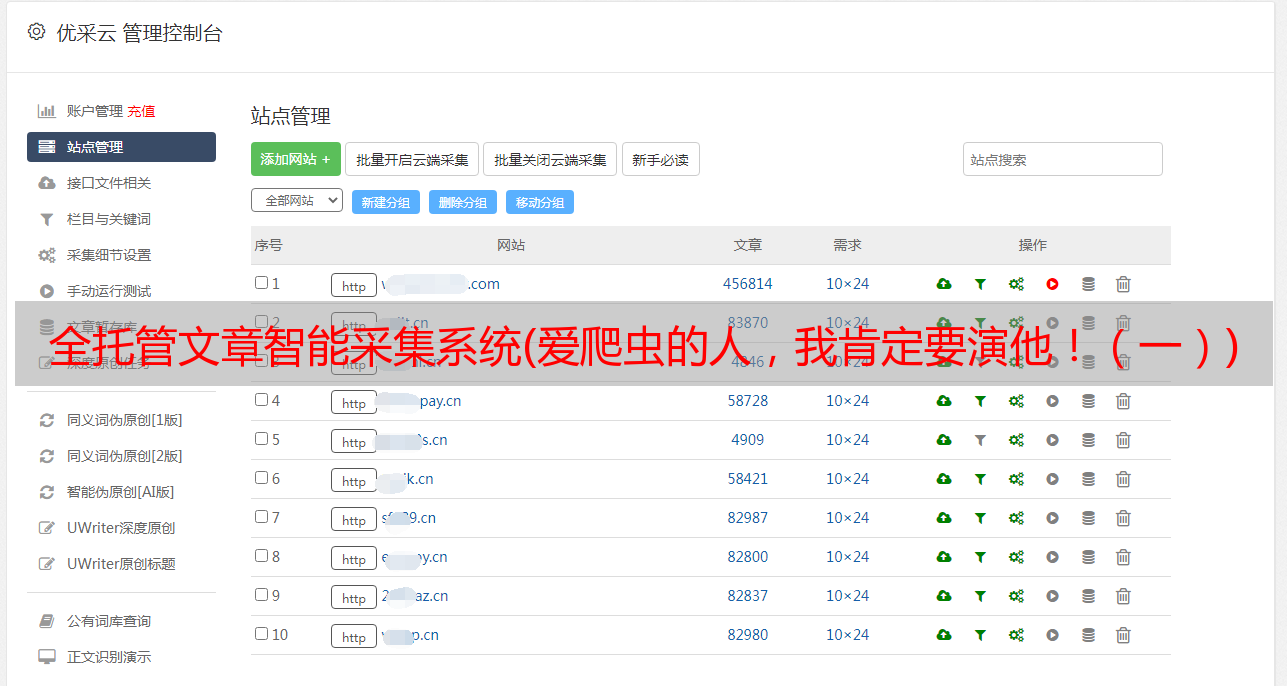
控制面板
操作结束
总结
项目的亲测已经投入运行。项目开发中解决了微信临时链接到搜狗永久链接的问题。希望对被类似业务困扰的老铁有所帮助。现在,做java就像逆流而上。不前进就会后退。不知道什么时候会涉及。祝大家都有属于自己的葵花宝。看到这个不就采集了吗?

