采集器的自动识别算法(如何采集手机版网页的数据?如何手动选择列表数据 )
优采云 发布时间: 2021-12-18 23:02采集器的自动识别算法(如何采集手机版网页的数据?如何手动选择列表数据
)
指示
一:输入采集 URL
打开软件,新建一个任务,输入需要采集的网站地址。
2:智能分析,全程自动提取数据
进入第二步后,优采云采集器自动对网页进行智能分析,从中提取列表数据。
三:导出数据到表、数据库、网站等。
运行任务,将采集中的数据导出到表、网站和各种数据库中,支持api导出。
计算机系统要求
可以支持windows XP以上系统。
.Net 4.0 框架,下载链接
安装步骤
第一步:打开下载的安装包,选择直接运行。
第二步:收到相关条款后,运行安装程序PashanhuV2Setup.exe。安装
第三步:然后一直点击下一步直到完成。
第四步:安装完成后可以看到优采云采集器V2的主界面
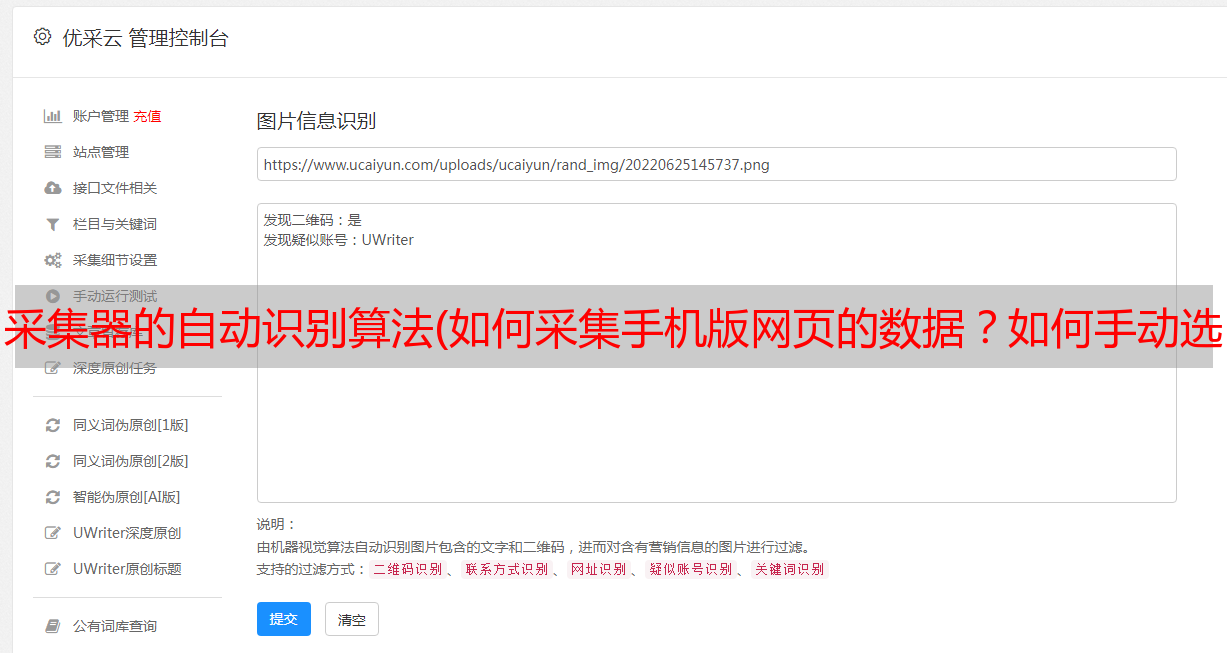
常问问题
1、如何采集手机版网页的数据?
一般情况下,一个网站有一个网页的电脑版和一个手机版的网页。如果电脑版(PC)网页的反爬虫很严格,我们可以尝试抓取手机网页。
①选择新建编辑任务;
②在新创建的【编辑任务】中,选择【步骤3,设置】;
③设置UA(浏览器识别)为“手机”。
2、如何手动选择列表数据(自动识别失败时)
在采集列表页面,如果列表自动识别失败,或者识别的数据不是我们想到的数据,那么我们需要手动选择列表数据。
如何手动选择列表数据?
① 点击【全部清除】清除现有字段。
②点击菜单栏中的【列表数据】,选择【选择列表】
③用鼠标点击列表中的任意元素。
④ 单击列表中另一行中的相似元素。
正常情况下,采集器此时会自动枚举列表中的所有字段。我们可以对结果进行一些更改。
如果字段未列出,我们需要手动添加字段。单击[添加字段],然后单击列表中的元素数据。
3、采集文章 鼠标无法选择全部内容怎么办?
一般在优采云采集器中,通过鼠标点击选择要抓取的内容。但是,在某些情况下,例如要抓取文章 的完整内容时,当内容很长时,鼠标有时会难以定位。
①我们可以通过在网页上右键单击并选择【检查元素】来定位内容。
②点击【向上】按钮展开选中的内容。
③扩展到我们整个内容的时候,全选【XPath】,然后复制。
④ 修改字段的XPath,粘贴刚才复制的XPath,确认。
⑤最后修改value属性。如果您需要 HMTL,请使用 InnerHTML 或 OuterHTML。