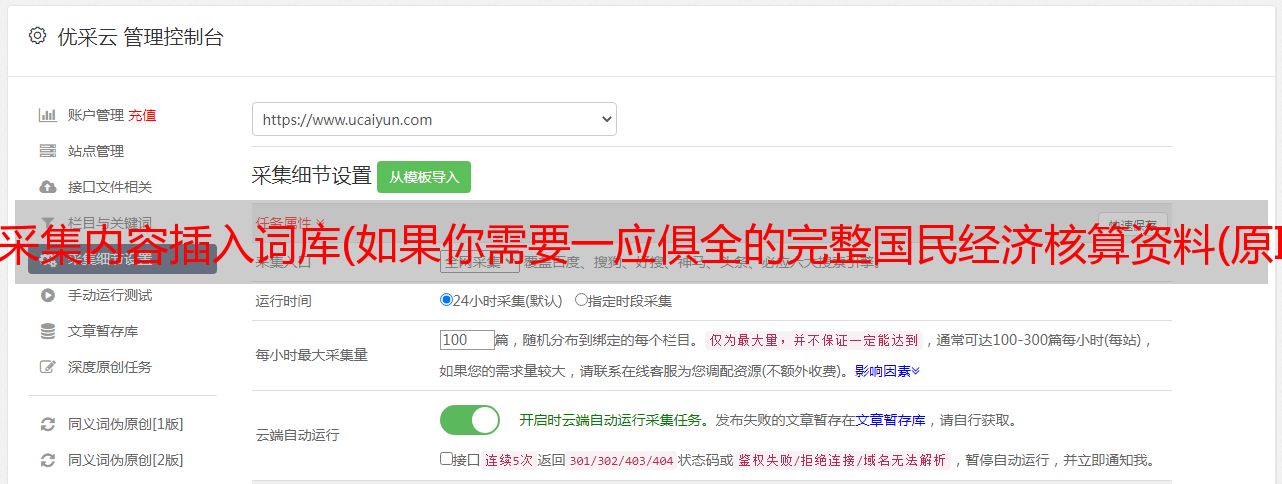
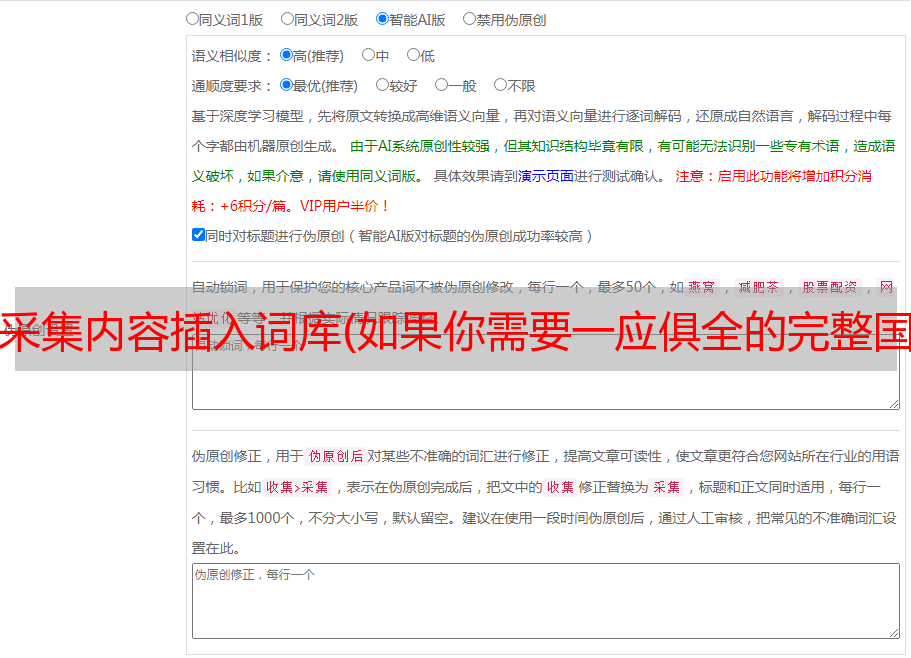
采集内容插入词库(如果你需要一应俱全的完整国民经济核算资料(原ICTCLAS))
优采云 发布时间: 2021-12-08 05:00采集内容插入词库(如果你需要一应俱全的完整国民经济核算资料(原ICTCLAS))
在生活中,我们可以通过多种渠道获取相关数据。
搜索“中国统计年鉴”。许多图书馆都有《中国统计年鉴》等。翻出收录您需要的数据的页面。复印是一个不错的选择。当然,你也可以选择拿出纸和笔。复制您需要的所有数据。为了便于对这些数据进行进一步的处理,接下来的工作可能会有些枯燥:将找到的数据一一输入电脑。当然,现在情况已经好了很多。例如,要查找 2004 中国统计年鉴,中华人民共和国国家统计局 网站 提供了免费下载。
如果您需要所有最新的宏观经济数据,那就是中国国家统计局提供的“进展统计”。
如果要从数据采集之日起获得完整的国民核算数据,权威来源是《中国GDP核算历史数据》(1952-1995)和《中国GDP核算历史数据》(1996-2002)) @>.这两本年鉴都提供了中国GDP的详细数据,特别是《中国GDP会计历史数据》(1996)-2002)@>提供了电子版,电子版数据不仅提供了详细数据从1996年到2002年,也大致追溯了1952年到1995年的数据,非常好用。
如果想从数据采集之日起获得更完整的宏观经济数据,《新中国50年统计数据汇编》和《新中国55年统计数据汇编》是不错的选择。不幸的是,它们都没有提供电子版本,但后者可以从中国信息银行下载。
此外,还有很多收费网站可以提供更详细的中国宏观经济数据,如信息*敏*感*词*库、中国经济信息网等。
国内的大数据处理信息工具很多,但大多是近年来兴起的大数据技术,图像处理需要先转换成文本再进行处理。通过对几款国内主流中文分词工具产品的试用,下面为大家推荐几款中文分词工具:
一、NLPIR大数据语义智能分析平台(原ICTCLAS)由北京理工大学大数据搜索与挖掘实验室主任张华平开发。融合网络精准,满足大数据内容采集、编辑、搜索的综合需求。采集 近二十年来自然语言理解、文本挖掘、语义搜索等最新研究成果不断创新。平台提供客户端工具、云服务、二次开发接口等多种产品使用形式。每个中间件API都可以无缝集成到客户的各种复杂应用系统中,兼容Windows、Linux、Android、Maemo5、FreeBSD等不同操作系统平台,
NLPIR大数据语义智能分析平台的十三项功能:
NLPIR大数据语义智能分析平台客户端
精准采集:*敏*感*词*海量信息实时精准采集,主题采集(主题根据信息需求采集)和站点采集 两种模式(给定网站列表内的定点采集 功能)。
文档转换:将文本信息转换为doc、excel、pdf、ppt等多种主流文档格式,效率满足大数据处理要求。
新词发现:从文本中发现新词、新概念,用户可将其用于专业词典的编纂,并可进一步编辑标注,导入分词词典,提高分词系统的准确率,并适应新的语言变化。
批量分词:对原创语料进行分词,自动识别姓名、地名、机构名称等未注册词,新词标注,词性标注。并在分析过程中,导入用户自定义词典。
语言统计:根据分词和标注结果,系统自动进行一元词频数统计和二元词转移概率统计。对于常用术语,会自动给出相应的英文解释。
文本聚类:可以从*敏*感*词*数据中自动分析热点事件,并提供事件主题的关键特征描述。同时适用于短文、微博等长文和短文的热点分析。
文本分类:根据规则或训练方法对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等诸多方面。
抽象实体:对于单个或多个文章,自动提取内容摘要,提取人名、地点、机构、时间和主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容进行语义智能过滤和审核,内置国内最全面的词典,智能识别多种变体:变形、音变、繁简变体,精准语义消歧。
情感分析:针对预先指定的分析对象,系统自动分析海量文档的情感倾向:情感极性和情感价值度量,并给出原文中的正负分和句例。
文档去重:快速准确判断文件集或数据库中是否存在内容相同或相似的记录,同时找出所有重复记录。
全文搜索:支持文本、数字、日期、字符串等多种数据类型,多字段高效搜索,支持AND/OR/NOT、NEAR接近等查询语法,支持维吾尔语、藏语、蒙语、阿拉伯语和韩语 搜索各种少数民族语言。
代码转换:自动识别内容的代码,统一将代码转换为其他代码。
以上为个人观点,仅供参考,希望能帮到你!

