从异构数据源收集信息并转换为用户需要的信息过程
优采云 发布时间: 2021-04-03 03:04
从异构数据源收集信息并转换为用户需要的信息过程
关于Internet信息的思考采集
[本文是在这里进行集思广益。请发送任何建议。欢迎来到我的主页]
Internet的飞速发展为我们提供了丰富的信息,但同时也提出了如何有效使用它的问题。 “丰富的数据和知识不足”的问题变得越来越突出。当前的数据挖掘方法通常称为“知识发现”或“数据挖掘”。知识发现涉及诸如数据采集,数据清理和数据输出之类的过程。它是统计,模式识别,人工智能,机器学习和其他学科的结合。可以将其视为这样的过程:从异构数据源采集信息并将其转换为用户所需信息的过程。
信息源的异构性是难以重用的网络信息的焦点。由于网络信息的异构性,因此在Internet信息的重用中“难于采集”和“难于组织”。*敏*感*词*许多公司和企业在研发上投入了大量的财力和物力。现在有许多工具和产品,通用搜索引擎(例如Google)和更专业的搜索引擎(例如mp3)。专门用于采集,例如“信息仓库”。例如,Teleplort pro或Google后端中的Robot程序可以收录在信息采集类别中,而我负责开发的CGCrobot程序具有一定的数据重组功能。但是,这些产品通常高度专业化,不适合小型企业和个人用户。即使像Teleport Pro这样的个人用户都可以使用它,下载的(页面)数据在重新使用之前通常也需要大量的编辑工作。到目前为止,还没有一种更适合个人用户和企业的更方便的数据采集和排序工具。
本文尝试从另一个角度进行数据挖掘。也就是说,尽管Internet上的数据非常复杂,但它是针对特定网站和网页的结构。如果您忽略原创的结构关系,尽管这个想法简单明了,但仅限于人工智能技术,即使是最先进的系统也无法满足当前用户应用程序的大多数需求。
然后,如果我们可以分析具有布局元素与页面之间的关系的原创网站,然后根据用户的指示,将这些元素之间的关系转换为用户所需的数据,那么我们说采集该系统有效地利用了网站生产者和用户的智慧。
一个。网页功能
在本文中,显示网页时可以显示给用户的元素称为网页元素,包括与视觉,听觉和窗口事件有关的元素。它与网页的特定内部元素具有一定的关系。但是本文更多是从用户的角度出发。如果您不从用户的角度出发,则会使软件难以使用或功能太弱。
1。网页元素本身的属性
1)。网页元素具有空间属性。显示网页时,空间属性不仅显示在平面关系(x,y轴)上,还显示在z轴上。例如,网页元素可以覆盖网页的另一个元素或背景。
2)。网页元素具有时间属性。网页元素可以不断移动,也可以在特定时间显示,等等。
3)。网页元素具有事件属性。网页元素可以响应鼠标事件等。
4)。网页元素也可以是体育。它们也可以表现为听觉(音乐)。
2。网页元素之间的关系
1)。空间位置通常是相对的。一个网页元素的位置会影响另一个网页元素。
2)。时间上可能存在顺序关系。例如,一个元素在显示后只能显示另一个元素。或一个元素只能在单击另一个元素后才能更改。
如果提倡网页元素的概念,则窗口也可以视为(复合)网页元素。窗口的标题,状态行,URL等也是网页元素。但是,在特定的设计中,有必要正确定义网页元素概念的范围,以避免根本无法实现或难以实现的情况。
3)。父子关系。父元素由子元素组成。在平面显示器上,通常看起来父元素完全收录子元素(尽管有时可以打破这种关系)。
两个。信息采集
信息采集表示用户指定需要采集的内容,该内容映射到数据库的哪一部分以及其他采集规则,然后系统执行采集。根据用户提供的信息。 ]。非常重要的一点是软件系统的易用性。有很多方法可以提高易用性,例如Teleport或CGCrobot的采集规则限制; CGCrobot的自动提取方法,以及当前指定的网页布局元素及其关系等等。为了形成竞争体系,应提供这些手段。
现在仅考虑网页元素及其关系。实际上,此时,用户需要告诉采集系统:在采集哪个元素之前需要经历哪些步骤(或事件),并将该元素放置在数据库的特定部分中。涉及三个步骤:1)用户在设置采集时需要经历的过程; 2)用户设置采集什么样的元素; 3)在数据库中放置此元素的用户设置。
下面是一个简单的示例,此示例实际上更方便使用其他方法采集。
假设我们需要采集下图1中的区域A中的所有文档,并提取图2中的作者,翻译者,标题和文本。还要假设我们只能从采集中输入。然后采集流程可以定义为:
导航到();
点击“翻译作品”区域;
重新加载A区时
{
对于区域A中的每个链接
{
点击链接;
当B区域出现时// B区域需要用户定义。
『
使用B区大于XX的字体作为标题。
在B区域中找到文本,并使用“翻译器:”之后的文本作为翻译器。
』
}
}
请注意,区域B中不再定义子区域。当然,区域B也可以定义为三个区域,即标题,文本和翻译器。标题区域将规则设置为大于字体大小,并且其空间位置位于顶部。并且翻译器可以定义为收录字符串“ translator:”的行。
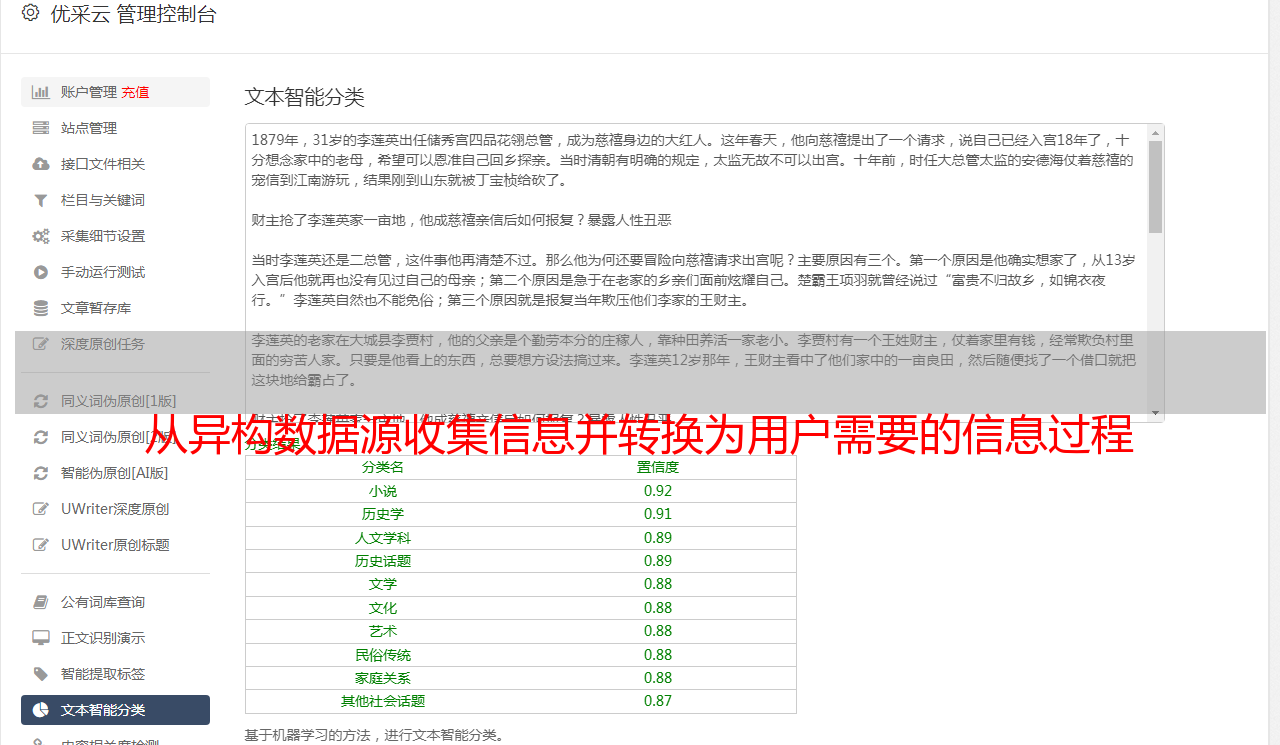
图1
图2
三个。信息重组
将采集的数据放入数据库中时。我们说这次已经基本满足了用户的需求。但是可能会有一些问题。例如,由于规则定义不够详细,因此采集中还应收录不应定义为采集的内容。此时,用户需要手动组织数据。在考虑实施功能强大的系统时,您还应该考虑如何灵活地重新排列信息。但是本文将不再讨论这些内容。
四个。一些规则
1。在设计系统时,需要不断提出要求,然后修改系统的定义。以这种方式进行迭代,以使系统功能强大且易于使用。
2。 网站只有用户知道页面和用户需求之间的映射,而不是程序。该程序只需要提供一个渠道,用户就可以通过该渠道将自己的需求告知该程序。有效地使用网站创造者和用户的智慧比程序本身的智慧要简单得多。
3。好的设计源于模仿现实。尽管本文没有讨论数据存储和重组,但在实现数据时必须考虑它。用户需求的复杂性还导致数据存储和重新安排的复杂性。
4。 采集该系统是一种将Internet信息结构映射到用户需求的工具。
5。永远期待。还要考虑XML。

