免规则采集器列表算法(怼正则,怼CSS选择器,解析是个麻烦事(组图))
优采云 发布时间: 2021-12-02 06:27免规则采集器列表算法(怼正则,怼CSS选择器,解析是个麻烦事(组图))
爬虫有什么作用?它可以帮助我们快速获取有效信息。但是,任何做过爬虫的人都知道解析是一件麻烦事。
比如一篇新闻文章,链接是这样的:,页面预览如下:
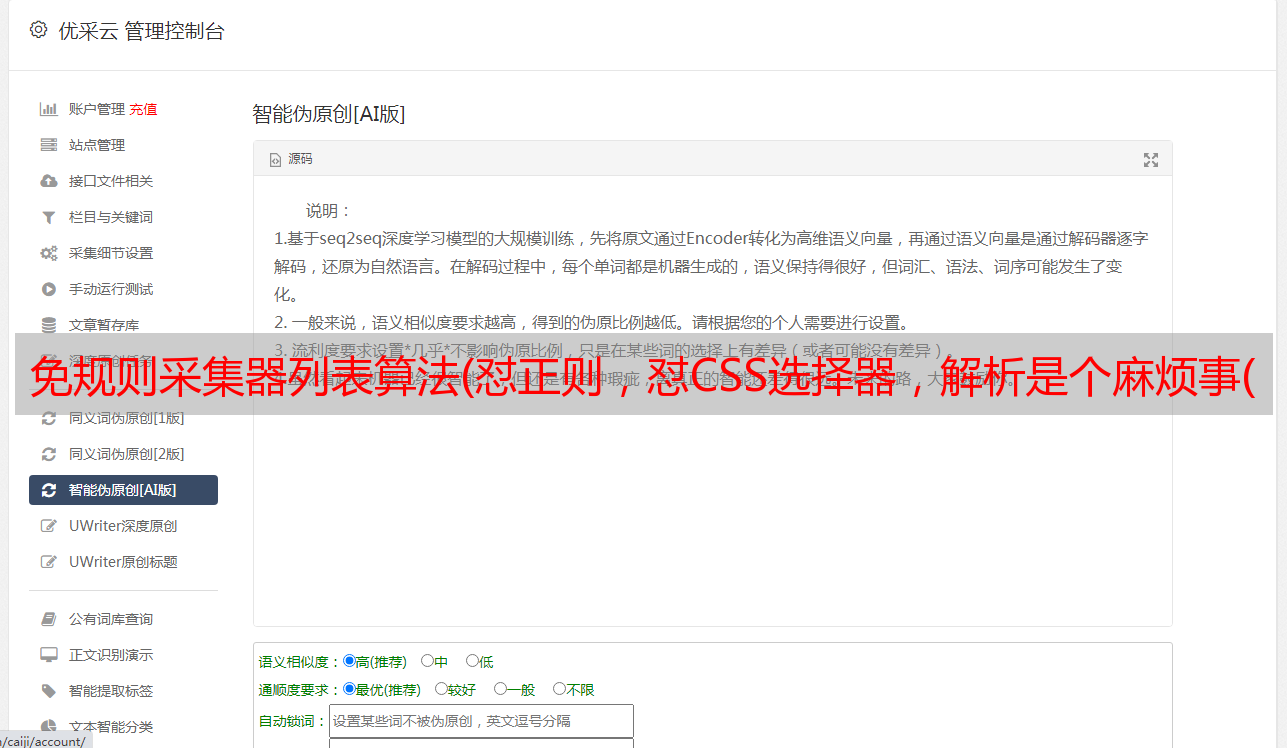
预览
我们需要从页面中提取标题、出版商、发布时间、发布内容、图片等内容。正常情况下我们需要做什么?写规则。
那么规则是什么?怼Regular,怼CSS选择器,怼XPath。我们需要匹配标题的内容,发布时间,来源等,更重要的是,我们需要正则表达式来辅助。我们可能需要使用 re、BeautifulSoup 和 pyquery 等库来提取和解析内容。
但是如果我们有数千个不同风格的页面怎么办?它们来自数千个站点。我们还需要写规则来一一匹配吗?这需要多少工作。另外,如果这些事情没有做好,分析就会出现问题。例如,在某些情况下无法匹配正则表达式,如果 CSS 和 XPath 选择器选择错误,则可能会出现问题。
想必大家可能已经看到现在的浏览器都有阅读模式,比如我们用Safari浏览器打开这个页面,然后打开阅读模式看看效果:
Safari 预览
页面突然变得很清爽,只保留了标题和需要阅读的内容。原页面多余的导航栏、侧边栏、评论等全部删除。它是如何做到的?有人可以在里面写规则吗?当然这是不可能的。其实这里用的是智能分析。
那么在这篇文章中,我们一起来看看智能页面分析的相关知识。
智能分析
所谓爬虫智能分析,顾名思义,就是我们不再需要为某些页面编写抽取规则。我们可以使用一些算法来计算页面上特定元素的位置和提取路径。比如一个页面中的一篇文章文章,我们可以通过算法计算,它的标题应该是什么,文本的哪一部分应该在区域内,发布时间是多少等等。
事实上,智能解析是一项非常艰巨的任务。比如你在网页上给某人看一个文章,人们很快就能知道这个文章的标题是什么,发布时间是什么时候。哪一部分是文字,或者哪一部分是广告位,哪一部分是导航栏。但如果机器要识别,它面对的是什么?它只是一系列 HTML 代码。那么机器是如何实现智能提取的呢?事实上,它收录了许多方面的信息。
还有一些功能就不一一赘述了。这些包括区块位置、区块大小、区块标签、区块内容、区块密度等,在很多情况下,你需要使用由于视觉的特性,它实际上是算法计算、视觉处理、自然语言的组合加工等方面。如果能综合利用这些特性,再通过大量的数据训练,就能得到非常好的效果。
行业进展
未来页面会越来越多,页面的渲染方式也会发生很大的变化,爬虫越来越难做,智能爬虫越来越重要。
目前,业界已经有实现的算法。经过一番研究,我发现有几种算法或服务可以更好地进行智能页面分析:
那么这些算法或服务中哪些是好的?Driffbot 官方做了对比评测,使用了部分谷歌新闻文章,使用不同的算法依次提取标题和文本,然后与实际标注的内容进行对比。对于比较,比较的指标是文本的准确率和召回率,以及基于两者计算的F1分数。
结果比较如下:
服务/软件
精确
记起
F1-Score
Diffbot
0.968
0.978
0.971
锅炉管
0.893
0.924
0.893
可读性
0.819
0.911
0.854
炼金术API
0.876
0.892
0.850
嵌入
0.786
0.880
0.822
鹅
0.498
0.815
0.608
经过对比,我们可以发现Diffbot的准确率和召回率都名列前茅,它的F1值达到了0.97,可以说是非常高了。此外,下一个更强大的是 Boilerpipe 和 Readability。Goose 的性能很差,F1 和其他算法有很大的不同。以下是几种算法的F1分数对比:
F1成绩对比
可能有人会好奇Diffbot为什么这么强大?我也查过。Diffbot 从 2010 年就开始致力于网页数据的提取,并提供了很多 API 来自动解析各种页面。其中,他们的算法依赖于自然语言技术、机器学习、计算机视觉、标记检查等各种算法,所有页面都会考虑当前页面风格和视觉布局,还会分析图像内容, CSS 甚至其中收录的内容。Ajax 请求。另*敏*感*词*的标记计算每个块的置信度。
总之,Diffbot也一直致力于这方面的服务。整个Diffbot从页面解析开始,现在一直专注于页面解析服务。准确率高也就不足为奇了。
但是他们的算法是开源的吗?不幸的是,没有,我也没有找到相关的论文来介绍他们自己的具体算法。
所以,如果你想达到这么好的效果,就用他们的服务吧。
在下面的内容中,我们将讨论如何使用 Diffbot 进行智能页面分析。此外,Readability算法也值得研究。我会专门写一篇文章来介绍可读性以及它与Python的联系。
Diffbot 页面分析
首先,我们需要注册一个帐户。它有 15 天的免费试用期。注册后,您将获得一个Developer Token,这是使用Diffbot 接口服务的凭证。
接下来切换到它的测试页面,链接是:我们来测试一下它的解析效果。
我们这里选择的测试页面就是上面提到的页面,链接是:,API类型选择Article API,然后点击Test Drive按钮,就会显示当前页面的分析结果:
结果
这时候我们可以看到它帮助我们提取了标题、发布时间、发布机构、发布机构链接、正文内容等结果。到目前为止,它看起来非常正确。时间自动识别并转码,这是一种标准的时间格式。
接下来我们继续向下滚动以查看还有哪些其他字段。这里我们也可以看到,有一个html字段,它和text的区别在于它收录了文章的内容的真实HTML代码,所以图片中也会收录Inside,如图:
结果
此外,最后还有图像字段。他以列表的形式返回了文章的图片集和每张图片的链接,以及文章的站点名称、页面使用的语言等,如图图。展示:
结果
当然,我们也可以选择以JSON格式返回结果,这样内容会更加丰富。比如图片还返回了它的宽、高、图片描述等,还有各种其他的比如面包屑导航等结果,如图:
结果
经过人工检查,发现返回的结果完全正确,准确率相当高!
所以,如果你对精度要求不是那么严格,使用Diffbot的服务可以帮助我们快速从页面中提取出需要的结果,节省了我们大部分的体力劳动,可以说是太棒了。
但是,我们不能总是在网络上尝试这个。其实Diffbot也提供了官方的API文档,让我们一探究竟。
Diffbot API
Driffbot 提供了多种 API,例如分析 API、文章 API、讨论 API 等。
我们以Article API为例来说明它的用法。官方文档地址为:,API调用地址为:
我们可以使用 GET 方法来发出请求。Token 和 URL 都可以以参数的形式传递给这个 API。必要的参数是:
此外,它还有几个可选参数:
这里大家可能比较关心的是fields字段,这里我专门做了一个梳理,首先是一些固定的字段:
以上预定的字段是可以返回的字段。它们不能被定制和配置。此外,我们还可以通过 fields 参数指定和扩展以下可选字段:
好了,以上就是这个API的用法了。申请后可以使用该API进行智能分析。
我们以一个例子来看看这个API的用法,代码如下:
import requests, json
url = 'https://api.diffbot.com/v3/article'
params = {
'token': '77b41f6fbb24495113d52836528fa',
'url': 'https://news.ifeng.com/c/7kQcQG2peWU',
'fields': 'meta'
}
response = requests.get(url, params=params)
print(json.dumps(response.json(), indent=2, ensure_ascii=False))
这里先定义API链接,然后指定params参数,也就是GET请求参数。
参数包括必填token和url字段,还设置了可选字段,其中fields是可选的扩展字段meta标签。
我们来看看运行的结果,结果如下:
{
"request": {
"pageUrl": "https://news.ifeng.com/c/7kQcQG2peWU",
"api": "article",
"fields": "sentiment, meta",
"version": 3
},
"objects": [
{
"date": "Wed, 20 Feb 2019 02:26:00 GMT",
"images": [
{
"naturalHeight": 460,
"width": 640,
"diffbotUri": "image|3|-1139316034",
"url": "http://e0.ifengimg.com/02/2019/0219/1731DC8A29EB2219C7F2773CF9CF319B3503D0A1_size382_w690_h460.png",
"naturalWidth": 690,
"primary": true,
"height": 426
},
// ...
],
"author": "中国新闻网",
"estimatedDate": "Wed, 20 Feb 2019 06:47:52 GMT",
"diffbotUri": "article|3|1591137208",
"siteName": "ifeng.com",
"type": "article",
"title": "故宫,你低调点!故宫:不,实力已不允许我继续低调",
"breadcrumb": [
{
"link": "https://news.ifeng.com/",
"name": "资讯"
},
{
"link": "https://news.ifeng.com/shanklist/3-35197-/",
"name": "大陆"
}
],
"humanLanguage": "zh",
"meta": {
"og": {
"og:time ": "2019-02-20 02:26:00",
"og:image": "https://e0.ifengimg.com/02/2019/0219/1731DC8A29EB2219C7F2773CF9CF319B3503D0A1_size382_w690_h460.png",
"og:category ": "凤凰资讯",
"og: webtype": "news",
"og:title": "故宫,你低调点!故宫:不,实力已不允许我继续低调",
"og:url": "https://news.ifeng.com/c/7kQcQG2peWU",
"og:description": " “我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。” “重"
},
"referrer": "always",
"description": " “我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。” “重",
"keywords": "故宫 紫禁城 故宫博物院 灯光 元宵节 博物馆 一票难求 元之 中新社 午门 杜洋 藏品 文化 皇帝 清明上河图 元宵 千里江山图卷 中英北京条约 中法北京条约 天津条约",
"title": "故宫,你低调点!故宫:不,实力已不允许我继续低调_凤凰资讯"
},
"authorUrl": "https://feng.ifeng.com/author/308904",
"pageUrl": "https://news.ifeng.com/c/7kQcQG2peWU",
"html": "<p>“我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。... ",
"text": "“我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。”\n“...",
"authors": [
{
"name": "中国新闻网",
"link": "https://feng.ifeng.com/author/308904"
}
]
}
]
}
可以看出它返回了上面的内容,是一个完整的JSON格式,里面收录了title,body,发布时间等各种内容。
可以看出,我们不需要配置任何提取规则,不费吹灰之力就可以完成对页面的分析和抓取。
Diffbot SDK
此外,Diffbot 还提供几乎所有语言的 SDK 支持。我们也可以使用SDK来实现以上功能。链接是:如果使用Python,可以直接使用Python SDK。Python SDK 链接是:。
该库尚未发布到 PyPi。您需要自己下载并导入。另外,这个库是用Python 2编写的,其实本质上就是调用requests库。有兴趣的可以去看看。
下面是一个调用的例子:
from client import DiffbotClient,DiffbotCrawl
diffbot = DiffbotClient()
token = 'your_token'
url = 'http://shichuan.github.io/javascript-patterns/'
api = 'article'
response = diffbot.request(url, token, api)
有了这行代码,我们就可以通过调用Article API来分析我们想要的URL链接,返回的结果也差不多。
具体用法直接看它的源码注释就可以一目了然了,还是很清晰的。
好了,以上就是对页面智能提取原理的基本介绍,以及Diffbot的使用说明。后面我会继续介绍其他智能分析方法和一些相关的实战。我希望你能多加注意。

