采集规则 采集 data-src(织梦采集侠如何提高搜索引擎排名自动标题、段落重排、高级混淆 )
优采云 发布时间: 2021-12-01 14:04采集规则 采集 data-src(织梦采集侠如何提高搜索引擎排名自动标题、段落重排、高级混淆
)
织梦采集Xia是一款后台数据采集工具,可以为用户提供一个自动采集数据平台,自动采集无需管理是一个站长实时操作的必备工具,无需一直盯着程序。用户在使用该程序时,只需在采集参数和其他采集信息输入程序中,系统会根据用户的设置进行工作,并可以快速采集并添加到指定网站中的数据;支持文章自动采集,同时为用户提供无限域名使用功能,该功能主要是为了让用户更好的避免采集数量有限的尴尬;强大实用,有需要的用户可以下载体验
软件功能
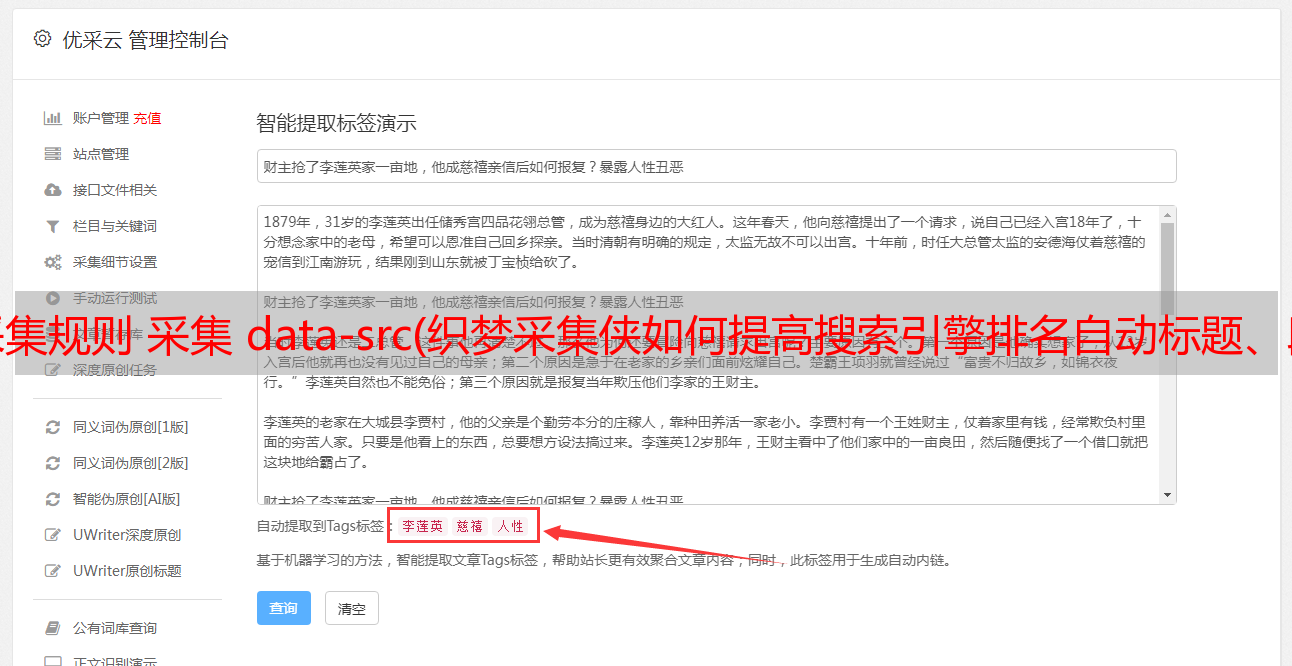
1、有针对性的采集,精确的采集标题、正文、作者、来源
Orientation采集 只需要提供列表URL和文章URL即可智能采集指定网站或列内容,方便简单,写简单的规则即可准确采集标题、正文、作者、来源。
2、 多种伪原创和优化方法来提高收录率和排名
自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、插入seo词、关键词添加链接等方法让采集回来文章处理,提升采集文章原创性能,有利于搜索引擎优化,提升搜索引擎收录、网站权重和关键词排名.
3、插件全自动采集无需人工干预
织梦采集 侠是预先设定的任务采集,根据设定的采集方法采集 URL,然后自动抓取内容网页,程序通过精确计算分析网页,丢弃不是文章内容页的URL,提取文章的优秀内容,最后执行伪原创,导入,生成,所有这些操作程序都是自动完成的,无需人工干预。
软件功能
1、一键安装,全自动采集
织梦采集 下安装非常简单方便。只需一分钟即刻上手采集,结合简单、健壮、灵活、开源的dedecms程序,新手也能快速上手,我们还有专门的客服提供为商业客户提供技术支持。
2、采集这个词,不用写采集规则
与传统的采集模式不同的是,织梦采集可以进行平移采集,平移采集@根据设置的关键词用户>的好处是通过采集和关键词的不同搜索结果,可以在一个或几个指定的采集站点上不执行采集,减少< @采集 网站被搜索引擎判断为镜像站点被搜索引擎惩罚的危险。
3、RSS采集,输入RSS地址为采集内容
只要RSS订阅地址是采集的网站提供的,就可以使用RSS进行采集,只需要输入RSS地址即可轻松采集到目标网站内容,无需写采集规则,方便简单。
破解说明
织梦采集侠采集有两个版本,UTF8和GBK。根据你使用的dedecms版本选择!
因为文件是mac系统打包的,所以会携带_MACOSX和.DS_Store文件,不影响使用,有强迫症的可以删除。覆盖破解文件时不要在意这些文件。
1、你去官方采集xia官方下载最新的v2.8版本,然后安装到你的织梦后台,如果你已经安装了2.第7版之前,请先删除!
2.安装时注意不要选错版本,UTF8安装UTF8,GBK不要混装GBK!
3、覆盖破解文件(彩机侠、include和Plugins共三个文件)
Plugins:直接覆盖到网站的根目录
include:直接覆盖到网站的根目录
CaiJiXia:网站默认后台是dede。如果不修改后端目录,它会覆盖/dede/apps/。如果后端访问路径被修改,则将 dede 替换为您修改的名称。例子:dede已经修改为test,然后覆盖/test/apps/目录
4、破解程序的使用对域名没有限制
5、覆盖后需要清理浏览器缓存。建议使用 Google 或 Firefox。不要使用IE内核浏览器。清理缓存有时可能不干净。
6、PHP 版本必须5.3+
使用说明
1、设置方向采集
1),登录你的网站后台,模块->采集侠->采集任务,如果你的网站还没有添加栏目,你需要先在织梦的栏目管理中添加一个栏目。如果已经添加了列,可能会看到如下界面
2),在弹出的页面中选择方向采集,
3),点击添加采集规则,这是添加针对性采集规则的页面,这里要详细说一下
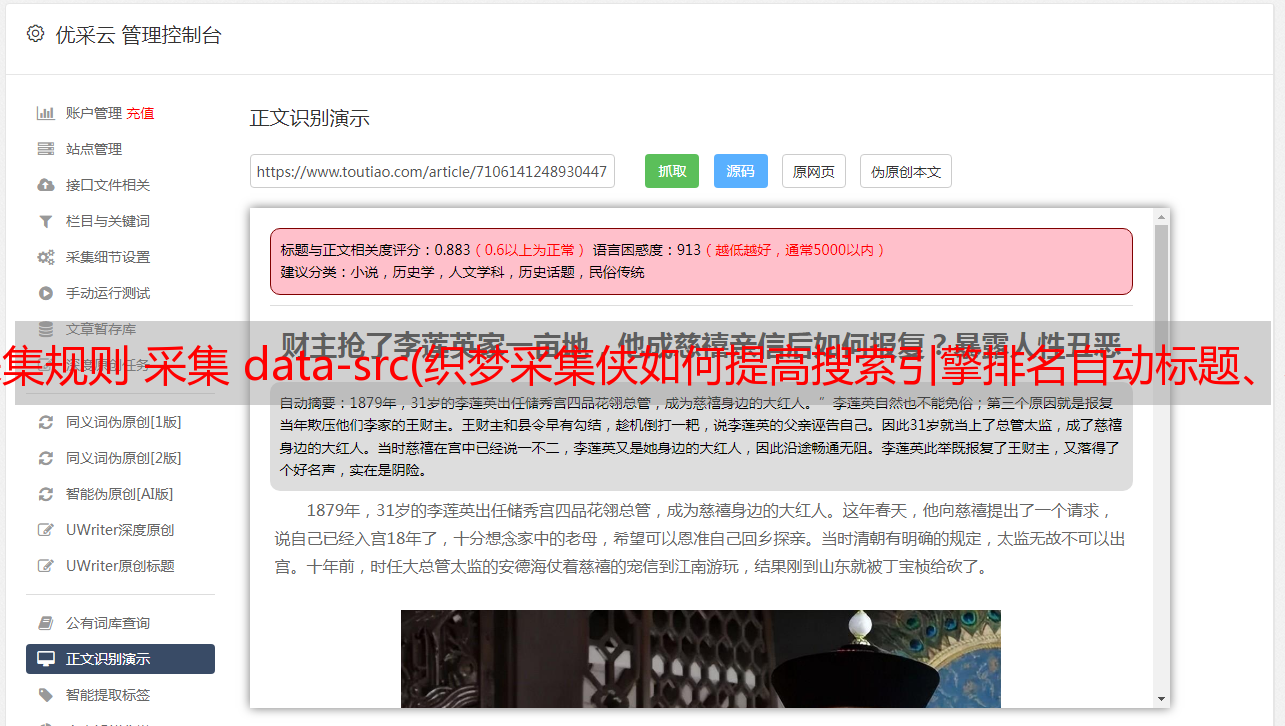
2、设置目标页面编码
打开你要采集的网页,点击鼠标右键,点击查看网站的源码,搜索charset,查看charset后面是utf-8还是gb2312,如图,是utf -8
3、设置列表网址
list URL是你要采集的网站的列列表地址
如果只是采集列表页面的第一页,直接输入列表URL即可。如果我想要采集站长之家优化版块的第一页,那么输入列表网址:是的。 采集第一页内容的好处是不需要采集旧新闻,如果有新的更新也可以采集及时到达,如果需要到采集该列的所有项内容,也可以通过设置通配符匹配所有列表URL规则
.
超级采集
原理:使用采集爬虫模式互相网站层层爬取,获取所有符合规则的内容页面
适用对象:采集的内容没有时序要求,使用采集需要大量的内容!
目标页面编码:>gb2312 >utf8列表url:采集列列表,通配符[起始编号-结束编号],如[1-10]文章url:在列表中文章地址,支持url模糊匹配(*)和区域匹配【规则说明】:查找字段内容所在的区域,“开始html片段[内容]结束html片段”,如标题规则:
程序的功能模块如下