不用采集规则就可以采集(《网络神采》入门采集示例(二):软件优势)
优采云 发布时间: 2021-11-27 12:22不用采集规则就可以采集(《网络神采》入门采集示例(二):软件优势)
《网络奇迹》是一款轻量级的采集软件,用于快速采集下载网页数据。该软件快速、易于使用且免费。支持智能采集(无需匹配规则),可视化采集(无需看源文件),支持二次开发,分布式部署。为用户的大数据分析和信息平台提供稳定、持续、准确的数据资源。
软件优势
1、采集 实力
支持JS解析、POST分页、登录采集、跨层采集。对于困难的采集页面,有成熟的解决方案。
2、速度快
支持多任务同时运行,每个任务可设置多线程,保证运行效率。
3、缩放
支持任务的多级分类和批量管理。支持云服务器分布式部署和管理员团队协作。
4、处理
支持定时采集,任务会定时自动启动。通过二次开发,实现流程信息采集和信息处理。
5、 稳定运行
系统运行稳定,要求“0 bug”。登陆页面修改后,会自动通知管理员。
6、准确度
自定义任务后,采集的准确率可以达到100%,也就是一个不漏。
软件特点
A. 一般:通过自定义采集规则,你可以采集任何你可以通过浏览器看到的东西。
B、灵活:支持网站登录采集、网站跨层采集、POST采集、脚本采集、动态页面采集@ >如此高级的功能。
C. 扩展性强:支持存储过程、插件等,可以通过二次开发扩展功能。
D. 高效:为了节省您做其他事情的时间,该软件经过精心设计。
E、速度快:最快最高效的采集软件。
F.稳定性:系统资源占用少,操作日志详细,采集性能稳定,软件要求“零BUG”。
G. 人性化:我们时刻关注细节,及时为您提供全方位的服务。
使用教程
光荣网络:入门采集示例
新闻采集是最常用也最容易理解的。我们以一个简单的新闻 采集 任务为例进行入门。任务有两个层次:“新闻列表”和“新闻内容”。我们以新闻列表作为“起始地址”,然后通过“导航规则”从“新闻列表”中提取“新闻内容”的URL,最后按照“采集规则”采集 需要的内容。
1、创建任务
在网络神彩软件主窗口中,点击菜单“任务”->“新建”,打开“任务编辑”对话框,创建任务。下面我们通过图文混合的方式来讨论如何一步步填写设置:
第 1 步:任务概述
在“任务概览”中,我们只需要填写一个任务名称:郑州大学新闻资讯。其他设置暂不讨论,请熟练后参考我们的帮助文件。
第 2 步:起始地址
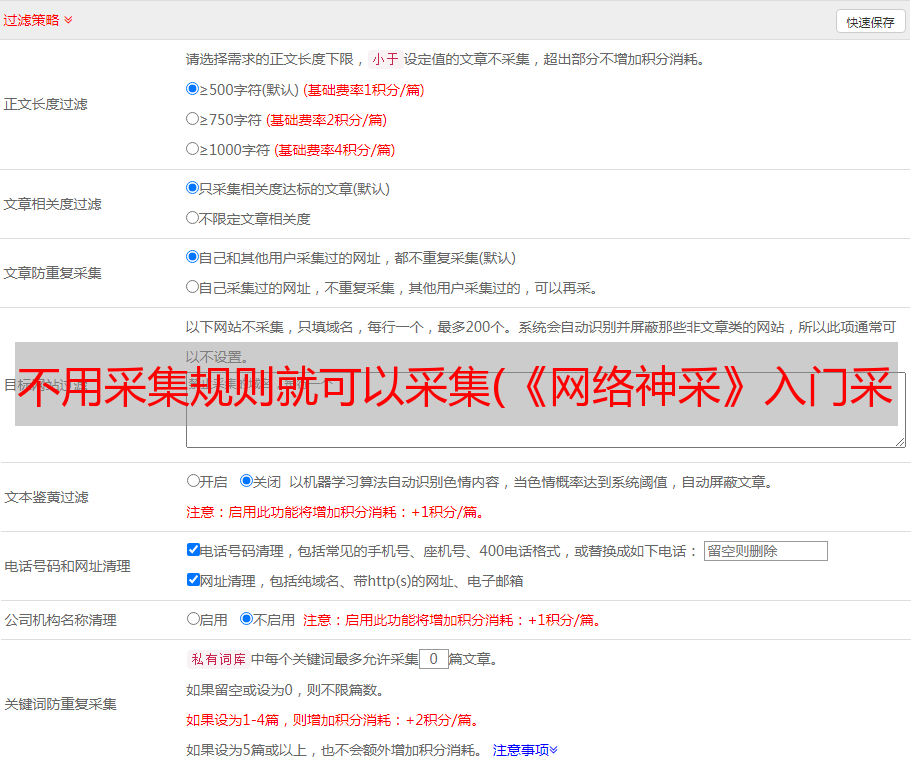
起始地址是我们要采集的内容的入口地址,这里是“新闻列表”:{1,100}。其中,“pn”是分页变量的名称,在浏览“新闻列表”时翻页观察即可获得。如果“pn=1”表示第一页,“pn=2”表示第二页,以此类推。我们为“pn”指定一个变量值:{1,100},这意味着将有采集1到100页。这种分页变量格式由我们的软件定义。您可以通过单击“插入”按钮插入预设的分页变量。
第 3 步:导航规则
因为这个任务有两个层次,所以需要构建两个“导航规则”,分别命名为“新闻列表”和“新闻内容”。我们需要从“新闻列表”中提取“新闻内容”的URL来实现导航。因此,将“新闻列表”设置为“中间层”并填写“下一层URL模板”以提取URL。对于“新闻内容”,只需选择“最后一页”并保存即可。
如何确定“新闻列表”的“下一级网址模板”?请看下面的图片。
通过查看“新闻列表”的源文件,我们可以找到“新闻内容”的URL,以*敏*感*词*显示。我们将URL的可变部分替换为“*”(通配符),即“下一级URL模板”,即:*。这样,我们提取的时候就有了一个依据:只提取与模板匹配的网址,其他网址跳过。
“导航规则”的最终设置如下:
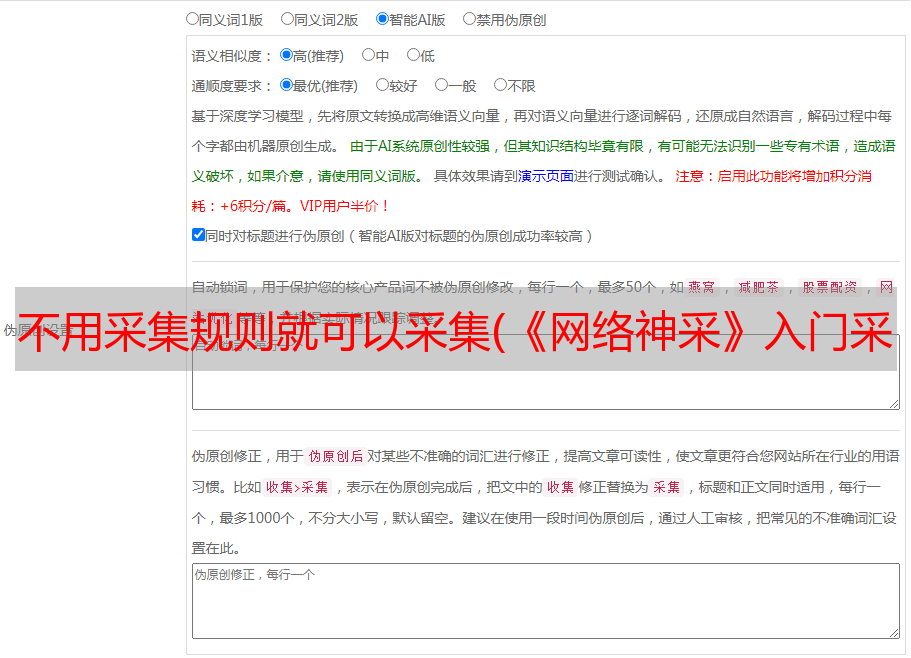
第 4 步:采集 规则
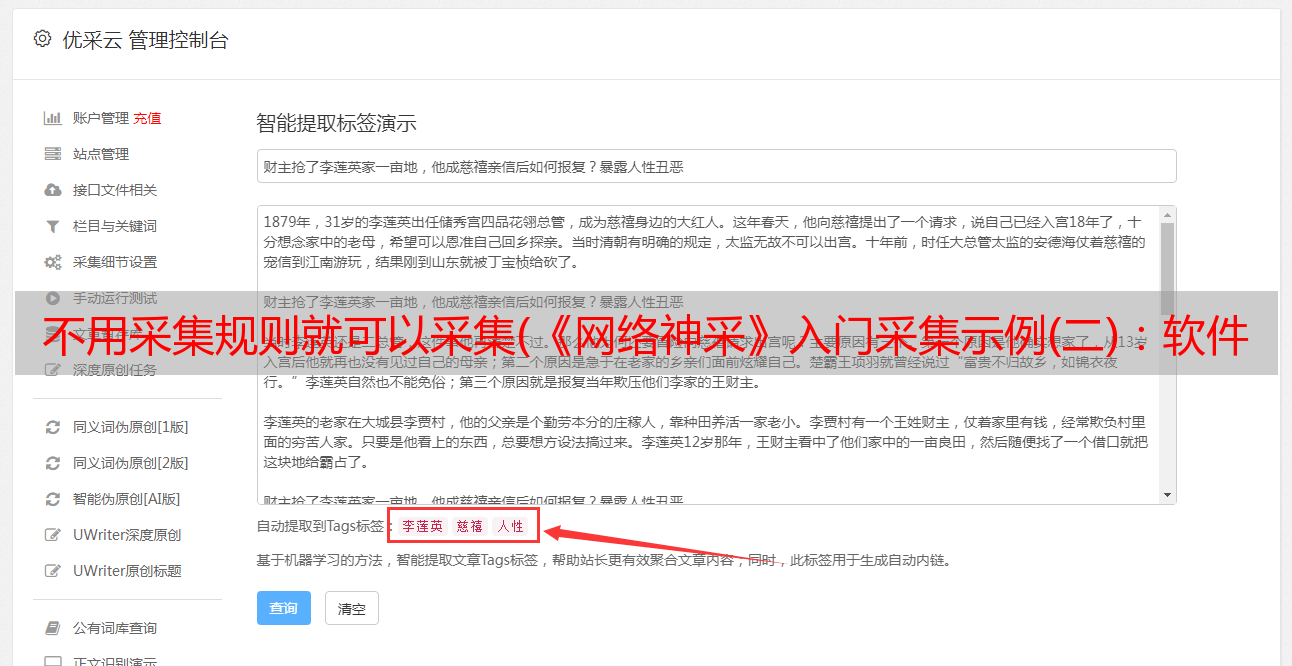
通过“导航规则”我们一路到了“最后一页”,也就是“新闻内容”,接下来我们需要按照“采集规则”采集要求的内容进行操作。如上图所示,一个“采集规则”对应一个数据库字段,是一种信息类型,如标题、出版商、贡献者、内容等。“数据库字段”可以留空,默认值为规则名称。“归属层”是一个跨层的采集函数,本例中不使用,保持默认即可。
以下是最重要的:“前信息标记”和“后信息标记”。软件通过搜索源文件中的“Before and After Mark”定位信息为采集。那么如何获取信息的前后标识呢?请看下面的图片。
如图,“红色部分”代表信息的正面标志,“*敏*感*词*部分”是背面标志。夹在中间的“蓝色部分”就是我们需要的采集。顺序为:“标题”、“出版商”、“贡献者”、“出版日期”、“阅读次数”、“内容”。
“采集Rule”的最终设置如下:
注意:
1、如果使用“Before and After Logo”采集 信息,则必须与“网页源文件”中出现的顺序相同。
2、应用“采集规则”后,“采集Content”的结尾将被视为“当前位置”,然后下一个“采集从“当前位置”搜索“规则”的“前置信息标志”。
3、如果选择了“全局规则”和“静态规则”,它们将不再受“当前位置”的影响。
第 5 步:采集 结果
如图,这里我们不做任何设置,直接在采集之后导出结果即可。
更新日志2019-08-13 V6.3.15 Visualization 采集配置,放大或缩小时:
1、 提取下一个网址:默认为连续*号,按Ctrl键为单个*号
2、循环采集:按下Shift键,支持连续*
3、 有多个*号时,高亮
可视化采集配置,操作详情:
1、显示完整的XPath:选中后不会取消当前元素,而是直接切换
2、 废除选项:复制XPath时覆盖现有内容,改为:复制XPath时,按Shift键覆盖现有内容
3、Gecko内核:改回xulrunner_60.0.26,低版本xulrunner_45.0.34 还是会出现COM断线,体验太差
修复错误:
1、Loop采集:整个数据或“关键规则”采集失败后,多次回收URL
2、切换动态图层:从当前图层切换到动态图层时,如果动态图层使用了“模拟点击”,但是当前图层没有使用,会导致“提取下一层时出错” XPath:未将对象引用设置为对象的实例”。2019-07-31 V6.3.14 改进细节:
1、 回收URL后,输出日志,方便查看。
2、如果动作失败,任务挂起,URL和采集内容将不再提取。2019-07-27 V6.3.13
新增功能:动态图层
1、 支持解决验证码识别、表单输入等技术问题。
2、重构面板:扩展脚本->扩展脚本和动态层
3、 导航规则,添加选项:DynamicLayerFlag
重构插件接口(IBget 5.2):
1、添加插件接口:使用插件设置输入参数(扩展脚本)
2、用于配合扩展脚本和动态层增加插件与浏览器内核的交互。
编辑评论
网络神彩是一款轻量级数据采集软件,该软件无需安装,解压后即可使用,免费版,无时间限制,可用于快速采集,下载网页数据,并支持网站登录采集、网站跨层采集、POST采集、脚本采集、动态页面采集等先进功能是目前互联网上速度最快、效率最高的采集软件。全新的网络精神全面优化升级。速度快,好用,免费,支持智能采集(无匹配规则),可视化采集(不看源码),支持二次开发,分布式部署可以提供稳定,为用户提供持续准确的数据资源 大数据分析与信息平台。欢迎免费下载体验。

