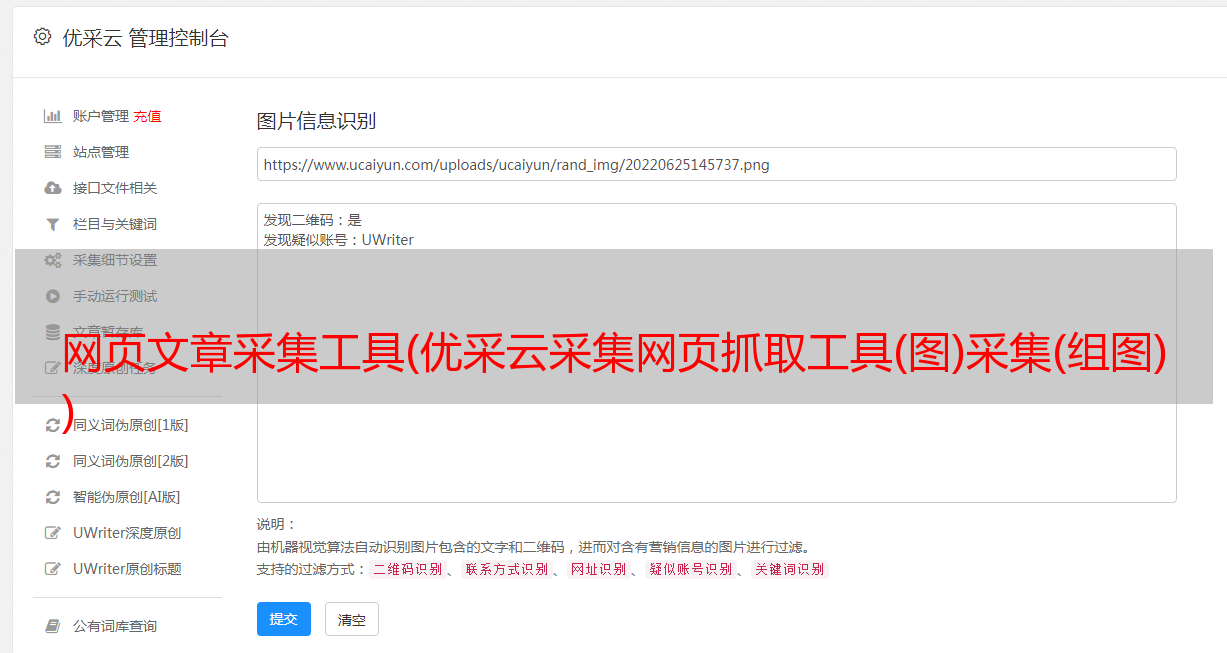
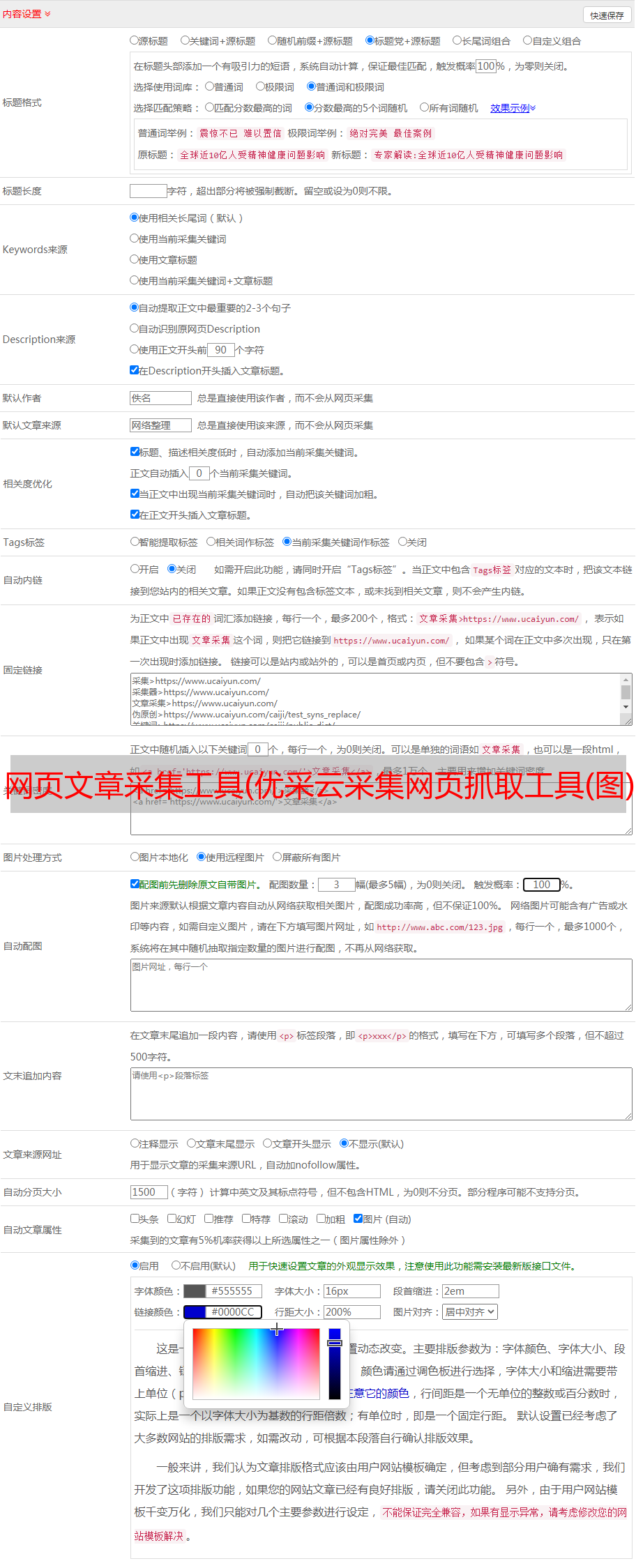
网页文章采集工具(优采云采集网页抓取工具(图)采集(组图) )
优采云 发布时间: 2021-11-14 20:14网页文章采集工具(优采云采集网页抓取工具(图)采集(组图)
)
以官网上的采集网页爬虫工具优采云采集器 faq为例,说明采集器采集的原理和流程。
本例以demo地址和优采云采集器V9为工具来说明。
(1)创建一个新的采集规则
选中一个组,右击,选择“新建任务”,如下图:
解析URL变量规律(2)添加起始URL
这里我们需要采集 5页数据。
第一页地址:
第二页地址:
第三页地址:
由此我们可以推断出p=后面的数字是分页的意思,我们用[地址参数]来表示:
所以设置如下:
数字变化:从1开始,即第一页;每增加1,即每页变化的次数;一共5条,也就是一共采集5页。地址格式:用[地址参数]表示改变的页码。
预览:采集器会根据上面的设置生成一部分URL,让你判断添加的是否正确。
然后确认
(3)【普通模式】获取内容URL
普通模式:该模式默认抓取一级地址,即从起始页的源码中获取到内容页A的链接。
下面给大家介绍一下如何自动获取地址链接+设置区域。
查看页面源码,找到文章地址所在的区域:
注:更详细的分析说明请参考本手册:设置如下:
操作指南> 软件操作> URL 采集规则> 获取内容URL
点击网址采集测试查看测试结果
(3)Content采集以URL为例说明标签采集
注:更详细的分析说明,可在官网下载并参考用户手册。
操作指南>软件操作>内容采集规则>标签编辑
我们首先查看它的页面源码,找到我们的“title”所在的代码:
导入Excle弹出对话框~打开Excle时出错-优采云采集器帮助中心
分析结果:开头的字符串为:
结束字符串是:
数据处理-内容替换/排除:需要替换-优采云采集器帮助中心清空
分析结果:开头的字符串为:
设置内容标签的原理类似,在源码中找到内容的位置
结束字符串是:
数据处理-HTML标签排除:过滤不需要的A链接等。
设置另一个“源”字段