抓取网页生成电子书( 谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
优采云 发布时间: 2021-10-26 23:05抓取网页生成电子书(
谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
Google 抓取工具如何抓取 JavaScript 内容
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = "nofollow" 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,测试 B 使用它。相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向操作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
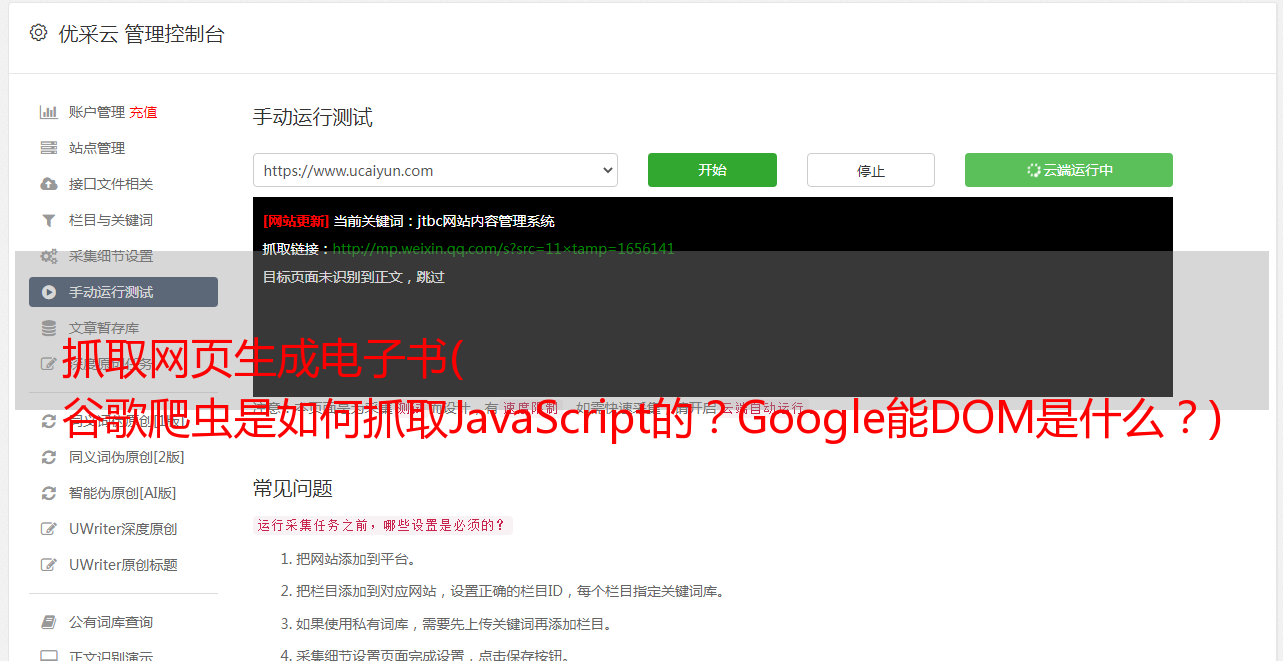
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内(“onClick”)
使用 href 内部 AVP("javascript: window.location")
在 a 标签之外执行,但在 href 中调用 AVP("javascript: openlink()")
还有很多
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序函数(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,DOM中没有index,follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试 Google 如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:谷歌在执行添加 rel="nofollow" 的 JavaScript 函数之前准备抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入内容,甚至元标记,例如rel规范注释,无论是在HTML源代码中还是在解析初始HTML后触发JavaScript生成DOM都以相同的方式处理。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。太不可思议了!(请记住允许 Google 爬虫获取这些外部文件和 JavaScript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们需要更好地支持 HTML5、JavaScript 和动态网站。
对于SEO来说,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。
时间:2017-04-04
Java爬虫抓取信息的实现
今天公司有需求,需要在指定网站查询后做一些数据抓取,所以花了一段时间写了一个demo来演示使用。思路很简单:就是通过Java访问链接,然后得到html字符串,然后解析链接需要的数据。从技术上讲,Jsoup 是用来方便页面解析的。当然,Jsoup 是非常方便和简单的。一行代码就知道怎么用了: Document doc = Jsoup.connect("") .data("query", "Java") //
Python3实现javascript动态生成html网页抓取功能示例
本文以Python3实现javascript动态生成的html网页抓取功能为例。分享给大家参考,如下: 使用urllib等抓取网页,只能读取网页的静态源文件,无法通过javascript生成 原因是urllib是瞬间抓取的,不会等待加载javascript的延迟,因此页面中javascript生成的内容无法被urllib读取。那么javascript生成的内容真的是看不懂了你拿了吗?不!这里有一个python库:selenium,本文使用的版本是2.4
Python爬虫实现爬取京东店铺信息和下载图片功能示例
本文介绍了Python爬虫实现爬取京东店铺信息和下载图片的功能。分享出来供大家参考,如下:这是来自bs4 import BeautifulSoup import requests url ='+%C9%D5%CB% AE&type=p&vmarket=&spm=875.7931836%2FA.a2227oh.d100&from=mal
Python多线程爬取天涯帖子内容示例
使用re、urllib、threading多线程抓取天涯帖子的内容,url设置为待抓取的天涯帖子的第一页,file_name设置为下载的文件名。复制代码如下:#coding:utf-8 import urllibimport reimport threadingimport os, time class Down_Tianya(threading.Thread): """多线程下载""" def __init__(sel
Nodejs抓取html页面内容(推荐)
废话不多说,我直接贴出node.js的核心代码来抓取html页面的内容。具体代码如下: var http = require("http"); var iconv = require('iconv-lite'); var option = {hostname: "", path: "/gszl/s601398.shtml" }; var req = http.request(option,
Thinkphp 捕获网站 的内容并保存到本地实例。
thinkphp 抓取网站 的内容并保存到本地。我需要写一个例子从电子教科书网络下载电子书。电子教科书网的电子书把书的每一页都当作一个图片,然后一本书有很多图片,我需要批量下载图片。下面是代码部分: public function download() {$http = new \Org\Net\Http(); $url_pref = "" ; $localUrl =
Python基于BeautifulSoup实现抓取网页指定内容的方法
本文介绍了python如何基于BeautifulSoup抓取网页指定内容的示例。分享出来供大家参考。具体实现方法如下: # _*_ coding:utf-8 _*_ #xiaohei.python.seo.call.me :) #win+python2.7.x import urllib2 from bs4 导入 BeautifulSoup def jd(url): page = urllib2.urlopen(url) html_doc = page.read() 汤 = B
Winform实现抓取网页内容的方法
本文用一个非常简单的例子来描述Winform是如何实现爬取网页内容的。代码简单易懂,非常实用!分享出来供大家参考。具体实现代码如下: WebRequest request = WebRequest.Create("" + PageUrl ); WebResponse 响应 = request.GetResponse(); 流 resStream = response.GetRespo
Python多进程爬取基金网站内容的方法分析
本文以Python多进程方式捕获基金内容的例子网站。分享出来供大家参考,如下:在之前的文章///article/162418.htm中,我们已经简单了解了“Python的多进程”,*敏*感*词*的内容< @网站(28 页)作为多进程方法。因为流程不是越多越好,我们打算分成三个流程。意思是:将要捕获的总共28页分成三部分。如何划分?# 初始范围 r = range(1,29) # 步长 step = 10 myList = [r[x:

