网页数据抓取(1.获取百度()数据第一步,要爬取网页?)
优采云 发布时间: 2021-10-22 05:09网页数据抓取(1.获取百度()数据第一步,要爬取网页?)
上节课我们讲了爬取数据的三个步骤:获取数据、解析数据、保存数据。
这节课我们讲如何获取网页数据。我们从一个简单的例子开始,并将其映射到我们正在做的项目中。
1.获取百度(
)数据
第一步是爬网,我们先导入模块
urllib.request
第二步,通过模块
在 urllib.request 下
urlopen 打开网页
第三步,通过read()方法读取数据
第四步,通过decode()方法对数据进行解码,得到网页的源码
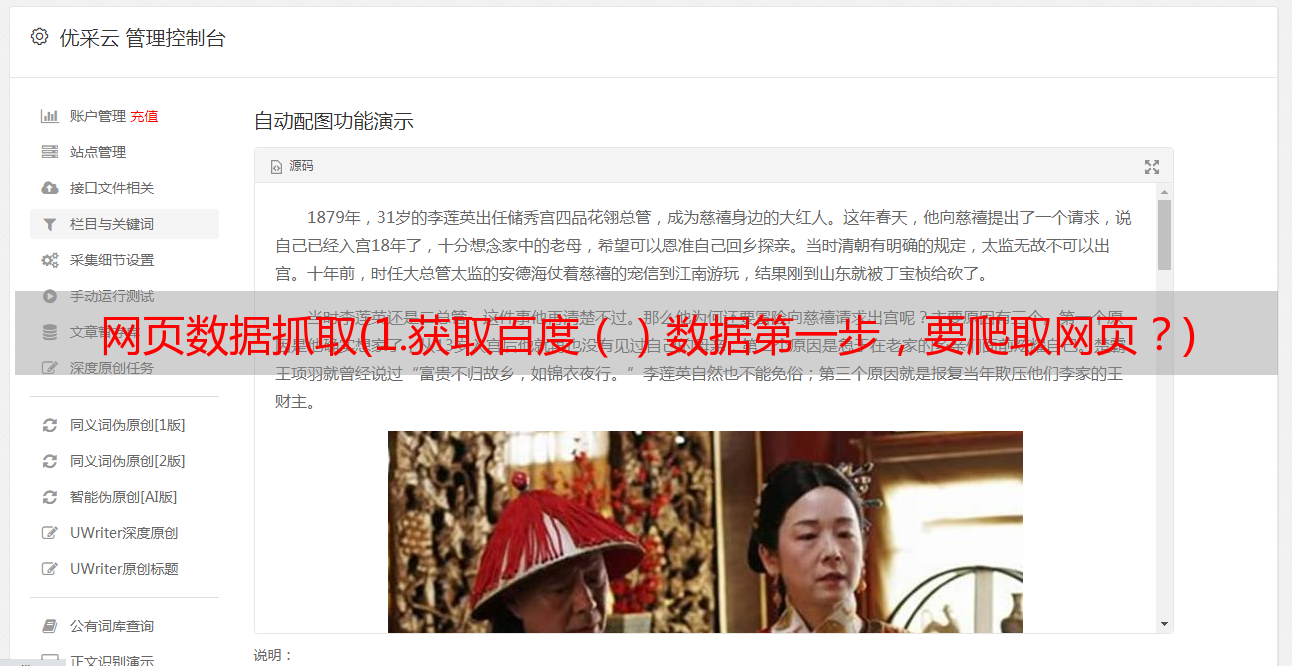
2.
得到豆瓣(
)数据
第一步是导入模块urllib.request
第二步是对URL进行封装,因为有些网站有爬虫机制可以避免被爬取,所以我们需要对URL进行处理。处理方法是使用urllib.request下的Request方法
第三步,
通过urllib.request模块下的urlopen打开网页
第三步和第四步,通过read()方法读取数据
第五步,通过decode()方法对数据进行解码,得到网页的源码
3.注意:
urllib.request下封装URL的Request方法需要两个参数:data和headers
headers数据可以通过显示网页代码-network-headers-user-agent获取
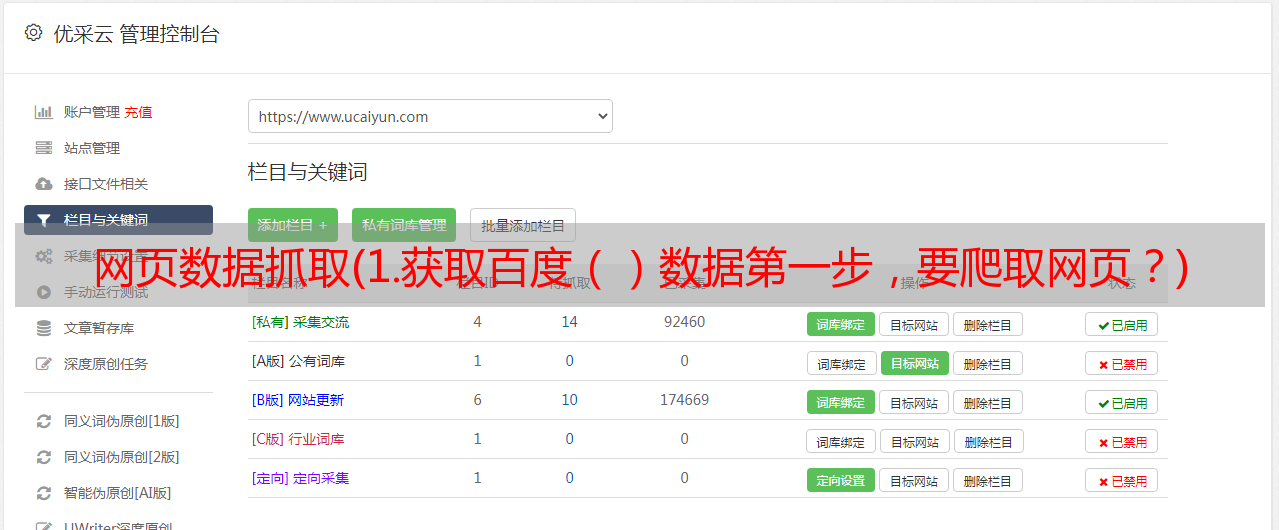
对于数据和ssl数据,直接按照上图写代码就可以了。

