搜索引擎优化知识完(SEO知识点:如何解读日常所接触到的SEO报告?)
优采云 发布时间: 2021-10-20 18:17搜索引擎优化知识完(SEO知识点:如何解读日常所接触到的SEO报告?)
说起搜索引擎优化(SEO),大家一定耳熟能详。SEO 是我们熟悉的第一个数字营销概念之一。酒店营销部或数字营销负责人也会每月或每季度收到总部的SEO报告;那为什么要用“陌生”来形容呢?
正是因为从业以来,笔者发现大部分酒店营销部门或数字营销主管只了解一些SEO的概念和术语,但是搜索引擎是如何工作的,他们每天遇到的SEO报告如何解读,以及如何发现问题。如何优化有很多盲点,没有办法根据酒店自身情况制定SEO策略。
所以从今天开始,笔者将用一系列文章,力争为大家整理出SEO知识点。希望大家看完文章系列后,能得到一些启发,更好地服务自己工作的酒店。.
作为第一篇文章,我们先来了解一些基本的内容。你有没有想过以下问题:
带着这些问题,让我们一起√获取今天的知识吧!
知识点一:什么是SEO?我们如何定义它?
SEO的全称是“Search Engine Optimization”,中文翻译为“搜索引擎优化”。
知识点2:为什么要做SEO?
网站 业主都希望自己的网站 流量尽可能大。不管网站的盈利模式和目标是什么,有人来访是前提。SEO 是将访问者带到 网站 的最佳方式。一起来看看SEO的“优势”:
知识点3:移动互联网时代还需要做SEO吗?
让我们看看一些行业调查数据,看看SEO是否仍然有效?
数据摘自《2017年中国互联网发展统计报告》
知识点4:搜索引擎是如何工作的?
面对海量信息,搜索引擎如何在一秒或更短的时间内返回我们想要的内容?要回答这个问题,需要分解搜索引擎的工作原理,大致可以分为三个阶段:
先看第一阶段,即“爬行爬行”
对于搜索引擎来说,首要任务是完成对互联网网页数据的采集。用于数据采集的工具就是我们经常听到的“蜘蛛”。它是搜索引擎用来抓取和访问页面的程序。蜘蛛发送页面访问请求后,服务器返回HTML代码,蜘蛛将接收到的代码存储到数据库中。蜘蛛会跟随链接,根据一页上的链接爬(读)到下一个,这就是为什么它被称为“蜘蛛”。
在数据采集过程中,为了提高效率,避免重复阅读网页数据,搜索引擎会建立一个地址库来记录“已读”和“已发现但未读”的页面。构建原创页面数据库来存储读取的页面数据。
阅读结束,建立原创数据库后,搜索引擎将进行第二阶段的任务——“预处理”。什么是“预处理”?原创数据库中有数以万亿计的网页数据。排名程序无法每时每刻分析如此海量的数据,也无法在1-2秒内返回搜索结果。因此,必须对这些数据进行处理,为最终的排名程序调用做准备。
预处理的第一步是过滤数据,去除无用信息,提取文本。如今,搜索引擎仍然基于文本内容。除了我们在网页上看到的文字外,数据库中的页面数据还收录不能用于排名的内容,例如HTML标签和JavaScript程序。程序需要去除这些无用信息并提取可用于排名的内容。除了文本之外,程序还会提取一些收录文本信息的特殊代码,例如Meta标签中的文本、图片的替代文本、Flash文件的替代文本、链接锚文本等。
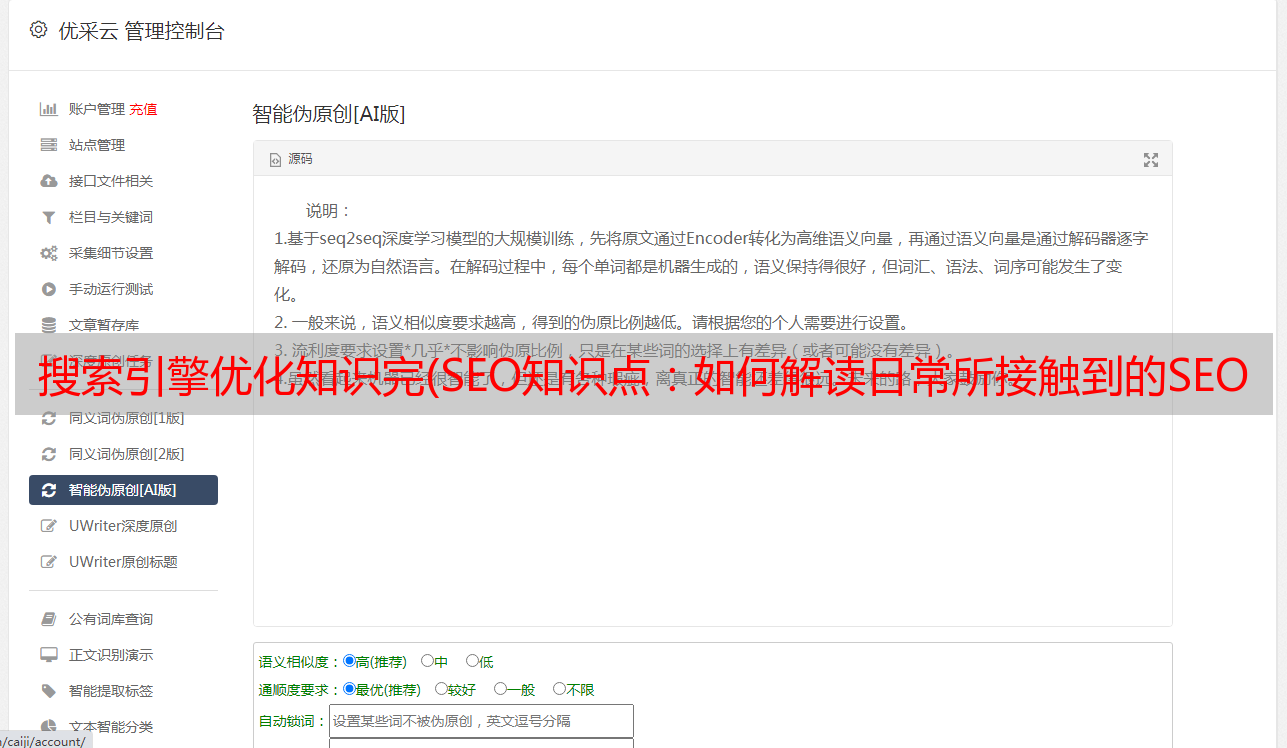
之后,我们需要介绍一点知识,就是中文搜索引擎的独特步骤——“中文分词”。“字”是程序处理数据和用户查询的单位和依据。与英语不同,搜索引擎必须区分用户搜索的中文内容中的哪些字符构成一个词,然后才能进行下一步。
在分词之后,程序还需要执行另一个步骤,即消除“停用词”。在任何语言中,都有出现频率高但对内容影响不大的词汇,如汉语中的“的”、“啊”、“缺”等;"the" "a" "and" "to" "of" in English "等等。这些被称为“停用词”。程序去掉这些停用词,使搜索内容更加突出,减少程序计算的内部消耗.
此外,程序会删除对搜索无用的内容,例如版权声明文本和导航栏文本,以消除噪音。
紧接着,该程序还将对网页数据进行重复数据删除。相同的内容可能会在多个网站中重复发布。为了避免向支持者返回多个重复内容,需要提前消除重复内容。
完成以上操作后,程序会得到“独特的、反映页面主题的、词汇方面的”内容,随后程序会被索引向前。通过提取关键词,将内容转化为“关键词的单位”的集合,以及关键词@的频率、格式(粗体、粗体锚文本)、位置(标题、页面) > 同时记录段落开头、段落结尾)等属性。然后将其转化为如下结构并存入数据库:
“正向索引”后的数据不能直接排序,因为同一个关键词可能出现在多个文件中,于是聪明的程序员发明了“倒排索引”,将文件重构为倒排索引。行索引:
既然搜索引擎已经做好随时处理用户搜索请求的准备,接下来就是搜索引擎第三阶段的任务,即排名。
每当搜索引擎收到用户搜索到的内容时,它会这样处理:
经过上面的处理和匹配,程序会在倒排索引数据库中找到一组与搜索内容关键词匹配的文件。例如,如果搜索内容包括“关键词1”“关键词2”,排名程序只需要查找收录这2个关键词的文件,即“文件2”和“文件 3”。
你可能会问,成功匹配的文件肯定有几千万。搜索引擎会对它们进行排名吗?答案是否定的。由于数量庞大,搜索引擎程序不会处理这些庞大的数据,只会对页面数据中最重要的部分进行排名。此外,用户通常只查看搜索结果的前两页,因此搜索引擎不需要太麻烦地对所有数据进行排名。所以,如何对“页面数据中最重要的部分”进行排名,就要靠它自己的算法——相关性计算的帮助,它计算某个页面数据与用户搜索内容之间的相关性来完成排名。
至此,搜索引擎已经基本完成了用户的“搜索请求”,但按照2/8规则,大约20%的搜索内容约占总搜索次数的80%。搜索引擎会缓存常用词的排名和数据,用户搜索时会直接调用缓存的数据,从而减少一系列庞大且耗能的步骤,缩短反馈时间,提升用户体验。

