分享的内容:采集文章内容
优采云 发布时间: 2020-12-15 12:09分享的内容:采集文章内容
新闻库中的
采集文章内容是全自动的采集
系统带有新闻库,该库可以自动同步实时新闻库文章中的更新。购买许可证后需要使用此功能。如果您不购买许可证,建议您编写自己的采集规则以继续采集。
如图所示,打开站点列表中的自动填充文章开关以自动填充网站文章(打开该开关后,系统可能需要花费几个小时来准备,请稍等文章自动填充。是)
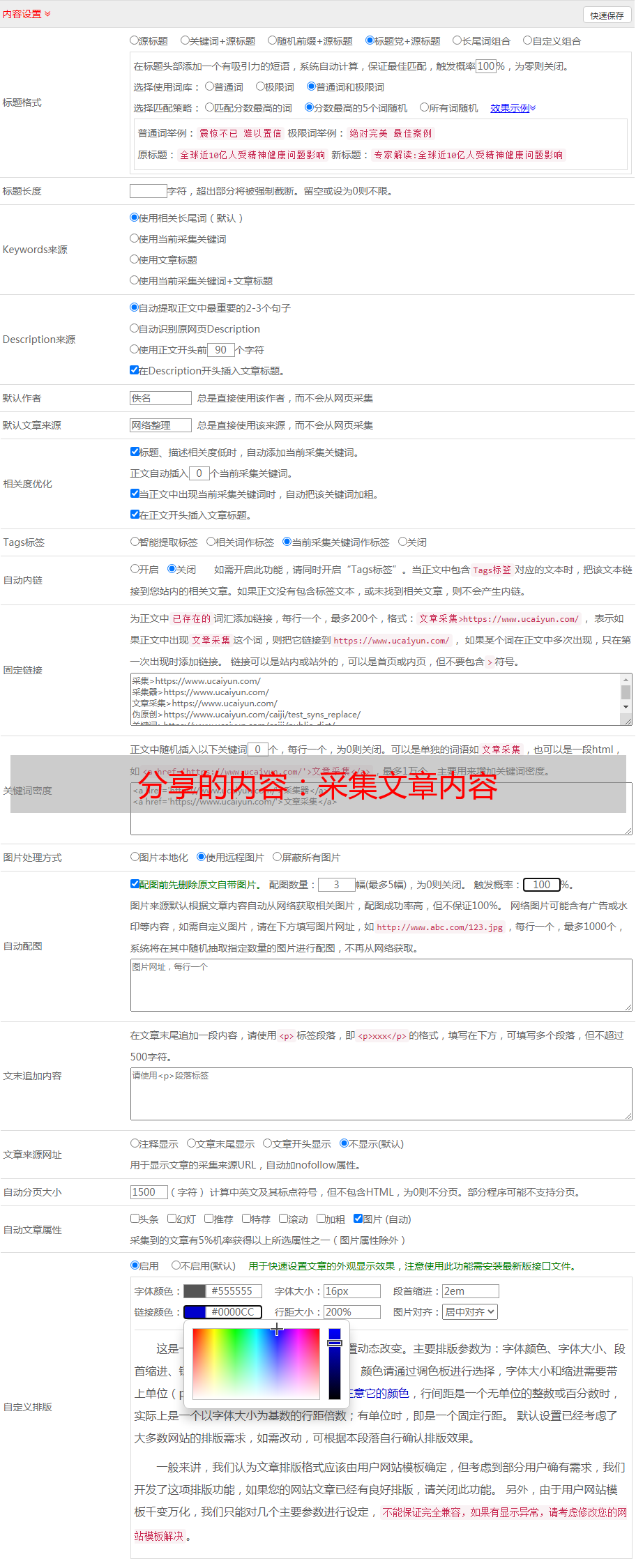
(图片可以点击放大)
编写您自己的采集规则采集
前序:
采集规则编写对入门有一定难度,只要多尝试上手了后期使用起来会很方便,对今后使用其他采集软件也是多多受益
域名构建系统采集工具位于内容管理的网站背景中,单击“内容管理” >>“ 采集管理” >>“添加采集规则”以输入
设置采集列表网址
列表URL是您要采集的网站的列列表地址
如果只是采集列表页面的第一页,只需直接输入列表的URL。 采集第一页上的内容的优点是您不需要采集旧新闻,并且可以使用新的更新。 采集准时到达。如果需要采集该列的所有内容,则还可以通过设置通配符来匹配所有列表URL规则。
匹配URL规则的方法也非常简单。您只需要检查列表页面的差异并添加通配符即可。以人民网技术频道为例:
第一页的网址是:
第二页的URL是:
第三页的URL是:
通过观察列表URL的变化,我们可以看到第一页是index1.shtml,第二页是index2.shtml,第三页是index3.shtml。更改后的页码仅是列表。该页面的URL通配符为[起始页面-结束页面]。如果要在采集列中当前显示10页,则列表URL规则为:[1-10] .html。如果您发现差异,则可以从起始页到结束页更改将通配符添加到零件。
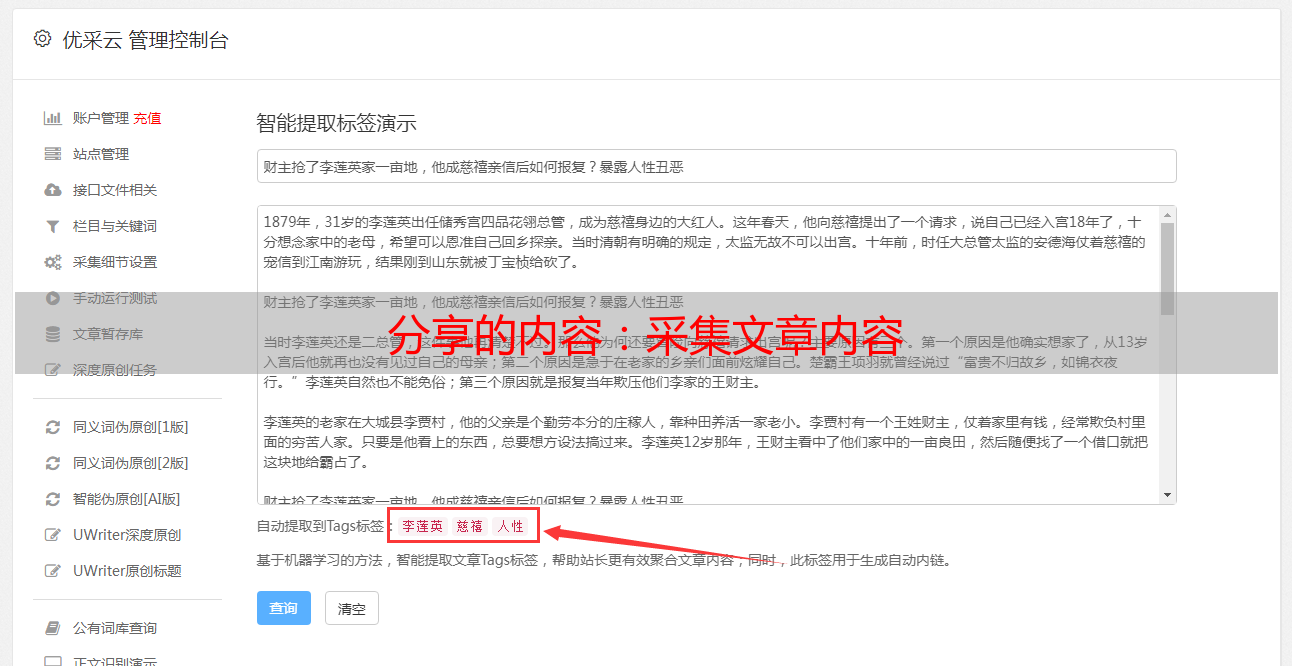
设置文章 URL区域
上面我们已经为采集设置了网站列表URL,但是打开此URL页面时有很多内容,并且程序无法知道采集的文章 URL是什么,因此我们需要在这里设置一个区域规则来告诉它。
如图所示,红色框是我们想要的文章 采集
(图片可以点击放大)
如何编写此规则,编写一个规则以告诉它文章 URL的起始位置和结束位置,最后编写代码,其中该规则是[content]结束的代码
例如,让我们打开上面的人们网络技术渠道列表的第一页:
打开后,右键单击以查看源代码,并通过查看源代码找到我们想要的文章 URL的区域
(图片可以点击放大)
最后,我们在制定规则前后发现了一段独特的代码,即
[内容]
设置标题规则
标题规则类似于文章 URL区域规则。打开列表中的所有文章文章,并检查源代码以在页面上找到标题
例如文章 URL :,源代码截图如下
(图片可以点击放大)
将标题前后的唯一代码变成规则,
[内容]--科技--人民网
设置正文规则
在上面的页面上,找到文本所在的区域,并在文本前后找到唯一的代码以制定规则
如图所示
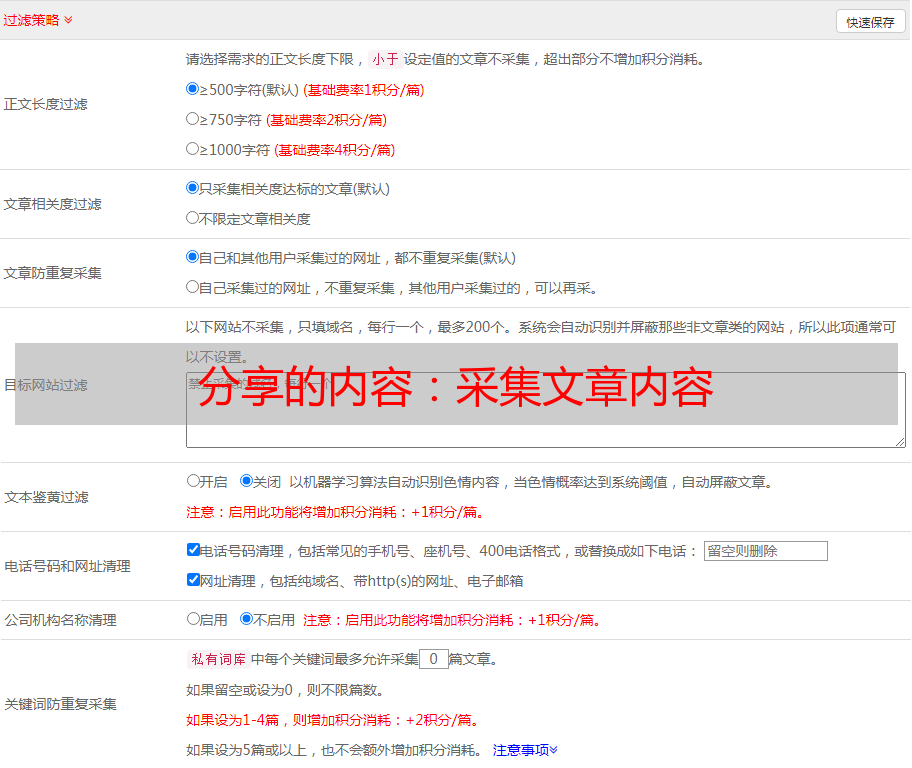
(图片可以点击放大)
最终规则可以写为
[内容]
最后单击测试,如果测试成功,则单击保存采集

