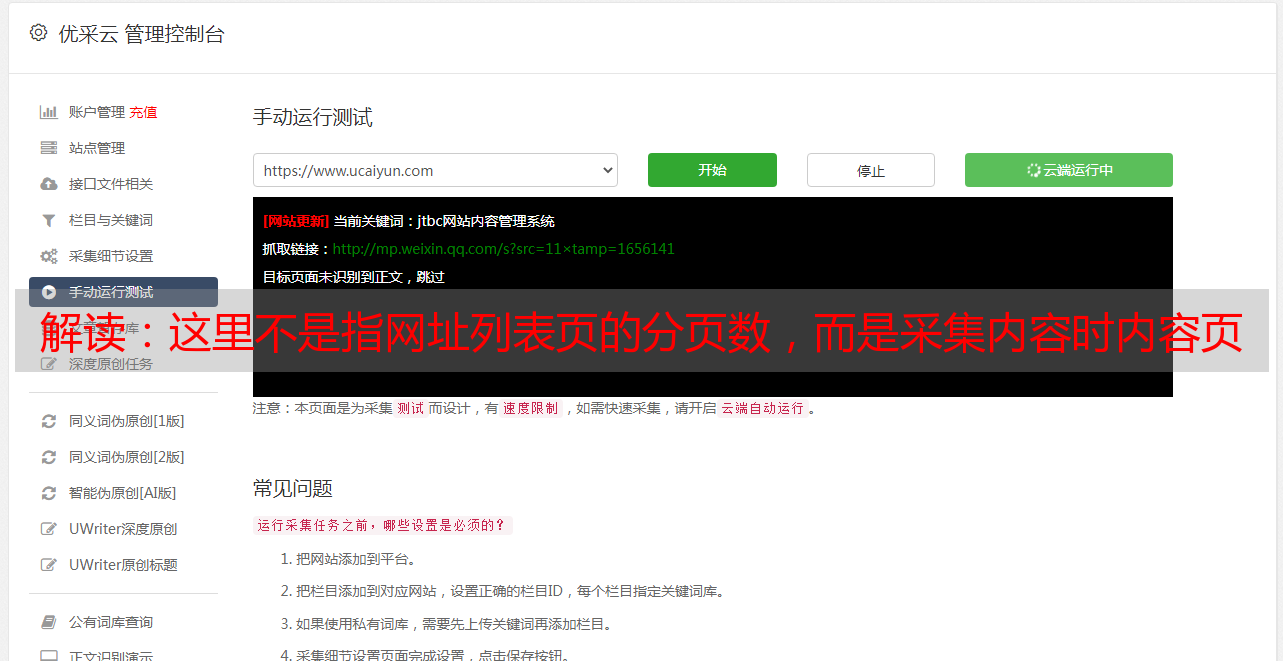
解读:这里不是指网址列表页的分页数,而是采集内容时内容页的分页数。
优采云 发布时间: 2020-12-15 10:21解释:这并不是指URL列表页面的页数,而是当使用采集的内容时内容页面的页数。
系统全局设置
a。同时运行的最大任务数
可以同时运行的任务数(站点下的任务)。默认设置为3,这意味着可以同时运行三个任务。每个任务可以设置为采集个不同的站点以发布到不同的站点。
b。默认采集最大页数
这里不是指URL列表页面的页数,而是采集内容时的内容页面的页数。
c。请求超时并放弃(秒)
请求网页30秒(默认设置为30秒)时,如果请求失败,请放弃请求该网页并开始请求下一个网页。提取URL和提取内容均有效。
d。保存辅助URL时过滤重复的URL
从URL列表页面提取内容页面地址时,如果提取重复的内容页面地址,则可以选择过滤掉重复的内容页面地址。
e。是否忽略大小写
您可以在采集内容标签的正则表达式中选择是否忽略大小写。
f。任务完成后退出运行界面
每个任务采集都有一个进度为采集的任务窗口。默认情况下,完成任务采集后,采集窗口仍显示在软件界面中。您可以选择在任务采集完成后自动关闭任务采集的进度窗口。
g任务正在运行,并停止播放声音提示
您可以选择是否在任务采集完成后播放声音提示。
任务采集发布
a。循环采集时用于合并内容的间隔符
在采集的内容页面中,当使用循环采集时,您可以根据需要设置循环采集和数据之间的分隔符。例如,在采集个论坛帖子中,您可以对每个回复的内容使用循环采集。这些答复的内容由循环采集获得。可以在此处设置回复和回复之间的分隔符。
b。另存为TXT文件时删除HTML标签
您可以选择在发布数据并将数据保存到本地TXT文本时是否删除数据中的HTML标签。
c。模拟客户浏览/搜索引擎爬网(发布时未启用此配置)
采集器默认情况下使用用户的本地浏览器访问采集时,可以模拟百度蜘蛛,谷歌蜘蛛和雅虎蜘蛛。
d。本机浏览器用户代理
这可以获取本地浏览器的User-Agent,或设置其他User-Agent。
e。自动转换为拼音选项
将中文从采集设置为拼音时所扮演的角色。默认设置是整个单词的拼音,也可以设置为仅获取第一个字母。全字符拼音是为了将每个汉字完全转换成拼音;将每个汉字转换成拼音后,仅获取第一个字母就是保留拼音的第一个字母。
f。拼音大小写选项
将汉字从采集转换为拼音时,可以将拼音的首字母设置为大写,全部大写和小写。
g拼音最大长度
是拼音字母的数量。当拼音字母的数量超过设置的数量时,多余的单词将被切断。
h。连续重复采集个后,跳过采集网址
采集器在采集和网站相关内容中运行任务时,首先获取内容页面的地址(称为:选择URL),然后将获取的地址保存到任务站点的数据库中(任务所在的站点),当所有内容页面地址均已获取后,它将开始根据内容页面地址逐个采集内容。运行任务时,必须首先采集内容页面地址。当采集到达某个地址并发现采集器在站点数据库中具有该地址时,它将检测到该地址已经存在(默认设置是检测重复的地址,也可以设置为不检测)。 k2]发现已经存在10个连续的采集地址(默认设置为10,您可以根据需要对其进行修改),它将停止采集内容页面地址开始采集内容步骤。
i。中文URL服务器编码设置
采集器使用采集 URL时,可以先编码URL,然后再进入采集 URL。您可以选择多种编码方法。通常,当网站收录汉字时,有些人需要以某种方式对网站进行编码采集。
j。对于不符合标签内容收录条件的商品
在采集的内容中,可以设置采集的数据是否满足条件,例如,它必须收录某个单词,并且不能收录某个单词。当不满足设置条件时,可以选择是直接删除不合格数据还是将其设置为未采集状态。

